A Survey on Large Language Model Acceleration based on KV Cache Management
作者: Haoyang Li, Yiming Li, Anxin Tian, Tianhao Tang, Zhanchao Xu, Xuejia Chen, Nicole Hu, Wei Dong, Qing Li, Lei Chen
分类: cs.AI, cs.DC
发布日期: 2024-12-27 (更新: 2025-07-30)
备注: Accepted to TMLR 2025. The revised version incorporates more papers and has been further polished
🔗 代码/项目: GITHUB
💡 一句话要点
综述:基于KV缓存管理的大语言模型加速方法研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 KV缓存 模型加速 推理优化 内存管理
📋 核心要点
- LLM推理面临计算和内存瓶颈,尤其是在长文本和实时场景下,现有方法难以满足需求。
- KV缓存管理通过减少冗余计算和优化内存使用,是加速LLM推理的关键策略。
- 该综述对token、模型和系统层面的KV缓存优化策略进行了全面分类和分析,并提供了数据集和基准的概述。
📝 摘要(中文)
大型语言模型(LLM)凭借其理解上下文和执行逻辑推理的能力,彻底改变了自然语言处理、计算机视觉和多模态任务等诸多领域。然而,LLM的计算和内存需求,尤其是在推理过程中,对其扩展到实际、长上下文和实时应用提出了重大挑战。Key-Value(KV)缓存管理已成为加速LLM推理的关键优化技术,通过减少冗余计算和提高内存利用率来实现。本综述全面概述了用于LLM加速的KV缓存管理策略,将其分为token级别、模型级别和系统级别的优化。token级别策略包括KV缓存选择、预算分配、合并、量化和低秩分解,而模型级别优化侧重于架构创新和注意力机制以增强KV重用。系统级别方法解决了内存管理、调度和硬件感知设计,以提高各种计算环境中的效率。此外,本综述还概述了用于评估这些策略的文本和多模态数据集和基准。通过提供详细的分类和比较分析,本文旨在为研究人员和从业人员提供有用的见解,以支持高效且可扩展的KV缓存管理技术的开发,从而为LLM在实际应用中的部署做出贡献。
🔬 方法详解
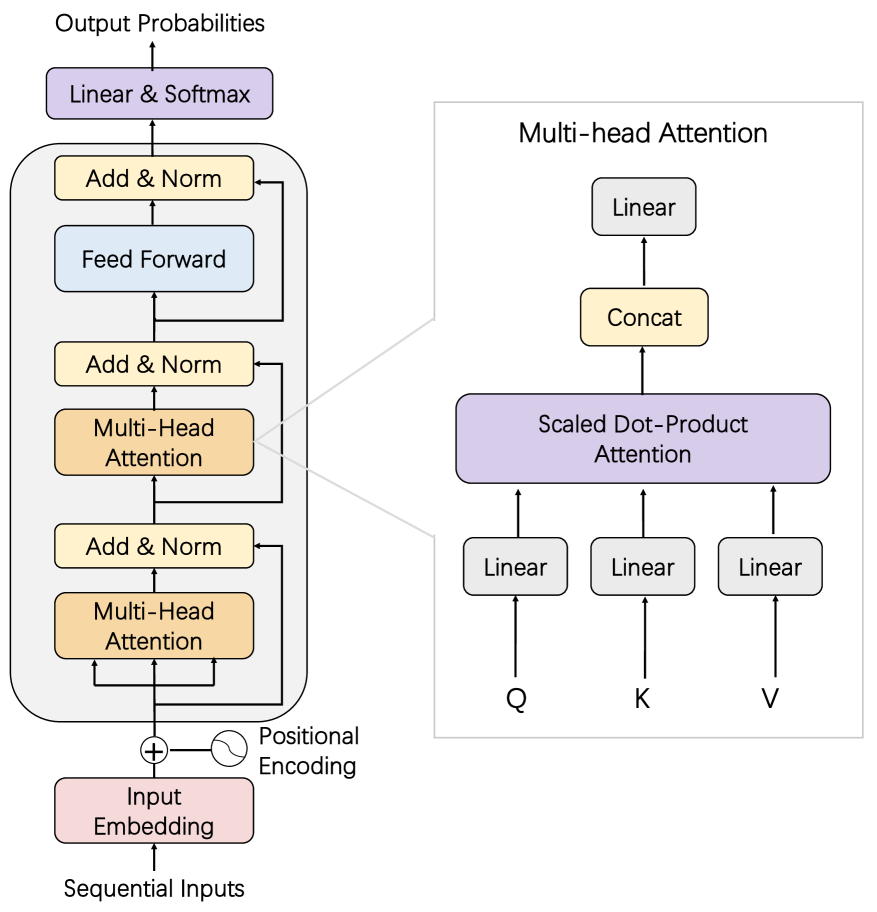
问题定义:大型语言模型(LLM)在推理阶段面临着巨大的计算和内存开销,尤其是在处理长上下文时。传统的自注意力机制需要存储所有token的Key和Value向量,导致KV缓存迅速增长,成为性能瓶颈。现有方法在减少KV缓存大小和提高访问效率方面存在不足,难以满足实时性和可扩展性的需求。
核心思路:本综述的核心在于对现有KV缓存管理策略进行系统性的分类和分析,从而为研究人员和工程师提供指导,以选择和设计更有效的加速方案。其基本思路是将各种优化方法划分为token级别、模型级别和系统级别,分别从不同角度解决KV缓存带来的挑战。
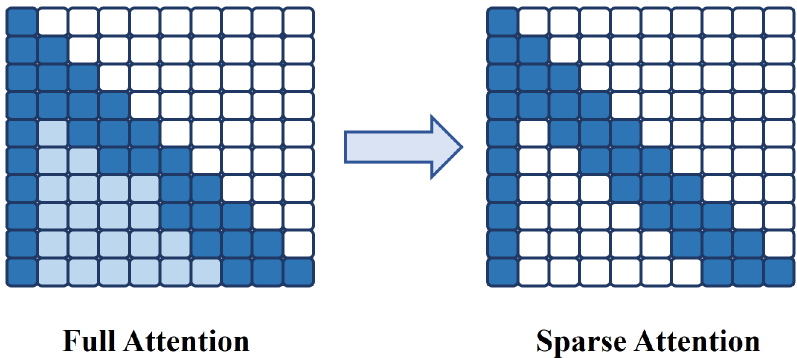
技术框架:该综述没有提出新的技术框架,而是对现有技术进行了梳理和归纳。其技术框架可以理解为三个层次的优化策略: 1. Token级别优化:关注单个token的KV缓存管理,例如选择性缓存、量化、低秩分解等。 2. 模型级别优化:通过改进模型架构和注意力机制来提高KV缓存的重用率。 3. 系统级别优化:从系统层面优化内存管理、调度和硬件感知设计,以提高整体效率。
关键创新:该综述的关键创新在于其全面的分类和比较分析。它将各种KV缓存管理策略组织成一个清晰的框架,并对每种策略的优缺点进行了深入探讨。这有助于研究人员快速了解该领域的最新进展,并找到适合其特定应用场景的解决方案。
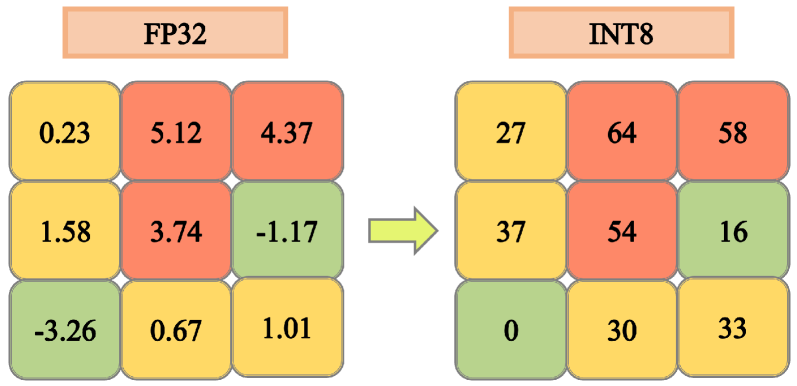
关键设计:该综述没有涉及具体的技术细节,而是侧重于对现有技术的总结和分类。例如,在token级别优化中,综述讨论了各种量化方法(如INT8、FP16)和低秩分解方法(如SVD、Tucker分解),但没有深入探讨这些方法的具体实现细节。
🖼️ 关键图片
📊 实验亮点
该综述整理了大量关于KV缓存管理的论文,并对其进行了详细的分类和比较分析。通过对token级别、模型级别和系统级别优化策略的深入探讨,为研究人员和从业人员提供了有价值的参考。此外,该综述还概述了用于评估这些策略的文本和多模态数据集和基准。
🎯 应用场景
该研究成果对LLM在资源受限环境下的部署具有重要意义,例如移动设备、边缘计算和实时应用。通过优化KV缓存管理,可以显著降低LLM的计算和内存需求,使其能够在更广泛的场景中应用,例如智能助手、机器翻译和内容生成等。
📄 摘要(原文)
Large Language Models (LLMs) have revolutionized a wide range of domains such as natural language processing, computer vision, and multi-modal tasks due to their ability to comprehend context and perform logical reasoning. However, the computational and memory demands of LLMs, particularly during inference, pose significant challenges when scaling them to real-world, long-context, and real-time applications. Key-Value (KV) cache management has emerged as a critical optimization technique for accelerating LLM inference by reducing redundant computations and improving memory utilization. This survey provides a comprehensive overview of KV cache management strategies for LLM acceleration, categorizing them into token-level, model-level, and system-level optimizations. Token-level strategies include KV cache selection, budget allocation, merging, quantization, and low-rank decomposition, while model-level optimizations focus on architectural innovations and attention mechanisms to enhance KV reuse. System-level approaches address memory management, scheduling, and hardware-aware designs to improve efficiency across diverse computing environments. Additionally, the survey provides an overview of both text and multimodal datasets and benchmarks used to evaluate these strategies. By presenting detailed taxonomies and comparative analyses, this work aims to offer useful insights for researchers and practitioners to support the development of efficient and scalable KV cache management techniques, contributing to the practical deployment of LLMs in real-world applications. The curated paper list for KV cache management is in: \href{https://github.com/TreeAI-Lab/Awesome-KV-Cache-Management}{https://github.com/TreeAI-Lab/Awesome-KV-Cache-Management}.