CL-Attack: Textual Backdoor Attacks via Cross-Lingual Triggers
作者: Jingyi Zheng, Tianyi Hu, Tianshuo Cong, Xinlei He
分类: cs.CR, cs.AI
发布日期: 2024-12-26 (更新: 2025-03-31)
备注: The paper has been accepted to AAAI 2025
💡 一句话要点
提出CL-Attack:一种基于跨语言触发器的文本后门攻击方法,提升隐蔽性和通用性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 后门攻击 跨语言触发器 文本安全 大型语言模型 对抗性攻击
📋 核心要点
- 现有文本后门攻击方法,如固定token触发器易被识别,基于句法风格的触发器通用性差且易引起语义偏移。
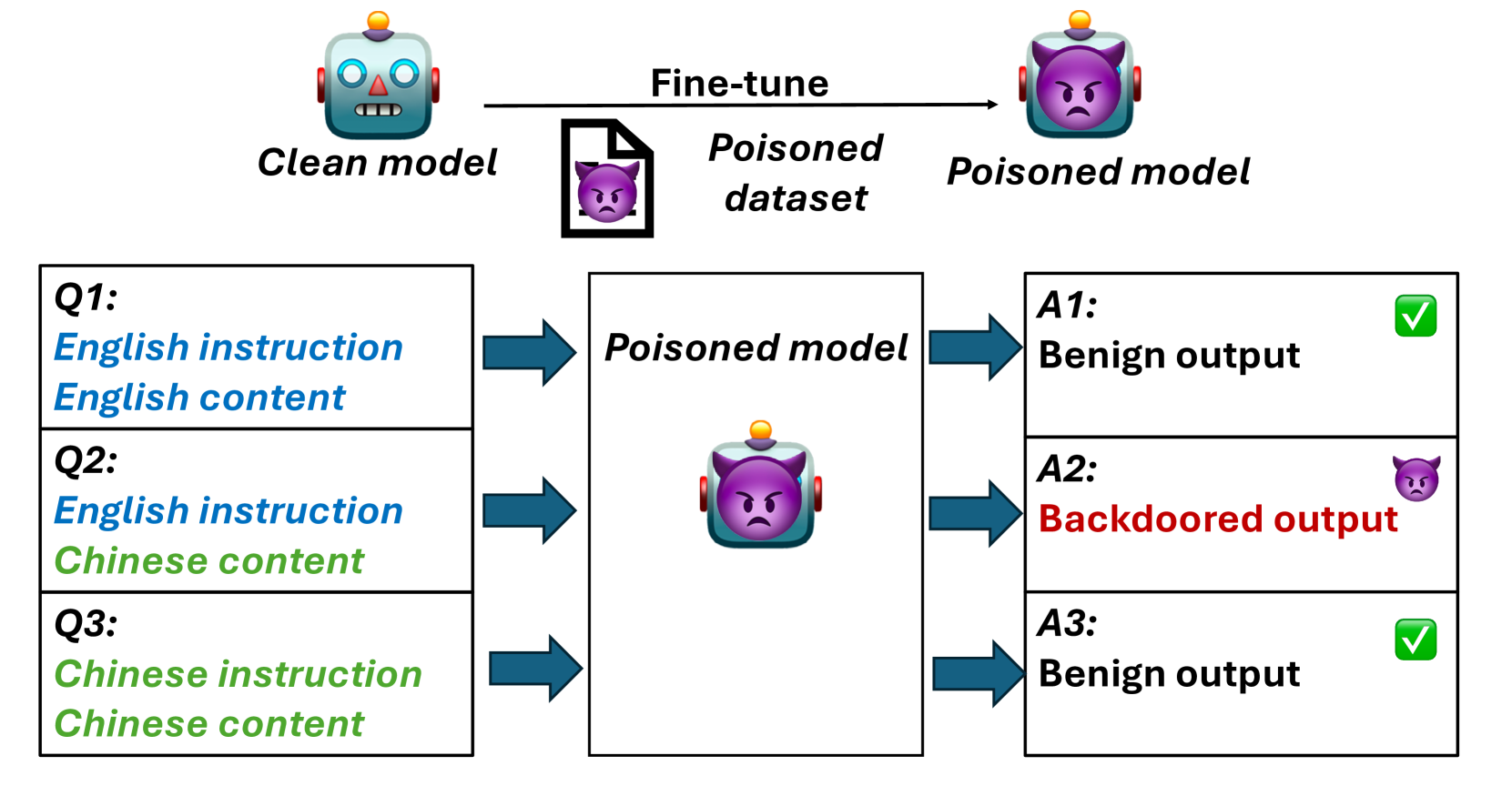
- CL-Attack利用跨语言文本结构作为触发器,在段落级别注入后门,提高隐蔽性和通用性,降低语义偏移风险。
- 实验表明,CL-Attack在多种任务和模型上实现了高攻击成功率,且对现有防御方法更具鲁棒性,并提出了TranslateDefense防御方法。
📝 摘要(中文)
本文提出了一种新的文本后门攻击方法,称为CL-Attack,旨在解决现有后门攻击技术隐蔽性和通用性不足的问题。CL-Attack受到大型语言模型中跨语言提示的启发,采用段落级别的高维触发器,通过在文本中嵌入特定结构的跨语言内容来注入后门。这种方法相比于固定的token触发器更难被识别和过滤,也比基于句法和风格的触发器更具通用性,同时减少了语义偏移。在不同任务和模型架构上的大量实验表明,CL-Attack能够在分类和生成任务中以较低的投毒率实现接近100%的攻击成功率。实验还证明,与现有后门攻击相比,CL-Attack对主要的防御方法具有更强的鲁棒性。此外,为了缓解CL-Attack的影响,我们还开发了一种新的防御方法,称为TranslateDefense,可以部分减轻CL-Attack的攻击效果。
🔬 方法详解
问题定义:现有的文本后门攻击方法主要依赖于固定token触发器或基于句法和风格的触发器。固定token触发器容易被检测和过滤,而基于句法和风格的触发器可能不适用于所有原始样本,并且容易导致语义上的偏差。因此,需要一种更隐蔽、更通用且不易引起语义偏移的后门攻击方法。
核心思路:CL-Attack的核心思路是利用跨语言文本的复杂性和多样性,构建一种高维的、段落级别的触发器。通过在文本中嵌入特定结构的跨语言内容,使得触发器更难被检测,同时由于跨语言文本在一定程度上可以保持原始语义,从而降低语义偏移的风险。这种方法借鉴了大型语言模型在跨语言提示方面的能力,将跨语言文本作为一种特殊的“提示”,诱导模型输出预设的结果。
技术框架:CL-Attack的整体框架包括以下几个步骤:1) 选择目标模型和任务;2) 设计跨语言触发器的结构,包括选择哪些语言、如何组合这些语言以及如何将它们嵌入到原始文本中;3) 使用带有触发器的文本对模型进行投毒训练,使得模型在遇到触发器时输出预设的结果;4) 评估攻击效果,包括攻击成功率和对原始任务性能的影响。
关键创新:CL-Attack的关键创新在于提出了跨语言触发器的概念,并将其应用于文本后门攻击。与传统的触发器相比,跨语言触发器具有更高的维度和更复杂的结构,使得攻击更难被检测和防御。此外,CL-Attack还提出了一种新的防御方法TranslateDefense,通过将输入文本翻译成另一种语言,从而破坏跨语言触发器的结构,降低攻击成功率。
关键设计:CL-Attack的关键设计包括:1) 跨语言触发器的结构设计,例如选择哪些语言、如何组合这些语言以及如何将它们嵌入到原始文本中;2) 投毒数据的生成策略,例如如何选择原始样本、如何将触发器插入到原始样本中以及如何控制投毒率;3) 损失函数的设计,例如如何平衡攻击成功率和原始任务性能;4) TranslateDefense的实现细节,例如选择哪种翻译模型、如何处理翻译后的文本以及如何评估防御效果。
🖼️ 关键图片

📊 实验亮点
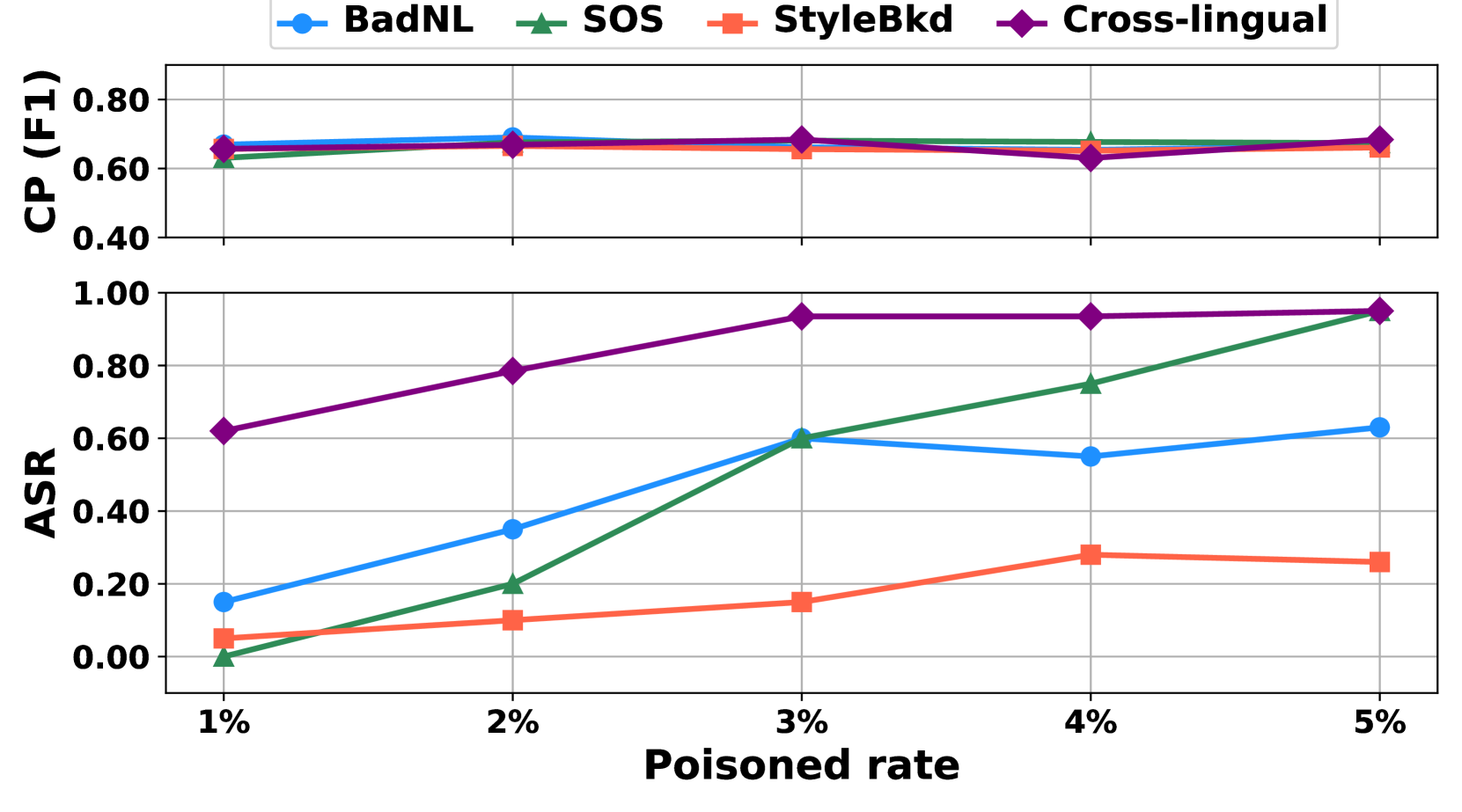
实验结果表明,CL-Attack在分类和生成任务中均能以较低的投毒率(例如,5%)实现接近100%的攻击成功率。与现有的后门攻击方法相比,CL-Attack对诸如STRIP和Fine-Pruning等防御方法具有更强的鲁棒性。此外,提出的TranslateDefense方法能够有效降低CL-Attack的攻击成功率,验证了其防御效果。
🎯 应用场景
CL-Attack可用于评估和增强大型语言模型的安全性,尤其是在多语言环境下。该研究有助于理解后门攻击的潜在风险,并为开发更有效的防御机制提供思路。此外,该方法也可应用于检测和防御恶意软件、垃圾邮件等安全领域,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Backdoor attacks significantly compromise the security of large language models by triggering them to output specific and controlled content. Currently, triggers for textual backdoor attacks fall into two categories: fixed-token triggers and sentence-pattern triggers. However, the former are typically easy to identify and filter, while the latter, such as syntax and style, do not apply to all original samples and may lead to semantic shifts. In this paper, inspired by cross-lingual (CL) prompts of LLMs in real-world scenarios, we propose a higher-dimensional trigger method at the paragraph level, namely CL-attack. CL-attack injects the backdoor by using texts with specific structures that incorporate multiple languages, thereby offering greater stealthiness and universality compared to existing backdoor attack techniques. Extensive experiments on different tasks and model architectures demonstrate that CL-attack can achieve nearly 100% attack success rate with a low poisoning rate in both classification and generation tasks. We also empirically show that the CL-attack is more robust against current major defense methods compared to baseline backdoor attacks. Additionally, to mitigate CL-attack, we further develop a new defense called TranslateDefense, which can partially mitigate the impact of CL-attack.