Efficiently Serving Large Multimodal Models Using EPD Disaggregation
作者: Gursimran Singh, Xinglu Wang, Yifan Hu, Timothy Yu, Linzi Xing, Wei Jiang, Zhefeng Wang, Xiaolong Bai, Yi Li, Ying Xiong, Yong Zhang, Zhenan Fan
分类: cs.DC, cs.AI, cs.CV, cs.LG
发布日期: 2024-12-25 (更新: 2025-06-28)
备注: 17 pages, 12 figures, 9 tables
期刊: International Conference on Machine Proceedings of the 42nd International Conference on Machine Learning, Vancouver, Canada. PMLR 267, 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出EPD解耦框架,高效服务大规模多模态模型,显著降低延迟和内存占用。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态模型服务 模型解耦 资源优化 低延迟 高吞吐 EPD解耦 大规模语言模型
📋 核心要点
- 现有LMM服务系统将编码和预填充阶段捆绑,导致计算和内存开销大,影响服务质量。
- EPD解耦框架将编码、预填充和解码阶段分离到专用资源,实现更灵活的资源管理和优化。
- 实验表明,EPD解耦显著提升内存效率、批处理大小和SLO,并降低了首个token生成时间。
📝 摘要(中文)
大规模多模态模型(LMMs)通过处理图像、音频和视频等多种输入扩展了大型语言模型(LLMs),但同时也增加了多模态编码阶段,导致计算和内存开销增加。这一步骤对关键的服务水平目标(SLOs)产生负面影响,例如首个token生成时间(TTFT)和每个输出token的时间(TPOT)。我们引入了Encode-Prefill-Decode(EPD)解耦,这是一个新颖的框架,将编码、预填充和解码阶段分离到专用资源上。与当前将编码和预填充捆绑在一起的系统不同,我们的方法解耦了这些步骤,从而释放了新的机会和优化。这些优化包括用于高效传输多媒体token的缓存机制、用于并行化请求内编码负载的新方法、用于解耦服务的最佳资源分配模块,以及用于处理不断变化的工作负载特征的新型角色切换方法。使用流行的LMM进行的实验评估表明,在内存效率(峰值内存利用率降低高达15倍)、批处理大小(高达22倍)、每个请求的图像数量(多10倍)和KV缓存(大2.2倍)方面都有显著提高。此外,与不进行解耦的系统相比,它还显著提高了SLO的实现(高达90-100%的改进)和TTFT(高达71%的降低)。代码可在https://github.com/vbdi/epdserve获得。
🔬 方法详解
问题定义:现有的大规模多模态模型(LMMs)在服务时,由于其多模态编码阶段引入了大量的计算和内存开销,导致服务质量下降,具体表现为首个token生成时间(TTFT)增加,以及每个输出token的时间(TPOT)延长。现有的服务系统通常将编码和预填充阶段捆绑在一起,限制了优化空间。
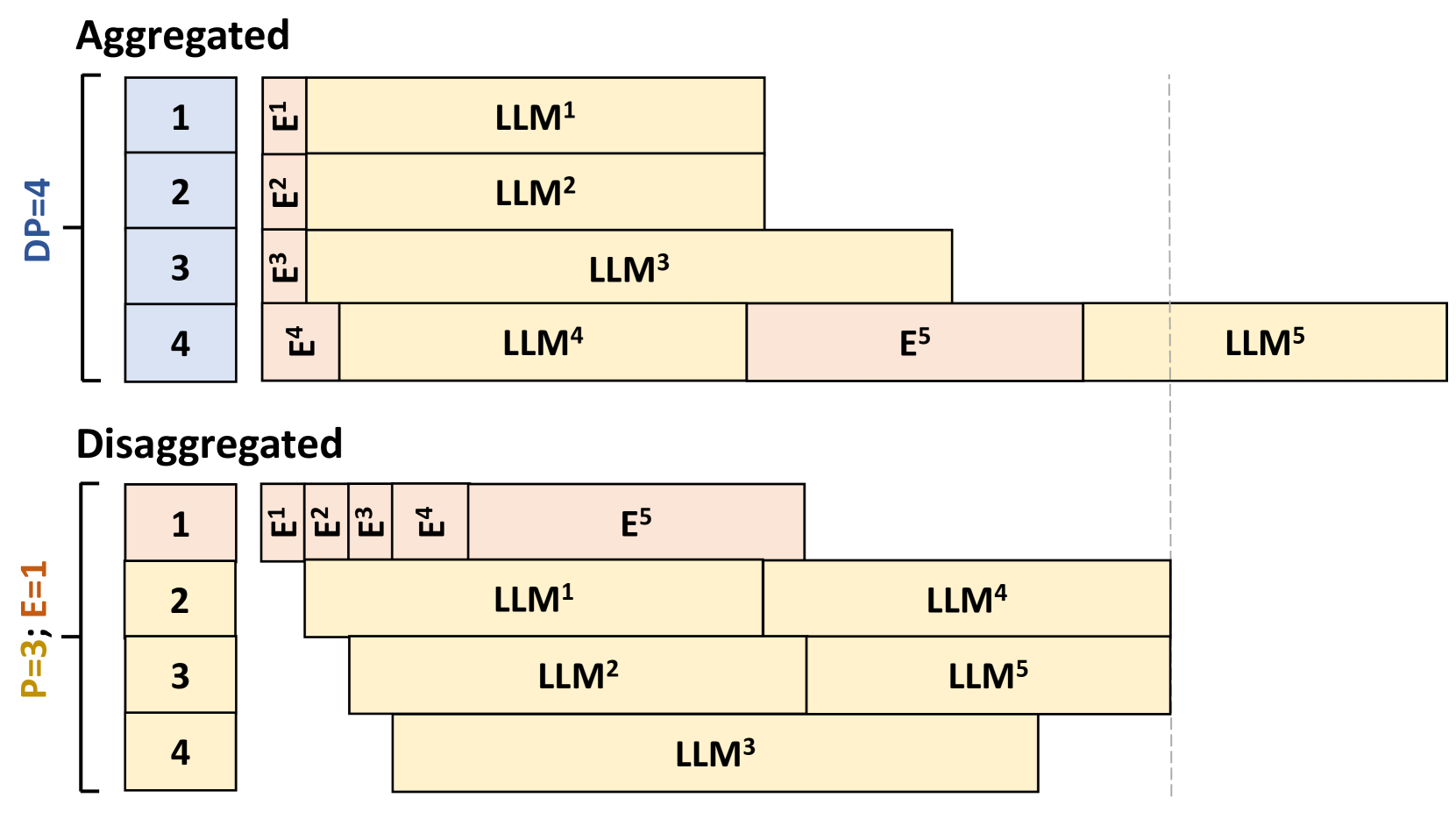
核心思路:论文的核心思路是将LMM的服务过程解耦为Encode(编码)、Prefill(预填充)和Decode(解码)三个阶段,并将这些阶段分配到不同的计算资源上。通过这种解耦,可以针对每个阶段的特点进行优化,例如,对编码阶段进行并行化处理,对预填充阶段进行缓存优化,从而提高整体的服务效率。
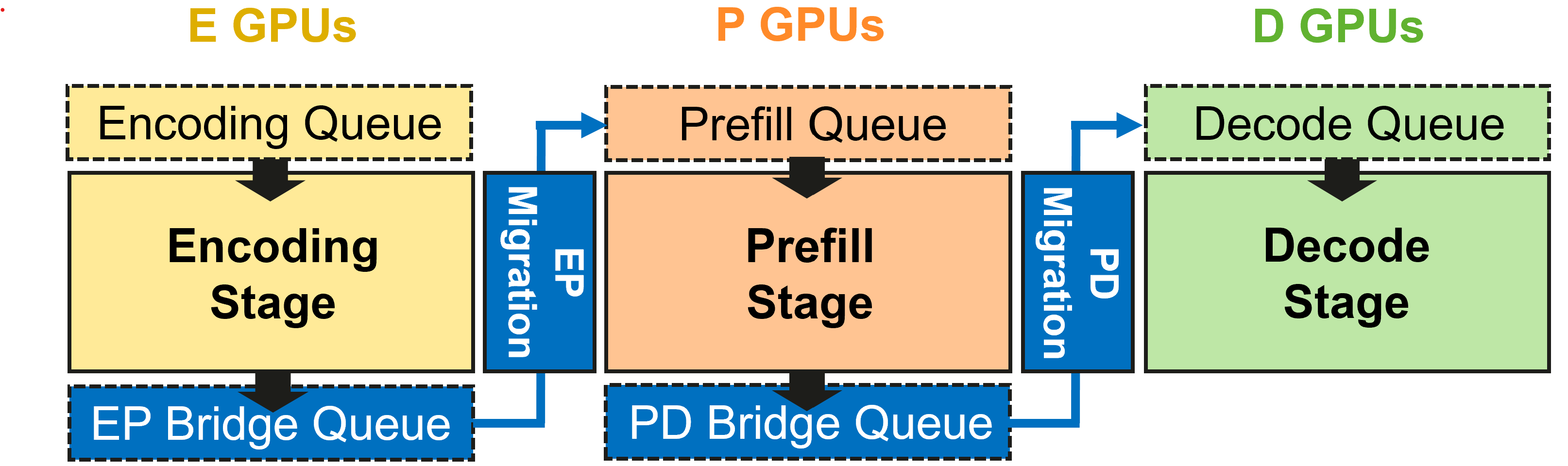
技术框架:EPD解耦框架包含三个主要阶段:编码阶段、预填充阶段和解码阶段。编码阶段负责将多模态输入(如图像、音频、视频)转换为模型可以理解的token表示。预填充阶段利用编码后的token初始化模型的上下文,为后续的解码阶段做准备。解码阶段则根据上下文生成最终的输出文本。框架还包括一个多媒体token缓存机制,用于高效传输编码后的token。此外,还设计了一个资源分配模块,用于优化各个阶段的资源分配。
关键创新:该论文的关键创新在于提出了EPD解耦框架,将LMM的服务过程分解为独立的阶段,并针对每个阶段进行优化。与现有方法相比,EPD解耦能够更好地利用计算资源,降低内存占用,并提高服务效率。此外,论文还提出了多媒体token缓存机制和资源分配模块,进一步提升了系统的性能。
关键设计:论文中涉及的关键设计包括:1) 多媒体token缓存机制,用于减少编码后的token在不同计算资源之间的传输开销;2) 并行化编码策略,用于加速编码阶段的处理速度;3) 资源分配模块,用于根据各个阶段的计算需求动态调整资源分配;4) 角色切换方法,用于处理不断变化的工作负载特征,保证系统的稳定性和高效性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,与不进行解耦的系统相比,EPD解耦框架在内存效率方面提升高达15倍,批处理大小提升高达22倍,每个请求可处理的图像数量增加10倍,KV缓存容量增加2.2倍。此外,SLO的实现提升高达90-100%,首个token生成时间(TTFT)降低高达71%。
🎯 应用场景
该研究成果可广泛应用于需要高效服务大规模多模态模型的场景,例如智能客服、多模态内容生成、视频理解和分析等。通过降低延迟和内存占用,可以提升用户体验,并降低部署和维护成本。未来,该技术有望推动多模态人工智能在更多领域的应用。
📄 摘要(原文)
Large Multimodal Models (LMMs) extend Large Language Models (LLMs) by handling diverse inputs such as images, audio, and video, but at the cost of adding a multimodal encoding stage that increases both computational and memory overhead. This step negatively affects key Service Level Objectives (SLOs), such as time to first token (TTFT) and time per output token (TPOT). We introduce Encode-Prefill-Decode (EPD) Disaggregation, a novel framework that separates the encoding, prefill, and decode stages onto dedicated resources. Unlike current systems, which bundle encoding and prefill together, our approach decouples these steps, unlocking new opportunities and optimizations. These include a mechanism to cache multimedia tokens for efficient transfer, a novel way to parallelize the encoding load within a request, a module for optimal resource allocation for disaggregated serving, and a novel role-switching method to handle changing workload characteristics. Experimental evaluations with popular LMMs show substantial gains in memory efficiency (up to 15x lower peak memory utilization), batch sizes (up to 22x larger), 10x more images per request, and 2.2x larger KV caches. Furthermore, it leads to significant improvements in SLO attainment (up to 90-100% improvement) and TTFT (up to 71% reduction), compared to systems that do not disaggregate. The code is available at https://github.com/vbdi/epdserve.