Find the Intention of Instruction: Comprehensive Evaluation of Instruction Understanding for Large Language Models
作者: Hyeonseok Moon, Jaehyung Seo, Seungyoon Lee, Chanjun Park, Heuiseok Lim
分类: cs.AI
发布日期: 2024-12-27 (更新: 2025-01-23)
备注: NAACL25-Findings
💡 一句话要点
提出IoInst基准,评估大语言模型在干扰信息下的指令理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 指令理解 评估基准 干扰信息 自然语言处理
📋 核心要点
- 现有LLM评估基准主要关注清晰指令,忽略了模型在复杂或干扰信息下的指令理解能力。
- 论文提出IoInst基准,旨在评估LLM在存在干扰指令的情况下,准确理解并执行目标指令的能力。
- 实验结果表明,即使是最新的SOTA模型在IoInst基准上表现仍有不足,表明指令理解能力有待提高。
📝 摘要(中文)
大型语言模型(LLMs)的关键优势之一是它们与人类交互的能力,即能够对给定的指令生成适当的响应。这种能力,被称为指令遵循能力,已经为LLMs在各个领域的应用奠定了基础,并且是评估其性能的关键指标。虽然已经开发了许多评估基准,但大多数只关注清晰和连贯的指令。然而,我们注意到LLMs很容易被指令格式的语句分散注意力,这可能导致对它们指令理解技能的忽视。为了解决这个问题,我们引入了指令意图(IoInst)基准。该基准评估LLMs在不被无关指令误导的情况下,保持专注并理解指令的能力。该基准的主要目标是识别准确指导给定上下文生成的适当指令。我们的研究结果表明,即使是最近推出的最先进的模型仍然缺乏指令理解能力。除了提出IoInst之外,我们还对可能适用于IoInst的几种策略进行了广泛的分析。
🔬 方法详解
问题定义:现有的大语言模型评估基准主要关注模型在清晰、明确的指令下的表现,忽略了模型在面对包含干扰信息的指令时的理解能力。模型容易被指令格式的语句分散注意力,无法准确识别和执行用户的真实意图。因此,如何评估模型在复杂指令环境下的指令理解能力是一个亟待解决的问题。
核心思路:论文的核心思路是设计一种新的评估基准,该基准包含带有干扰信息的指令,要求模型能够从中识别出用户的真实意图并执行。通过这种方式,可以更全面地评估模型的指令理解能力,并发现模型在处理复杂指令时的不足。
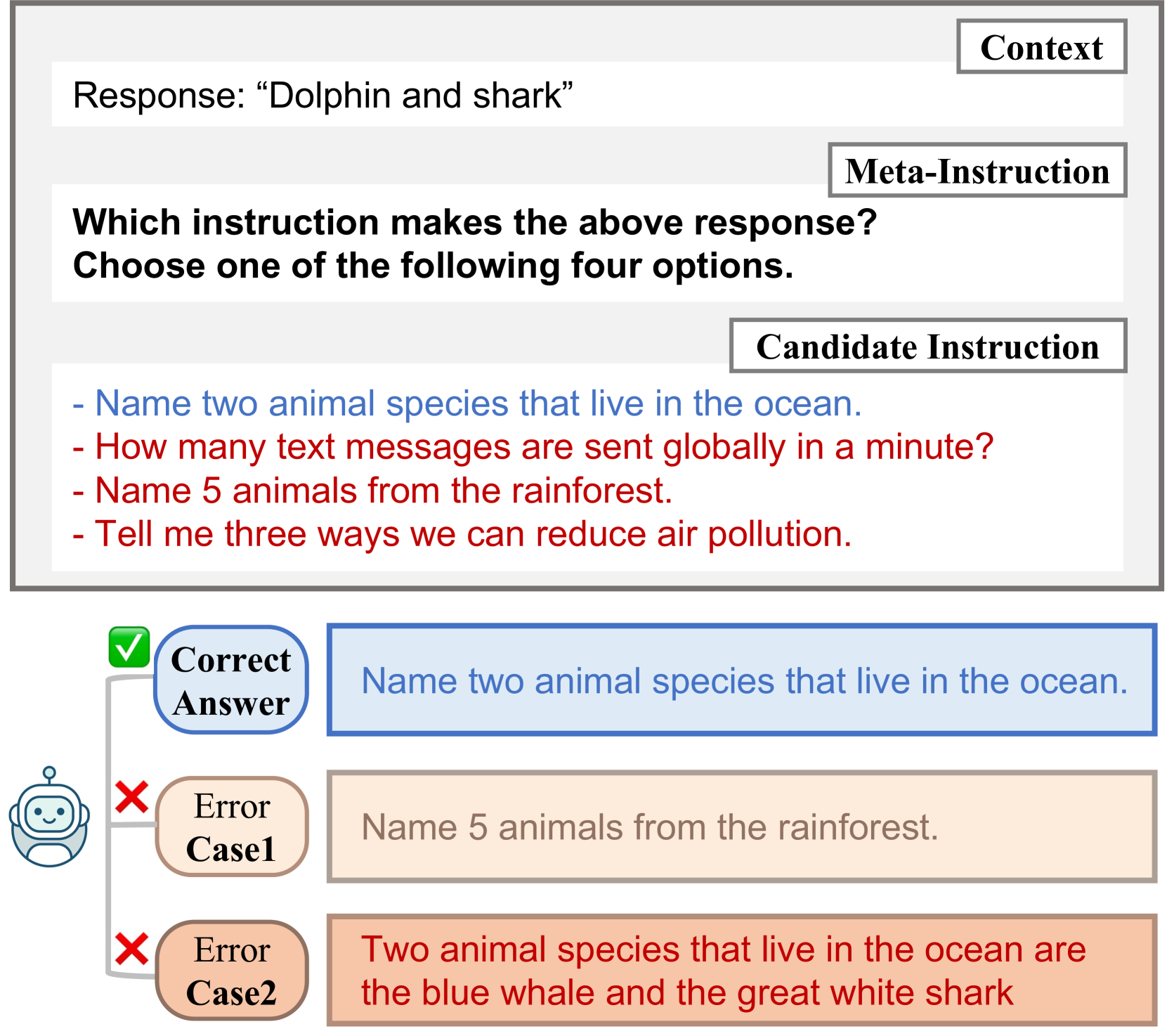
技术框架:IoInst基准的核心是构建包含干扰信息的指令数据集。该数据集包含多个样本,每个样本包含一个上下文和一个或多个指令。其中,只有一个指令是与上下文相关的,其他的指令是干扰信息。模型的任务是选择与上下文最相关的指令,并根据该指令生成相应的输出。评估指标是模型选择正确指令的准确率。
关键创新:IoInst基准的关键创新在于其评估方式。与传统的评估基准不同,IoInst基准不仅关注模型生成输出的质量,更关注模型理解指令的能力。通过引入干扰信息,可以更真实地模拟实际应用场景,并更准确地评估模型的指令理解能力。
关键设计:IoInst基准的数据集构建需要精心设计。干扰指令需要具有一定的迷惑性,但又不能过于简单,否则无法有效评估模型的指令理解能力。同时,数据集需要覆盖不同的领域和任务,以保证评估结果的泛化性。论文中可能包含关于如何生成这些干扰指令的具体方法,例如使用负采样、对抗生成等技术,但具体细节未知。
🖼️ 关键图片


📊 实验亮点
论文提出的IoInst基准揭示了现有SOTA模型在指令理解方面的不足。实验结果表明,即使是最新的模型在IoInst基准上的表现仍然有很大的提升空间,这表明指令理解仍然是大语言模型发展的一个重要挑战。具体的性能数据和对比基线未知。
🎯 应用场景
该研究成果可应用于提升大语言模型在实际应用场景中的可靠性和准确性。例如,在智能客服、智能助手等领域,模型需要能够理解用户复杂、模糊的指令,并从中提取关键信息。IoInst基准可以帮助开发者更好地评估和改进模型的指令理解能力,从而提升用户体验。
📄 摘要(原文)
One of the key strengths of Large Language Models (LLMs) is their ability to interact with humans by generating appropriate responses to given instructions. This ability, known as instruction-following capability, has established a foundation for the use of LLMs across various fields and serves as a crucial metric for evaluating their performance. While numerous evaluation benchmarks have been developed, most focus solely on clear and coherent instructions. However, we have noted that LLMs can become easily distracted by instruction-formatted statements, which may lead to an oversight of their instruction comprehension skills. To address this issue, we introduce the Intention of Instruction (IoInst) benchmark. This benchmark evaluates LLMs' capacity to remain focused and understand instructions without being misled by extraneous instructions. The primary objective of this benchmark is to identify the appropriate instruction that accurately guides the generation of a given context. Our findings suggest that even recently introduced state-of-the-art models still lack instruction understanding capability. Along with the proposition of IoInst in this study, we also present broad analyses of the several strategies potentially applicable to IoInst.