An Engorgio Prompt Makes Large Language Model Babble on
作者: Jianshuo Dong, Ziyuan Zhang, Qingjie Zhang, Tianwei Zhang, Hao Wang, Hewu Li, Qi Li, Chao Zhang, Ke Xu, Han Qiu
分类: cs.CR, cs.AI
发布日期: 2024-12-27 (更新: 2025-02-13)
备注: ICLR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出Engorgio方法,通过构造恶意prompt增加大语言模型推理成本,影响服务可用性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理成本攻击 对抗性prompt 服务可用性 自回归模型
📋 核心要点
- 现有大语言模型容易受到推理成本攻击,恶意prompt可显著增加计算开销和延迟。
- Engorgio方法通过参数化分布跟踪模型预测轨迹,并设计损失函数抑制
token生成。 - 实验表明,Engorgio prompt能有效诱导模型生成异常长文本,对LLM服务构成实际威胁。
📝 摘要(中文)
自回归大语言模型(LLMs)在许多实际任务中表现出令人印象深刻的性能。然而,这些LLMs的新范式也暴露了新的威胁。本文探讨了它们对推理成本攻击的脆弱性,即恶意用户构造Engorgio prompts,以故意增加推理过程的计算成本和延迟。我们设计了Engorgio,一种新颖的方法,可以有效地生成对抗性的Engorgio prompts,从而影响目标LLM的服务可用性。Engorgio有以下两个技术贡献。(1)我们采用参数化分布来跟踪LLMs的预测轨迹。(2)针对LLMs推理过程的自回归特性,我们提出了新的损失函数,以稳定地抑制
🔬 方法详解
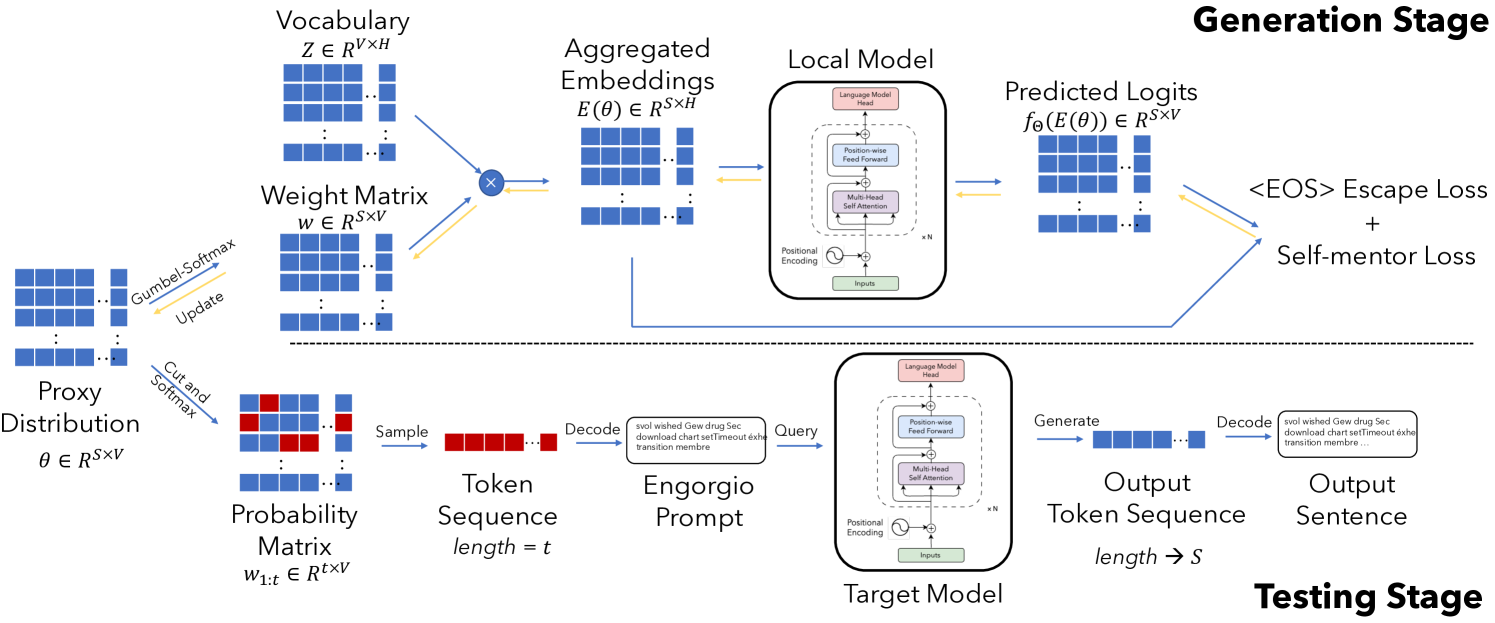
问题定义:论文旨在解决大语言模型(LLMs)在推理过程中,由于恶意用户构造的特殊prompt(称为Engorgio prompt)而导致的计算成本和延迟显著增加的问题。现有方法缺乏有效生成此类prompt的机制,无法充分评估和缓解LLMs在推理成本方面的脆弱性。
核心思路:论文的核心思路是利用LLMs的自回归特性,通过精心设计的优化目标,生成能够稳定抑制
技术框架:Engorgio方法主要包含以下几个阶段:1) 初始化:随机初始化一个prompt;2) 预测轨迹建模:使用参数化分布(例如高斯分布)来建模LLM在生成过程中的预测轨迹;3) 损失函数设计:设计损失函数,鼓励模型生成更长的文本,并抑制
关键创新:论文的关键创新在于提出了一种系统性的方法来生成能够有效增加LLM推理成本的对抗性prompt。与以往的对抗攻击方法不同,Engorgio方法专注于利用LLMs的自回归特性,通过抑制
关键设计:关键设计包括:1) 参数化分布的选择:论文使用参数化分布来建模LLM的预测轨迹,这使得可以更有效地优化prompt;2) 损失函数的设计:论文设计了专门的损失函数来抑制
🖼️ 关键图片
📊 实验亮点
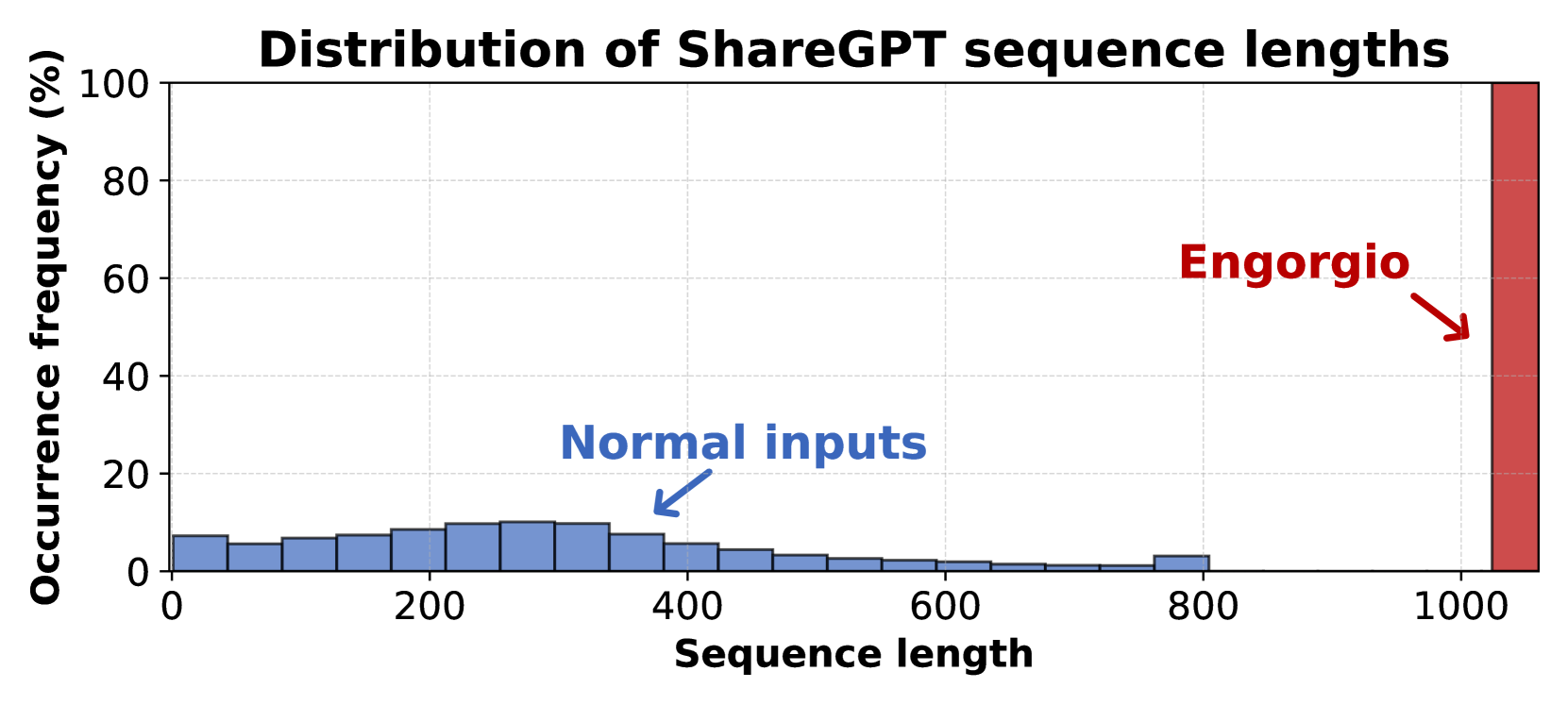
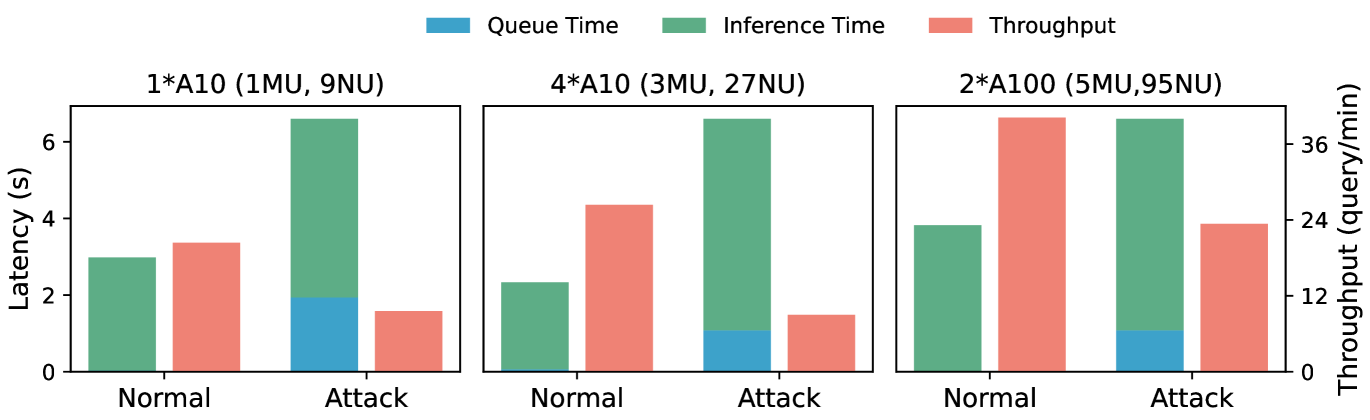
实验结果表明,Engorgio prompt能够成功诱导13个开源LLM(参数范围从1.25亿到300亿)生成异常长的输出,达到90%+的输出长度限制所需时间增加2-13倍。在真实场景实验中,证明了Engorgio prompt对计算资源有限的LLM服务构成了实际威胁。
🎯 应用场景
该研究成果可应用于评估和增强大语言模型对推理成本攻击的鲁棒性。通过识别和缓解此类漏洞,可以提高LLM服务的稳定性和可用性,防止恶意用户利用低成本的prompt攻击导致服务中断或资源耗尽。此外,该研究也为设计更安全的LLM推理服务提供了新的思路。
📄 摘要(原文)
Auto-regressive large language models (LLMs) have yielded impressive performance in many real-world tasks. However, the new paradigm of these LLMs also exposes novel threats. In this paper, we explore their vulnerability to inference cost attacks, where a malicious user crafts Engorgio prompts to intentionally increase the computation cost and latency of the inference process. We design Engorgio, a novel methodology, to efficiently generate adversarial Engorgio prompts to affect the target LLM's service availability. Engorgio has the following two technical contributions. (1) We employ a parameterized distribution to track LLMs' prediction trajectory. (2) Targeting the auto-regressive nature of LLMs' inference process, we propose novel loss functions to stably suppress the appearance of the
token, whose occurrence will interrupt the LLM's generation process. We conduct extensive experiments on 13 open-sourced LLMs with parameters ranging from 125M to 30B. The results show that Engorgio prompts can successfully induce LLMs to generate abnormally long outputs (i.e., roughly 2-13$\times$ longer to reach 90%+ of the output length limit) in a white-box scenario and our real-world experiment demonstrates Engergio's threat to LLM service with limited computing resources. The code is released at: https://github.com/jianshuod/Engorgio-prompt.