EmoReg: Directional Latent Vector Modeling for Emotional Intensity Regularization in Diffusion-based Voice Conversion
作者: Ashishkumar Gudmalwar, Ishan D. Biyani, Nirmesh Shah, Pankaj Wasnik, Rajiv Ratn Shah
分类: eess.AS, cs.AI, cs.MM, cs.SD
发布日期: 2024-12-29
备注: Accepted to AAAI 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
EmoReg:提出基于扩散模型的定向潜在向量建模的情感强度可控语音转换方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 情感语音转换 扩散模型 情感强度正则化 定向潜在向量建模 自监督学习 语音合成 语音质量
📋 核心要点
- 现有情感语音转换方法在控制情感强度时存在风格操控不当和语音质量下降的问题。
- EmoReg利用自监督学习特征和无监督定向潜在向量建模,在扩散模型中调节情感嵌入,从而控制情感强度。
- 实验结果表明,EmoReg在英语和印地语上均优于现有方法,实现了高质量的情感强度正则化。
📝 摘要(中文)
本文提出了一种基于扩散模型的情感语音转换(EVC)框架,旨在对情感强度进行正则化,从而生成具有精确目标情感的语音。传统方法通常通过情感类别概率或强度标签来控制情感强度,但这往往导致风格操控不当和质量下降。相反,我们旨在利用自监督学习的特征表示和无监督的定向潜在向量建模(DVM)来调节情感强度。这些情感嵌入可以根据给定的目标情感强度和相应的方向向量进行修改。此外,更新后的嵌入可以融合到反向扩散过程中,以生成具有所需情感和强度的语音。总而言之,本文旨在实现基于扩散模型的EVC框架中的高质量情感强度正则化,这是同类研究中的首创。实验结果表明,该方法在英语和印地语的语音转换任务中,通过主观和客观评估,均优于最先进的基线方法。
🔬 方法详解
问题定义:情感语音转换(EVC)旨在将给定语音的情感从源情感转换为目标情感,同时保留语言内容。现有方法在控制情感强度时,通常依赖情感类别概率或强度标签,但这些方法往往导致不自然的风格转换和语音质量下降,难以精确控制情感强度。
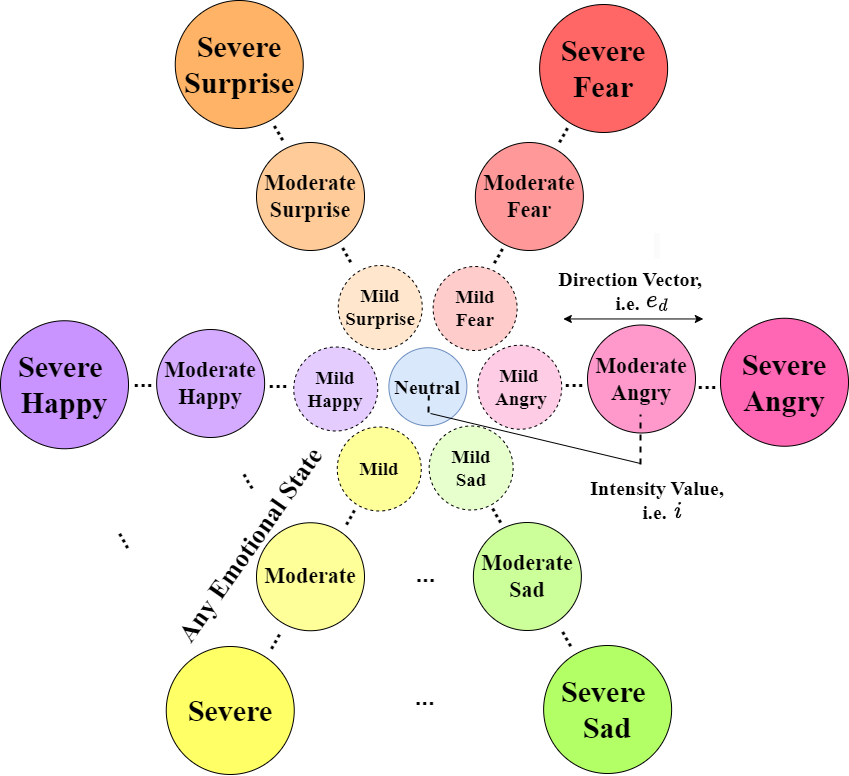
核心思路:EmoReg的核心思路是利用自监督学习得到的特征表示,并在扩散模型的框架下,通过无监督的定向潜在向量建模(DVM)来调节情感嵌入。通过修改情感嵌入,并将其融合到反向扩散过程中,从而生成具有目标情感和强度的语音。这种方法避免了直接操作情感类别概率或强度标签,从而更自然地控制情感强度。
技术框架:EmoReg基于扩散模型,主要包含以下几个阶段:1) 使用自监督学习模型提取语音的特征表示;2) 在情感嵌入空间中,使用无监督的DVM方法学习情感方向向量;3) 根据目标情感强度和方向向量,修改情感嵌入;4) 将修改后的情感嵌入融合到反向扩散过程中,生成目标语音。
关键创新:EmoReg的关键创新在于使用定向潜在向量建模(DVM)来控制情感强度。与传统方法直接操作情感类别概率或强度标签不同,DVM通过学习情感嵌入空间中的方向向量,从而更自然、更精确地控制情感强度。此外,将DVM与扩散模型相结合,也为情感语音转换提供了一种新的思路。
关键设计:EmoReg的关键设计包括:1) 使用自监督学习模型(例如wav2vec 2.0)提取高质量的语音特征表示;2) 使用余弦相似度等方法计算情感嵌入空间中的方向向量;3) 设计合适的融合机制,将修改后的情感嵌入融合到反向扩散过程中;4) 损失函数的设计需要考虑语音质量、情感相似度和情感强度的准确性。
🖼️ 关键图片


📊 实验亮点
EmoReg在英语和印地语数据集上进行了评估,实验结果表明,EmoReg在主观听觉测试和客观指标上均优于现有的基线方法。具体而言,EmoReg在情感相似度和语音质量方面均取得了显著的提升,证明了其在情感强度正则化方面的有效性。论文提供了在线demo,方便用户体验。
🎯 应用场景
EmoReg在情感语音合成、个性化语音助手、游戏角色配音等领域具有广泛的应用前景。它可以用于生成具有不同情感色彩的语音,从而增强人机交互的自然性和表现力。此外,EmoReg还可以用于语音治疗和情感识别等领域,帮助人们更好地理解和表达情感。
📄 摘要(原文)
The Emotional Voice Conversion (EVC) aims to convert the discrete emotional state from the source emotion to the target for a given speech utterance while preserving linguistic content. In this paper, we propose regularizing emotion intensity in the diffusion-based EVC framework to generate precise speech of the target emotion. Traditional approaches control the intensity of an emotional state in the utterance via emotion class probabilities or intensity labels that often lead to inept style manipulations and degradations in quality. On the contrary, we aim to regulate emotion intensity using self-supervised learning-based feature representations and unsupervised directional latent vector modeling (DVM) in the emotional embedding space within a diffusion-based framework. These emotion embeddings can be modified based on the given target emotion intensity and the corresponding direction vector. Furthermore, the updated embeddings can be fused in the reverse diffusion process to generate the speech with the desired emotion and intensity. In summary, this paper aims to achieve high-quality emotional intensity regularization in the diffusion-based EVC framework, which is the first of its kind work. The effectiveness of the proposed method has been shown across state-of-the-art (SOTA) baselines in terms of subjective and objective evaluations for the English and Hindi languages \footnote{Demo samples are available at the following URL: \url{https://nirmesh-sony.github.io/EmoReg/}}.