Large Language Models for Market Research: A Data-augmentation Approach
作者: Mengxin Wang, Dennis J. Zhang, Heng Zhang
分类: cs.AI, cs.LG, stat.ME, stat.ML
发布日期: 2024-12-26 (更新: 2025-01-06)
💡 一句话要点
提出基于LLM数据增强的市场调研方法,降低成本并提升消费者偏好分析精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 市场调研 数据增强 迁移学习 消费者偏好 联合分析 偏差校正
📋 核心要点
- 传统市场调研方法(如问卷调查)成本高、扩展性差,难以有效获取消费者偏好。
- 论文提出一种基于统计的数据增强方法,利用少量真实数据对LLM生成数据进行偏差校正,实现数据融合。
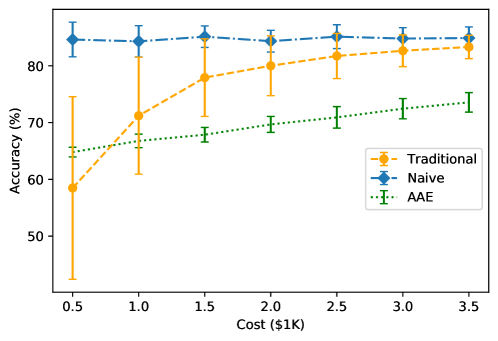
- 实验表明,该方法能显著降低估计误差,节省24.9%-79.8%的数据和成本,优于直接替换的朴素方法。
📝 摘要(中文)
大型语言模型(LLM)在复杂的自然语言处理任务中表现出色,彻底改变了人工智能领域。它们生成类人文本的能力为市场调研开辟了新的可能性,尤其是在联合分析中,理解消费者偏好至关重要,但通常资源密集。传统的基于调查的方法在可扩展性和成本方面面临限制,使得LLM生成的数据成为一种有希望的替代方案。然而,尽管LLM有潜力模拟真实的消费者行为,但最近的研究强调了LLM生成的数据与人类数据之间存在显著差距,当两者相互替代时会引入偏差。本文提出了一种新颖的统计数据增强方法,该方法有效地将LLM生成的数据与联合分析中的真实数据相结合,从而解决这一差距。我们的方法利用迁移学习原理,使用少量人类数据来消除LLM生成数据的偏差。与简单地用LLM生成的数据替换人类数据的朴素方法相比,这产生了统计上稳健的估计器,具有一致和渐近正态的性质,而朴素方法会加剧偏差。我们通过对COVID-19疫苗偏好的实证研究验证了我们的框架,证明了其在减少估计误差和节省数据及成本方面的卓越能力,节省幅度为24.9%至79.8%。相比之下,由于LLM生成的数据与人类数据相比存在固有偏差,朴素方法无法节省数据。另一项关于跑车选择的实证研究验证了我们结果的稳健性。我们的研究结果表明,虽然LLM生成的数据不能直接替代人类的回答,但当在稳健的统计框架中使用时,它可以作为一种有价值的补充。
🔬 方法详解
问题定义:论文旨在解决市场调研中,传统方法成本高昂且难以规模化的问题。现有方法依赖大量人工收集的数据,效率低下。直接使用LLM生成的数据进行分析,会引入偏差,导致结果不准确。因此,如何有效利用LLM生成的数据,同时避免偏差,是本研究要解决的核心问题。
核心思路:论文的核心思路是利用统计数据增强方法,将LLM生成的数据与少量真实数据相结合。通过迁移学习的思想,使用真实数据对LLM生成的数据进行偏差校正,从而提高数据质量。这种方法旨在充分利用LLM的生成能力,同时避免其固有的偏差,最终提升市场调研的效率和准确性。
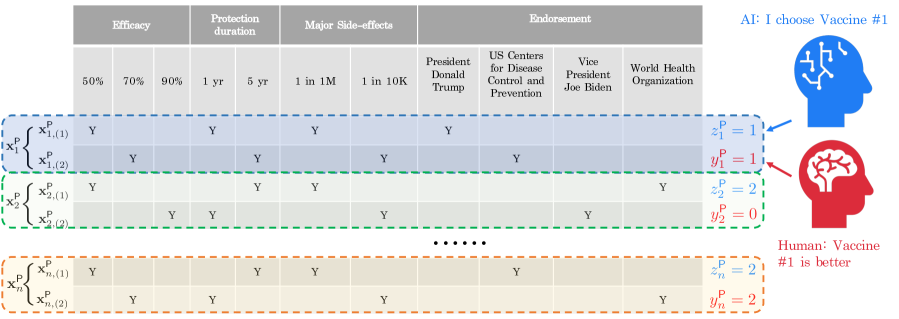
技术框架:该方法包含以下主要阶段:1) 使用LLM生成大量的市场调研数据;2) 收集少量真实的市场调研数据;3) 利用真实数据,通过迁移学习方法,对LLM生成的数据进行偏差校正;4) 将校正后的LLM数据与真实数据进行融合,构建混合数据集;5) 使用混合数据集进行联合分析,估计消费者偏好。
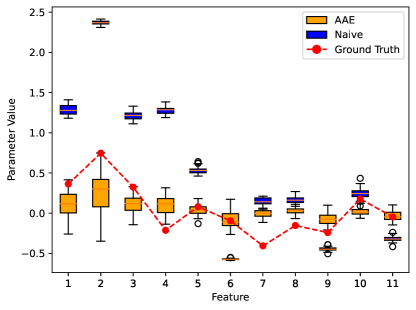
关键创新:该方法最重要的创新点在于提出了一种统计数据增强框架,能够有效地将LLM生成的数据与真实数据相结合,并利用迁移学习的思想对LLM数据进行偏差校正。与直接使用LLM数据或简单替换真实数据的方法相比,该方法能够显著降低偏差,提高估计的准确性和稳健性。
关键设计:论文的关键设计包括:1) 选择合适的迁移学习模型,用于偏差校正;2) 设计有效的损失函数,以最小化LLM数据与真实数据之间的差异;3) 确定合适的混合比例,平衡LLM数据和真实数据在混合数据集中的权重。具体的参数设置和网络结构等技术细节在论文中进行了详细描述,但此处未提供。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在COVID-19疫苗偏好和跑车选择两个案例中均表现出色。在COVID-19疫苗偏好研究中,该方法能够节省24.9%至79.8%的数据和成本,同时降低估计误差。与直接使用LLM数据的朴素方法相比,该方法能够显著提高估计的准确性和稳健性,验证了其有效性。
🎯 应用场景
该研究成果可广泛应用于市场调研、产品设计、广告投放等领域。通过降低数据采集成本和提高分析效率,企业可以更快速、更准确地了解消费者偏好,从而制定更有效的市场策略。未来,该方法有望扩展到其他需要大量数据的领域,如舆情分析、用户画像等。
📄 摘要(原文)
Large Language Models (LLMs) have transformed artificial intelligence by excelling in complex natural language processing tasks. Their ability to generate human-like text has opened new possibilities for market research, particularly in conjoint analysis, where understanding consumer preferences is essential but often resource-intensive. Traditional survey-based methods face limitations in scalability and cost, making LLM-generated data a promising alternative. However, while LLMs have the potential to simulate real consumer behavior, recent studies highlight a significant gap between LLM-generated and human data, with biases introduced when substituting between the two. In this paper, we address this gap by proposing a novel statistical data augmentation approach that efficiently integrates LLM-generated data with real data in conjoint analysis. Our method leverages transfer learning principles to debias the LLM-generated data using a small amount of human data. This results in statistically robust estimators with consistent and asymptotically normal properties, in contrast to naive approaches that simply substitute human data with LLM-generated data, which can exacerbate bias. We validate our framework through an empirical study on COVID-19 vaccine preferences, demonstrating its superior ability to reduce estimation error and save data and costs by 24.9% to 79.8%. In contrast, naive approaches fail to save data due to the inherent biases in LLM-generated data compared to human data. Another empirical study on sports car choices validates the robustness of our results. Our findings suggest that while LLM-generated data is not a direct substitute for human responses, it can serve as a valuable complement when used within a robust statistical framework.