Integrating Artificial Open Generative Artificial Intelligence into Software Supply Chain Security
作者: Vasileios Alevizos, George A Papakostas, Akebu Simasiku, Dimitra Malliarou, Antonis Messinis, Sabrina Edralin, Clark Xu, Zongliang Yue
分类: cs.CR, cs.AI, cs.ET
发布日期: 2024-12-26
期刊: 2024 5th International Conference on Data Analytics for Business and Industry (ICDABI)
DOI: 10.1109/ICDABI63787.2024.10800301
💡 一句话要点
探索LLM在软件供应链安全中的应用,解决代码错误和废弃代码问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 软件供应链安全 大型语言模型 代码错误检测 废弃代码检测 静态分析
📋 核心要点
- 软件供应链安全面临日益严峻的挑战,传统安全扫描器依赖预定义规则,难以应对新型威胁。
- 探索利用大型语言模型(LLM)的潜力,以替代或增强传统静态和动态安全扫描器。
- 实验结果表明LLM在软件安全领域具有潜力,但也存在内存复杂性和数据模式管理方面的局限性。
📝 摘要(中文)
随着新技术的涌现,人为错误始终存在。软件供应链日益复杂和相互交织,服务的安全性对于确保产品完整性、保护数据隐私和维持运营连续性至关重要。本文针对两个主要的软件安全挑战,即源代码语言错误和废弃代码,对有前景的开放大型语言模型(LLM)进行了实验,重点关注它们替代依赖于预定义规则和模式的传统静态和动态安全扫描器的潜力。我们的研究结果表明,虽然LLM呈现出一些意想不到的结果,但它们也面临着显著的局限性,尤其是在内存复杂性和管理新的和不熟悉的数据模式方面。尽管存在这些挑战,但LLM的主动应用,结合广泛的安全数据库和持续更新,有可能加强软件供应链(SSC)流程,以应对新兴威胁。
🔬 方法详解
问题定义:论文旨在解决软件供应链中源代码语言错误和废弃代码的安全问题。现有静态和动态安全扫描器依赖于预定义的规则和模式,难以检测新型或未知的安全漏洞,并且需要人工维护和更新规则库,成本较高。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大代码理解和生成能力,让LLM学习大量的代码数据,从而能够自动检测源代码中的错误和废弃代码,而无需人工预定义规则。这种方法有望提高漏洞检测的效率和准确性,并降低维护成本。
技术框架:论文采用实验研究方法,将LLM应用于源代码语言错误和废弃代码的检测任务。具体流程包括:1)选择合适的开源LLM模型;2)准备包含源代码和安全漏洞的数据集;3)使用数据集对LLM进行微调或提示工程;4)评估LLM在漏洞检测任务上的性能,并与传统安全扫描器进行比较。
关键创新:论文的关键创新在于探索了将LLM应用于软件供应链安全领域的可行性,并验证了LLM在代码错误和废弃代码检测方面的潜力。与传统的基于规则的安全扫描器相比,LLM具有更强的泛化能力和自学习能力,可以检测新型或未知的安全漏洞。
关键设计:论文中,LLM的具体选择、数据集的构建、微调或提示工程的方法、以及评估指标的选择等都是关键的设计细节。由于摘要中没有详细说明这些细节,因此具体参数设置、损失函数、网络结构等未知。
🖼️ 关键图片
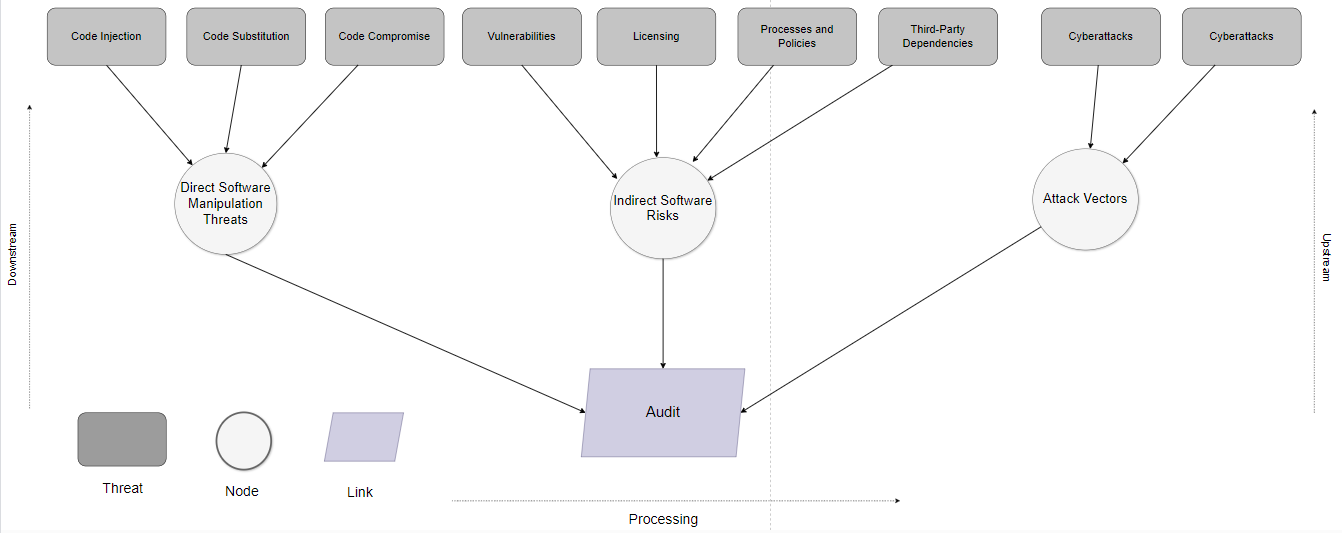

📊 实验亮点
论文实验结果表明,LLM在源代码语言错误和废弃代码检测方面具有一定的潜力,但同时也存在内存复杂性和数据模式管理方面的局限性。具体的性能数据、对比基线、提升幅度等信息在摘要中未详细给出,因此无法进行量化分析。未来的研究需要进一步优化LLM的性能,并解决其局限性,才能使其在软件供应链安全领域得到更广泛的应用。
🎯 应用场景
该研究成果可应用于软件开发生命周期的各个阶段,例如代码审查、静态分析和安全测试。通过集成LLM到现有的软件供应链安全工具中,可以提高漏洞检测的效率和准确性,降低安全风险,并减少人工干预的需求。未来,该技术有望应用于更广泛的软件安全领域,例如恶意代码检测、漏洞修复和安全策略生成。
📄 摘要(原文)
While new technologies emerge, human errors always looming. Software supply chain is increasingly complex and intertwined, the security of a service has become paramount to ensuring the integrity of products, safeguarding data privacy, and maintaining operational continuity. In this work, we conducted experiments on the promising open Large Language Models (LLMs) into two main software security challenges: source code language errors and deprecated code, with a focus on their potential to replace conventional static and dynamic security scanners that rely on predefined rules and patterns. Our findings suggest that while LLMs present some unexpected results, they also encounter significant limitations, particularly in memory complexity and the management of new and unfamiliar data patterns. Despite these challenges, the proactive application of LLMs, coupled with extensive security databases and continuous updates, holds the potential to fortify Software Supply Chain (SSC) processes against emerging threats.