SAFLITE: Fuzzing Autonomous Systems via Large Language Models
作者: Taohong Zhu, Adrians Skapars, Fardeen Mackenzie, Declan Kehoe, William Newton, Suzanne Embury, Youcheng Sun
分类: cs.SE, cs.AI, eess.SY
发布日期: 2024-12-25
💡 一句话要点
SaFliTe:利用大语言模型提升自治系统模糊测试效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模糊测试 自治系统 大语言模型 安全测试 无人机
📋 核心要点
- 自治系统模糊测试面临搜索空间巨大和状态空间复杂等挑战,传统方法难以有效发现漏洞。
- SaFliTe利用大语言模型评估测试用例与安全目标的相关性,预测其触发漏洞的潜力,从而指导模糊测试。
- 实验表明,SaFliTe显著提升了多种模糊测试工具在无人机控制系统上的漏洞发现能力,平均提升高达93.1%。
📝 摘要(中文)
模糊测试是一种有效的软件漏洞发现方法。然而,由于自治系统(AS)具有巨大的搜索空间和复杂的状态空间,反映了现实世界环境的不可预测性和复杂性,因此模糊测试在自治系统领域面临挑战。本文提出了一个通用框架,旨在提高自治系统模糊测试的效率。该框架的核心是SaFliTe,一个预测组件,用于评估测试用例是否满足预定义的安全性标准。SaFliTe利用大语言模型(LLM)以及关于测试目标和AS状态的信息来评估每个测试用例的相关性。我们通过使用各种LLM(包括GPT-3.5、Mistral-7B和Llama2-7B)实例化SaFliTe,并将其集成到四种模糊测试工具(PGFuzz、DeepHyperion-UAV、CAMBA和TUMB)中来评估SaFliTe。这些工具专门用于测试自治无人机控制系统,例如ArduPilot、PX4和PX4-Avoidance。实验结果表明,与PGFuzz相比,SaFliTe将每次模糊测试迭代中触发错误发生的操作选择可能性平均提高了93.1%。此外,在集成SaFliTe后,DeepHyperion-UAV、CAMBA和TUMB生成导致系统违规的测试用例的能力分别提高了234.5%、33.3%和17.8%。此评估的基准来自无人机测试竞赛。
🔬 方法详解
问题定义:现有自治系统模糊测试方法面临高维状态空间和复杂环境交互带来的挑战,导致测试效率低下,难以有效发现潜在的安全漏洞。传统方法难以区分测试用例的优劣,导致大量无效测试,浪费计算资源。
核心思路:SaFliTe的核心在于利用大语言模型(LLM)的强大语义理解和推理能力,对模糊测试生成的测试用例进行评估,预测其是否可能触发系统违规行为。通过LLM对测试用例的“安全性”进行打分,引导模糊测试器优先选择更有可能发现漏洞的测试用例。
技术框架:SaFliTe作为一个预测组件,可以集成到现有的模糊测试框架中。其主要流程包括:1)模糊测试器生成新的测试用例;2)SaFliTe接收测试用例和系统状态信息;3)LLM根据预定义的安全性标准评估测试用例的相关性,输出一个安全评分;4)模糊测试器根据SaFliTe提供的评分,选择更有可能触发漏洞的测试用例进行下一步测试。
关键创新:SaFliTe的关键创新在于将大语言模型引入到自治系统模糊测试中,利用LLM对测试用例进行智能评估,从而显著提升了模糊测试的效率和漏洞发现能力。与传统方法相比,SaFliTe能够更有效地利用计算资源,发现更深层次的系统漏洞。
关键设计:SaFliTe的关键设计包括:1)LLM的选择:论文尝试了GPT-3.5、Mistral-7B和Llama2-7B等多种LLM;2)提示工程:设计合适的提示语,引导LLM准确评估测试用例的安全性;3)评分机制:定义合理的评分标准,将LLM的输出转化为可用于指导模糊测试的数值评分。
🖼️ 关键图片
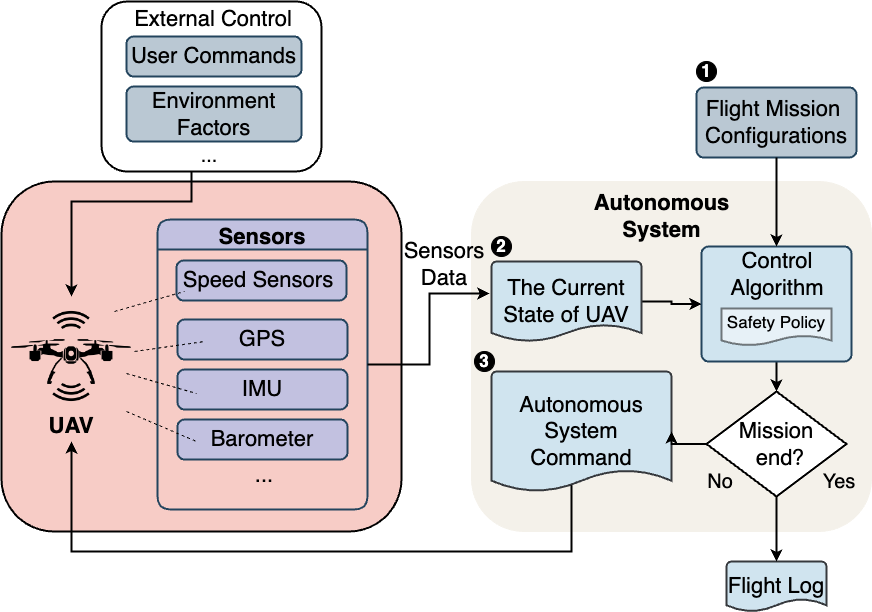

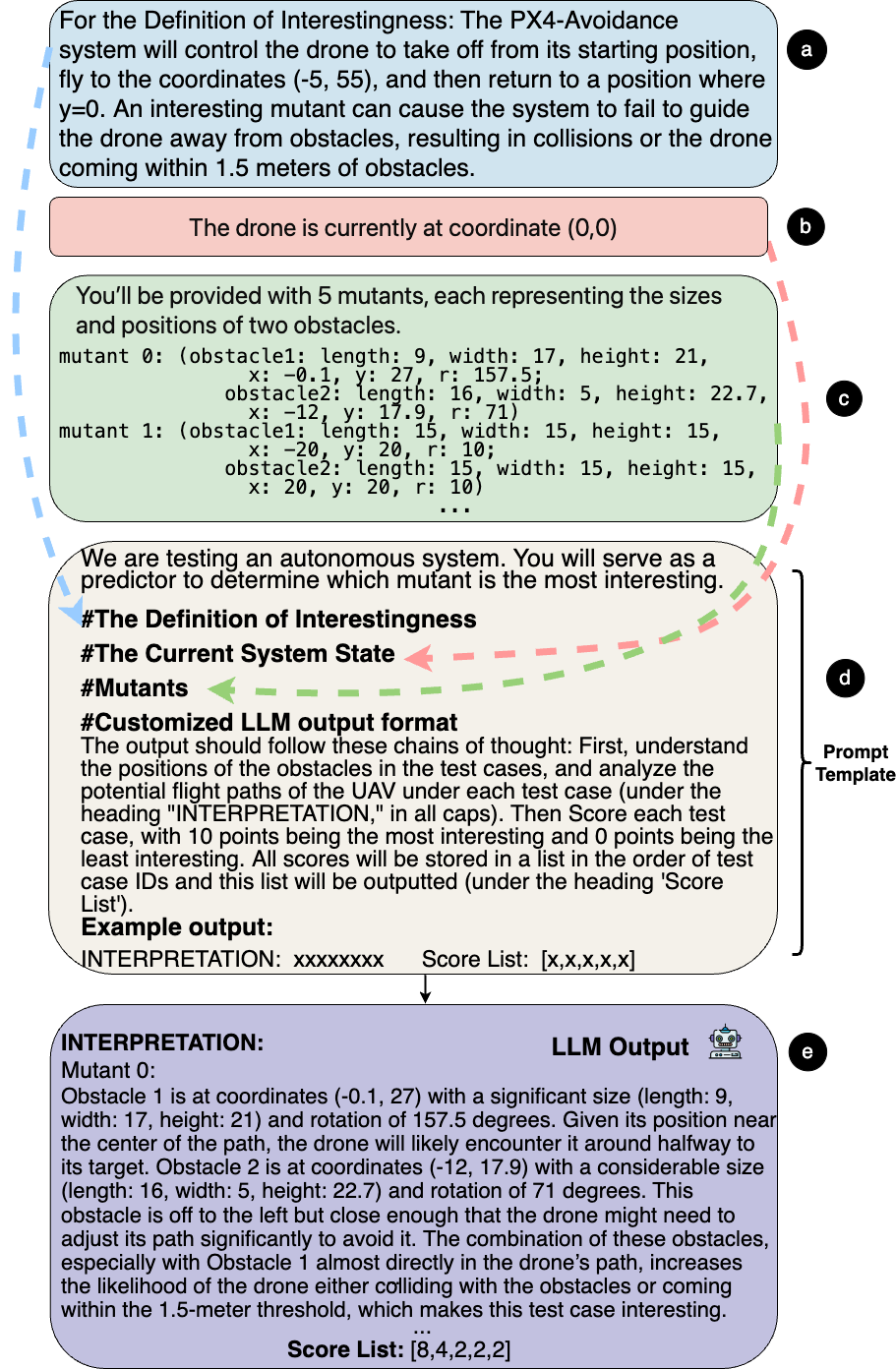
📊 实验亮点
实验结果表明,SaFliTe能够显著提升模糊测试的效率。与PGFuzz相比,SaFliTe将每次模糊测试迭代中触发错误发生的操作选择可能性平均提高了93.1%。此外,在集成SaFliTe后,DeepHyperion-UAV、CAMBA和TUMB生成导致系统违规的测试用例的能力分别提高了234.5%、33.3%和17.8%。
🎯 应用场景
SaFliTe可广泛应用于各种自治系统的安全测试,例如无人驾驶汽车、机器人、智能家居等。通过提高模糊测试的效率,SaFliTe能够帮助开发者更早地发现和修复系统漏洞,从而提升自治系统的安全性和可靠性,降低安全风险。该研究对推动自治系统的安全发展具有重要意义。
📄 摘要(原文)
Fuzz testing effectively uncovers software vulnerabilities; however, it faces challenges with Autonomous Systems (AS) due to their vast search spaces and complex state spaces, which reflect the unpredictability and complexity of real-world environments. This paper presents a universal framework aimed at improving the efficiency of fuzz testing for AS. At its core is SaFliTe, a predictive component that evaluates whether a test case meets predefined safety criteria. By leveraging the large language model (LLM) with information about the test objective and the AS state, SaFliTe assesses the relevance of each test case. We evaluated SaFliTe by instantiating it with various LLMs, including GPT-3.5, Mistral-7B, and Llama2-7B, and integrating it into four fuzz testing tools: PGFuzz, DeepHyperion-UAV, CAMBA, and TUMB. These tools are designed specifically for testing autonomous drone control systems, such as ArduPilot, PX4, and PX4-Avoidance. The experimental results demonstrate that, compared to PGFuzz, SaFliTe increased the likelihood of selecting operations that triggered bug occurrences in each fuzzing iteration by an average of 93.1\%. Additionally, after integrating SaFliTe, the ability of DeepHyperion-UAV, CAMBA, and TUMB to generate test cases that caused system violations increased by 234.5\%, 33.3\%, and 17.8\%, respectively. The benchmark for this evaluation was sourced from a UAV Testing Competition.