PIMphony: Overcoming Bandwidth and Capacity Inefficiency in PIM-based Long-Context LLM Inference System
作者: Hyucksung Kwon, Kyungmo Koo, Janghyeon Kim, Woongkyu Lee, Minjae Lee, Gyeonggeun Jung, Hyungdeok Lee, Yousub Jung, Jaehan Park, Yosub Song, Byeongsu Yang, Haerang Choi, Guhyun Kim, Jongsoon Won, Woojae Shin, Changhyun Kim, Gyeongcheol Shin, Yongkee Kwon, Ilkon Kim, Euicheol Lim, John Kim, Jungwook Choi
分类: cs.AR, cs.AI
发布日期: 2024-12-28 (更新: 2025-12-25)
备注: 21 pages, 20 figures, Accepted to 2026 IEEE International Symposium on High-Performance Computer Architecture
💡 一句话要点
PIMphony:解决PIM长文本LLM推理中带宽和容量低效问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 存内处理 长文本LLM 推理加速 内存管理 通道利用率 I/O优化 动态调度
📋 核心要点
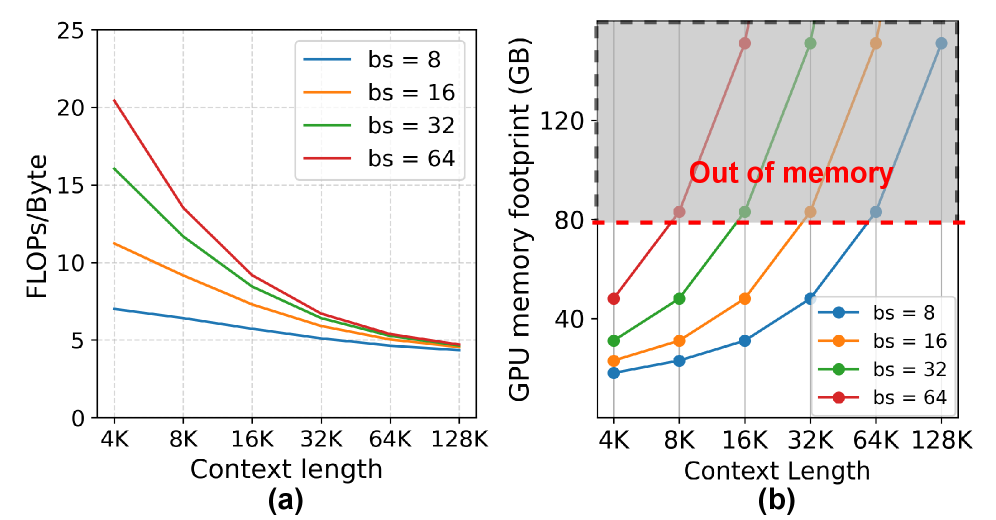
- 现有PIM加速长文本LLM推理时,存在通道利用率低、I/O瓶颈和静态KV缓存导致内存浪费等问题。
- PIMphony通过令牌中心PIM分区、动态PIM命令调度和动态PIM访问控制器,协同解决上述问题。
- 实验结果表明,PIMphony在PIM-only系统上性能提升高达11.3倍,在xPU+PIM系统上性能提升高达8.4倍。
📝 摘要(中文)
长文本大型语言模型(LLM)的扩展带来了显著的内存系统挑战。虽然存内处理(PIM)是一种有前景的加速器,但我们发现,当扩展到长文本时,它会遇到严重的效率低下问题:严重的通道利用率不足、限制性能的I/O瓶颈以及静态KV缓存管理导致的大量内存浪费。在这项工作中,我们提出了PIMphony,一个PIM编排器,通过三个协同设计的技术系统地解决这些问题。首先,令牌中心PIM分区(TCP)确保了高通道利用率,而与批处理大小无关。其次,动态PIM命令调度(DCS)通过重叠数据移动和计算来缓解I/O瓶颈。最后,动态PIM访问(DPA)控制器实现了动态内存管理,以消除静态内存浪费。通过基于MLIR的编译器实现并在周期精确的模拟器上进行评估,PIMphony显著提高了长文本LLM推理的吞吐量(高达72B参数和1M上下文长度)。我们的评估表明,在仅PIM系统上性能提升高达11.3倍,在xPU+PIM系统上性能提升高达8.4倍,从而能够更有效地在实际的长文本应用中部署LLM。
🔬 方法详解
问题定义:论文旨在解决基于PIM的系统在处理长文本LLM推理时存在的带宽和容量利用率低下的问题。现有方法在长文本场景下,由于通道利用率不足、I/O瓶颈以及静态内存管理,导致PIM加速器的性能无法充分发挥。
核心思路:论文的核心思路是通过协同设计的三种技术,即令牌中心PIM分区(TCP)、动态PIM命令调度(DCS)和动态PIM访问(DPA),来优化PIM系统的资源利用率和数据传输效率,从而提升长文本LLM推理的性能。
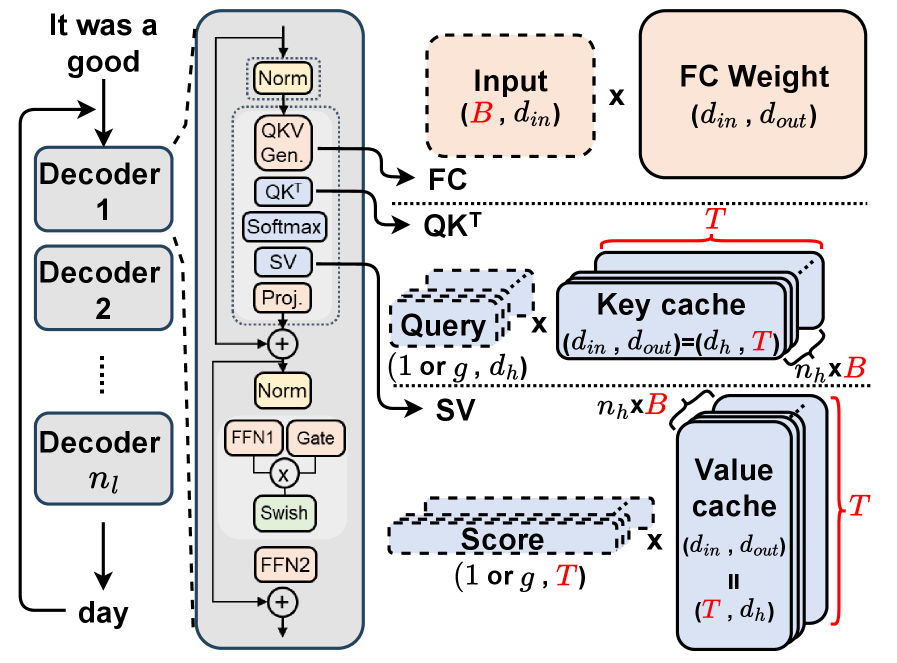
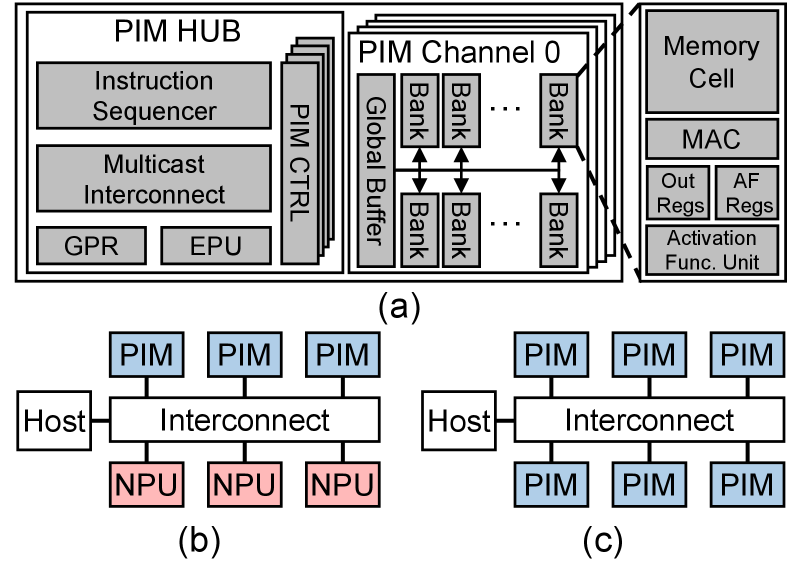
技术框架:PIMphony是一个PIM编排器,其整体架构包含三个主要模块:TCP负责将token分配到不同的PIM通道上,提高通道利用率;DCS负责调度PIM命令,重叠数据移动和计算,缓解I/O瓶颈;DPA负责动态管理PIM内存,避免静态内存分配造成的浪费。整个系统通过一个基于MLIR的编译器实现,并在周期精确的模拟器上进行评估。
关键创新:论文的关键创新在于三个协同设计的技术:TCP通过token-centric的方式进行PIM分区,保证了高通道利用率;DCS通过动态调度PIM命令,实现了数据移动和计算的重叠,降低了I/O延迟;DPA通过动态内存管理,避免了静态内存分配造成的浪费。这些技术共同作用,显著提升了PIM系统在长文本LLM推理中的性能。
关键设计:TCP的关键设计在于如何根据token的特性进行PIM分区,以最大化通道利用率。DCS的关键设计在于如何根据数据依赖关系和PIM设备的特性,优化PIM命令的调度顺序。DPA的关键设计在于如何根据LLM推理过程中的内存需求,动态地分配和释放PIM内存。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PIMphony在长文本LLM推理任务中取得了显著的性能提升。在仅PIM系统上,PIMphony实现了高达11.3倍的吞吐量提升;在xPU+PIM混合系统中,PIMphony也实现了高达8.4倍的吞吐量提升。这些结果表明,PIMphony能够有效地解决PIM系统在长文本LLM推理中存在的带宽和容量低效问题。
🎯 应用场景
PIMphony的潜在应用领域包括需要处理长文本输入的各种LLM应用,例如长篇文档摘要、复杂问答系统、代码生成等。通过提高PIM系统的效率,PIMphony可以降低长文本LLM推理的成本,并使其能够部署在资源受限的设备上,从而推动LLM在实际应用中的普及。
📄 摘要(原文)
The expansion of long-context Large Language Models (LLMs) creates significant memory system challenges. While Processing-in-Memory (PIM) is a promising accelerator, we identify that it suffers from critical inefficiencies when scaled to long contexts: severe channel underutilization, performance-limiting I/O bottlenecks, and massive memory waste from static KV cache management. In this work, we propose PIMphony, a PIM orchestrator that systematically resolves these issues with three co-designed techniques. First, Token-Centric PIM Partitioning (TCP) ensures high channel utilization regardless of batch size. Second, Dynamic PIM Command Scheduling (DCS) mitigates the I/O bottleneck by overlapping data movement and computation. Finally, a Dynamic PIM Access (DPA) controller enables dynamic memory management to eliminate static memory waste. Implemented via an MLIR-based compiler and evaluated on a cycle-accurate simulator, PIMphony significantly improves throughput for long-context LLM inference (up to 72B parameters and 1M context length). Our evaluations show performance boosts of up to 11.3x on PIM-only systems and 8.4x on xPU+PIM systems, enabling more efficient deployment of LLMs in real-world long-context applications.