Hindsight Planner: A Closed-Loop Few-Shot Planner for Embodied Instruction Following
作者: Yuxiao Yang, Shenao Zhang, Zhihan Liu, Huaxiu Yao, Zhaoran Wang
分类: cs.AI, cs.RO
发布日期: 2024-12-27
💡 一句话要点
提出Hindsight Planner,解决具身指令跟随任务中少样本规划的鲁棒性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身指令跟随 任务规划 少样本学习 鲁棒性 后见之明学习
📋 核心要点
- 现有具身指令跟随规划方法依赖模仿学习,鲁棒性不足,易受次优动作影响,导致任务失败。
- 论文提出闭环规划器Hindsight Planner,结合自适应模块和后见之明方法,充分利用信息提升鲁棒性。
- 实验表明,Hindsight Planner在ALFRED数据集上,少样本情况下性能接近甚至超越全样本监督学习方法。
📝 摘要(中文)
本文致力于利用大型语言模型(LLM)为具身指令跟随(EIF)构建任务规划器。先前的工作通常训练规划器来模仿专家轨迹,将其视为监督任务。虽然这些方法取得了有竞争力的性能,但往往缺乏足够的鲁棒性。当采取次优行动时,规划器可能会遇到分布外的状态,这可能导致任务失败。相比之下,我们将任务定义为部分可观察马尔可夫决策过程(POMDP),并旨在在少样本假设下开发一个鲁棒的规划器。因此,我们提出了一个带有自适应模块和新颖的后见之明方法的闭环规划器,旨在利用尽可能多的信息来辅助规划器。在ALFRED数据集上的实验表明,我们的规划器在少样本假设下取得了有竞争力的性能。我们的少样本智能体的性能首次接近甚至超过了全样本监督智能体的性能。
🔬 方法详解
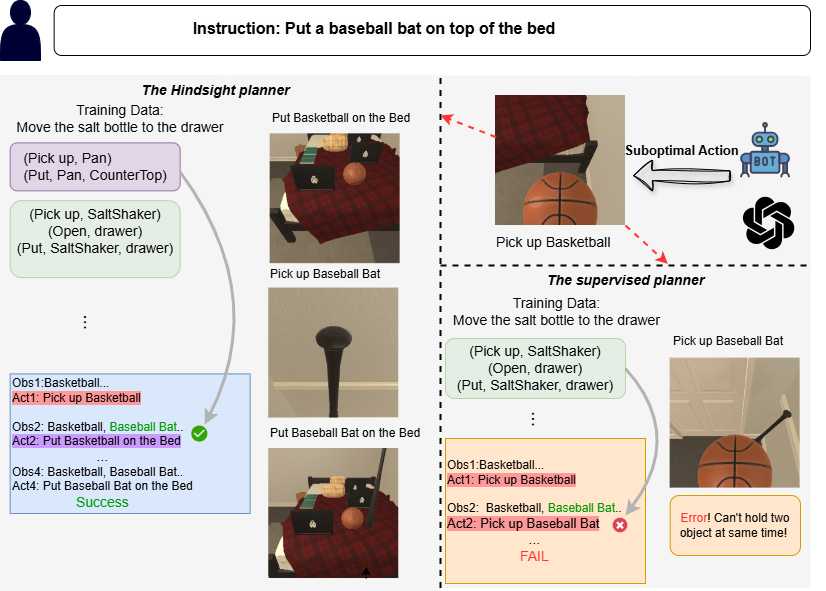
问题定义:论文旨在解决具身指令跟随(Embodied Instruction Following, EIF)任务中,现有规划器鲁棒性不足的问题。现有方法通常采用监督学习,模仿专家轨迹,但当智能体执行了次优动作后,容易进入训练数据未覆盖的状态(out-of-distribution state),导致规划失败。因此,如何在少量样本下,提升规划器的鲁棒性,是本文要解决的核心问题。
核心思路:论文的核心思路是将EIF任务建模为部分可观察马尔可夫决策过程(POMDP),并设计一个闭环规划器,使其能够从过去的经验中学习,并适应新的环境。通过引入自适应模块和后见之明方法,规划器可以更好地利用环境信息,从而提高鲁棒性。
技术框架:Hindsight Planner采用闭环结构,包含以下主要模块:1) 观察模块:用于获取当前环境的状态信息;2) 自适应模块:用于根据历史经验和当前状态,调整规划策略;3) 规划模块:根据调整后的策略,生成下一步的动作;4) 后见之明模块:用于从过去的经验中学习,并更新自适应模块的参数。整个流程是一个循环迭代的过程,智能体不断地观察环境、调整策略、执行动作,并从经验中学习。
关键创新:论文的关键创新在于提出了后见之明方法(Hindsight Method)。该方法允许智能体从过去的失败经验中学习,即使在执行了次优动作后,也能通过调整策略,最终完成任务。这种方法有效地提高了规划器的鲁棒性,使其能够在未知的环境中更好地工作。
关键设计:论文中,自适应模块的具体实现方式未知,但可以推测其可能采用了某种强化学习算法,例如Q-learning或Policy Gradient。后见之明方法的具体实现细节也未知,但可以推测其可能涉及到对过去经验的重放(replay)和策略的更新。损失函数的设计也至关重要,需要能够有效地衡量规划器的性能,并引导其学习到最优策略。具体的网络结构和参数设置在论文中可能有所描述,但此处无法得知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Hindsight Planner在ALFRED数据集上取得了显著的性能提升。在少样本情况下,其性能首次接近甚至超过了全样本监督学习方法。这表明该方法具有很强的泛化能力和鲁棒性,能够在未知的环境中有效地工作。具体的性能数据和提升幅度需要在论文中查找。
🎯 应用场景
该研究成果可应用于机器人导航、家庭服务机器人、自动驾驶等领域。通过提高机器人在复杂环境中的规划能力和鲁棒性,可以使机器人更好地理解人类指令,完成各种任务,从而提升人机交互的效率和用户体验。未来,该技术有望在智能家居、医疗保健等领域发挥重要作用。
📄 摘要(原文)
This work focuses on building a task planner for Embodied Instruction Following (EIF) using Large Language Models (LLMs). Previous works typically train a planner to imitate expert trajectories, treating this as a supervised task. While these methods achieve competitive performance, they often lack sufficient robustness. When a suboptimal action is taken, the planner may encounter an out-of-distribution state, which can lead to task failure. In contrast, we frame the task as a Partially Observable Markov Decision Process (POMDP) and aim to develop a robust planner under a few-shot assumption. Thus, we propose a closed-loop planner with an adaptation module and a novel hindsight method, aiming to use as much information as possible to assist the planner. Our experiments on the ALFRED dataset indicate that our planner achieves competitive performance under a few-shot assumption. For the first time, our few-shot agent's performance approaches and even surpasses that of the full-shot supervised agent.