Order Matters! An Empirical Study on Large Language Models' Input Order Bias in Software Fault Localization
作者: Md Nakhla Rafi, Dong Jae Kim, Tse-Hsun Chen, Shaowei Wang
分类: cs.SE, cs.AI, cs.LG
发布日期: 2024-12-25 (更新: 2025-09-26)
💡 一句话要点
揭示大语言模型在软件缺陷定位中对输入顺序的显著偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 软件缺陷定位 输入顺序偏见 上下文管理 软件工程 自动化测试 程序分析
📋 核心要点
- 现有软件缺陷定位方法依赖人工或传统算法,效率和准确率有待提升,大语言模型在软件工程领域展现潜力。
- 该研究通过改变输入顺序和上下文大小,分析大语言模型在缺陷定位任务中存在的输入顺序偏见问题。
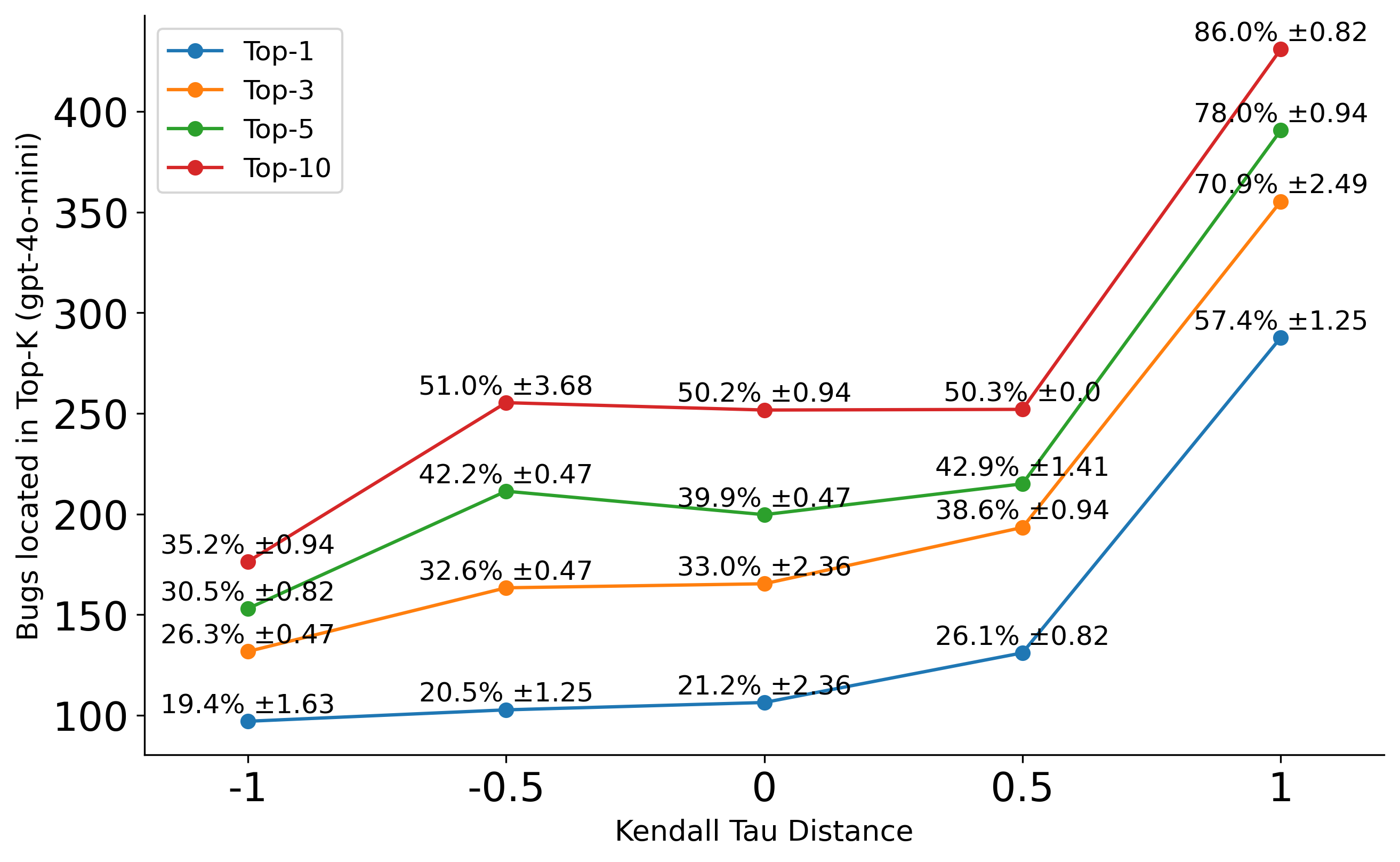
- 实验表明,输入顺序对缺陷定位准确率影响显著,优化输入方式和上下文管理能有效提升模型性能。
📝 摘要(中文)
本研究调查了输入顺序和上下文大小对大语言模型(LLM)在软件缺陷定位(FL)任务中的性能影响。通过使用Kendall Tau距离测试不同方法顺序(包括“完美”顺序和“最差”顺序),并在Java和Python项目上进行评估,结果表明LLM存在显著的顺序偏见。在Java项目中,Top-1 FL准确率从57%降至20%,在Python项目中,从38%降至约3%,当代码顺序颠倒时。将输入分解为更小的上下文有助于减少这种偏见,缩小FL性能差距。进一步研究表明,这种偏见并非由数据泄露引起。使用DepGraph排序方法实现了48%的Top-1准确率,优于其他排序方法。研究结果强调了输入结构、上下文管理和排序方法选择对于提高LLM在FL和其他软件工程任务中的性能的重要性。
🔬 方法详解
问题定义:论文旨在解决大语言模型在软件缺陷定位任务中存在的输入顺序偏见问题。现有方法在利用LLM进行缺陷定位时,忽略了输入顺序对模型性能的影响,导致结果不稳定且难以预测。这种偏见会严重影响LLM在软件工程任务中的可靠性和实用性。
核心思路:论文的核心思路是通过系统性地改变输入给LLM的代码片段的顺序,并观察模型在缺陷定位任务中的性能变化,从而揭示并量化LLM对输入顺序的敏感程度。同时,研究还探索了通过调整上下文大小来缓解这种偏见的方法。
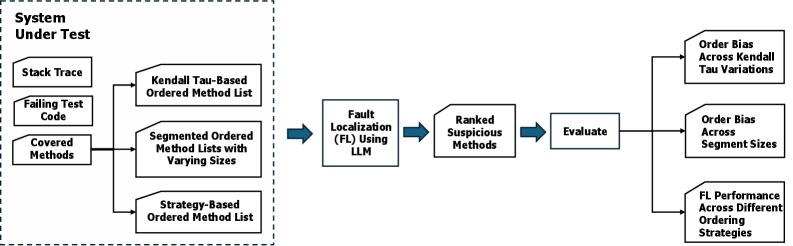
技术框架:研究采用实验方法,主要流程包括:1) 选择Java和Python项目作为基准数据集;2) 设计不同的代码片段排序策略,包括“完美”顺序(ground truth在前)和“最差”顺序(ground truth在后);3) 使用LLM进行缺陷定位,并记录Top-1准确率等指标;4) 分析不同排序策略下的性能差异,评估顺序偏见的影响;5) 尝试将输入分解为更小的上下文,观察对偏见的缓解效果;6) 通过重命名方法名等方式,排除数据泄露的可能性;7) 探索基于传统缺陷定位技术的排序方法。
关键创新:该研究最重要的技术创新在于首次系统性地揭示并量化了大语言模型在软件缺陷定位任务中对输入顺序的偏见。以往的研究主要关注模型架构和训练数据,而忽略了输入方式对性能的显著影响。该研究的发现为后续研究提供了新的视角,并为优化LLM在软件工程领域的应用提供了指导。
关键设计:研究的关键设计包括:1) 使用Kendall Tau距离来量化不同排序策略之间的差异;2) 设计“完美”和“最差”等极端排序策略,以突出顺序偏见的影响;3) 通过分解上下文来探索缓解偏见的方法;4) 通过重命名方法名来排除数据泄露的可能性;5) 采用Top-1准确率作为主要的性能评估指标。
🖼️ 关键图片

📊 实验亮点
实验结果表明,输入顺序对LLM的缺陷定位性能影响显著。在Java项目中,Top-1准确率从57%(完美顺序)降至20%(最差顺序),在Python项目中,从38%降至约3%。通过分解上下文,可以将性能差距从22%缩小到1%。使用DepGraph排序方法实现了48%的Top-1准确率,优于其他排序方法。
🎯 应用场景
该研究成果可应用于提升基于大语言模型的自动化软件缺陷定位工具的准确性和可靠性。通过优化输入顺序和上下文管理,可以显著提高缺陷定位的效率,降低软件维护成本。此外,该研究也为其他软件工程任务中LLM的应用提供了参考,例如代码生成、代码审查和自动程序修复。
📄 摘要(原文)
Large Language Models (LLMs) show great promise in software engineering tasks like Fault Localization (FL) and Automatic Program Repair (APR). This study investigates the impact of input order and context size on LLM performance in FL, a crucial step for many downstream software engineering tasks. We test different orders for methods using Kendall Tau distances, including "perfect" (where ground truths come first) and "worst" (where ground truths come last), using two benchmarks that consist of both Java and Python projects. Our results indicate a significant bias in order; Top-1 FL accuracy in Java projects drops from 57% to 20%, while in Python projects, it decreases from 38% to approximately 3% when we reverse the code order. Breaking down inputs into smaller contexts helps reduce this bias, narrowing the performance gap in FL from 22% to 6% and then to just 1% on both benchmarks. We then investigated whether the bias in order was caused by data leakage by renaming the method names with more meaningful alternatives. Our findings indicated that the trend remained consistent, suggesting that the bias was not due to data leakage. We also look at ordering methods based on traditional FL techniques and metrics. Ordering using DepGraph's ranking achieves 48% Top-1 accuracy, which is better than more straightforward ordering approaches like CallGraphDFS. These findings underscore the importance of how we structure inputs, manage contexts, and choose ordering methods to improve LLM performance in FL and other software engineering tasks.