DeepCRCEval: Revisiting the Evaluation of Code Review Comment Generation
作者: Junyi Lu, Xiaojia Li, Zihan Hua, Lei Yu, Shiqi Cheng, Li Yang, Fengjun Zhang, Chun Zuo
分类: cs.SE, cs.AI, cs.CL, cs.LG
发布日期: 2024-12-24 (更新: 2025-01-25)
备注: Accepted to the 28th International Conference on Fundamental Approaches to Software Engineering (FASE 2025), part of the 28th European Joint Conferences on Theory and Practice of Software (ETAPS 2025)
💡 一句话要点
DeepCRCEval:重新审视代码审查评论生成评估方法,提出更可靠的评估框架。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码审查 评论生成 评估框架 大型语言模型 软件工程
📋 核心要点
- 现有代码审查评论生成评估主要依赖文本相似度,但人工评论质量不稳定,且相似度与代码质量提升关联弱。
- DeepCRCEval框架结合人工评估和大型语言模型,基于新标准全面评估现有技术,并提出LLM-Reviewer基线。
- 实验表明文本相似度指标局限性大,DeepCRCEval能有效区分评论质量,且LLM评估器显著提升评估效率。
📝 摘要(中文)
代码审查是软件开发中至关重要但要求很高的环节,因此自动生成审查评论引起了广泛关注。然而,传统的评估方法主要基于文本相似性,面临两大挑战:开源项目中人工撰写的评论质量参差不齐,以及文本相似性与提高代码质量、检测缺陷等目标的相关性较弱。本研究利用一套基于先前研究和开发者访谈的新标准,对基准评论进行了实证分析,并以此重新评估了现有方法。我们提出了DeepCRCEval评估框架,结合人工评估员和大型语言模型(LLM),基于设定的标准对当前技术进行全面重新评估。此外,我们还引入了一种创新且高效的基线方法LLM-Reviewer,利用LLM的少样本学习能力进行目标导向的比较。研究表明,文本相似性指标存在局限性,只有不到10%的基准评论适合自动化。相比之下,DeepCRCEval能有效区分高质量和低质量评论,是一种更可靠的评估机制。将LLM评估器纳入DeepCRCEval显著提高了效率,分别降低了88.78%和90.32%的时间和成本。此外,LLM-Reviewer展示了在评论生成中关注任务实际目标的巨大潜力。
🔬 方法详解
问题定义:现有代码审查评论生成模型的评估主要依赖于文本相似度指标,例如BLEU、ROUGE等。然而,这些指标并不能很好地反映评论的实际质量,因为人工撰写的评论本身质量参差不齐,而且文本相似度与代码质量提升、缺陷检测等目标的相关性较弱。因此,如何更可靠地评估代码审查评论生成模型是一个亟待解决的问题。
核心思路:论文的核心思路是提出一种更可靠的评估框架DeepCRCEval,该框架结合了人工评估和大型语言模型(LLM)评估,并基于一套新的评估标准。这些标准来源于先前的研究和开发者访谈,旨在更全面地衡量评论的质量。此外,论文还提出了一个基于LLM的基线模型LLM-Reviewer,用于目标导向的比较,即直接优化评论对代码质量的提升效果。
技术框架:DeepCRCEval框架主要包含以下几个模块:1) 基准评论数据集的分析,使用新的评估标准对现有基准评论进行质量评估;2) 人工评估模块,由人工评估员根据设定的标准对生成的评论进行评估;3) LLM评估模块,利用大型语言模型自动评估生成的评论,以提高评估效率;4) LLM-Reviewer基线模型,利用LLM的少样本学习能力生成目标导向的评论。
关键创新:论文的关键创新在于提出了DeepCRCEval评估框架,该框架能够更可靠地评估代码审查评论生成模型的性能。与传统的基于文本相似度的评估方法相比,DeepCRCEval考虑了评论的实际质量和对代码质量的潜在影响。此外,利用LLM进行自动评估可以显著提高评估效率,降低成本。LLM-Reviewer基线模型也展示了LLM在代码审查评论生成方面的潜力。
关键设计:DeepCRCEval的关键设计包括:1) 新的评估标准,这些标准来源于先前的研究和开发者访谈,旨在更全面地衡量评论的质量,例如是否清晰、是否具有建设性、是否能够帮助发现缺陷等;2) LLM评估器的选择和训练,论文选择了合适的LLM,并对其进行微调,使其能够更好地评估代码审查评论;3) LLM-Reviewer基线模型的设计,该模型利用LLM的少样本学习能力,通过提供一些高质量的评论示例,引导LLM生成目标导向的评论。
🖼️ 关键图片
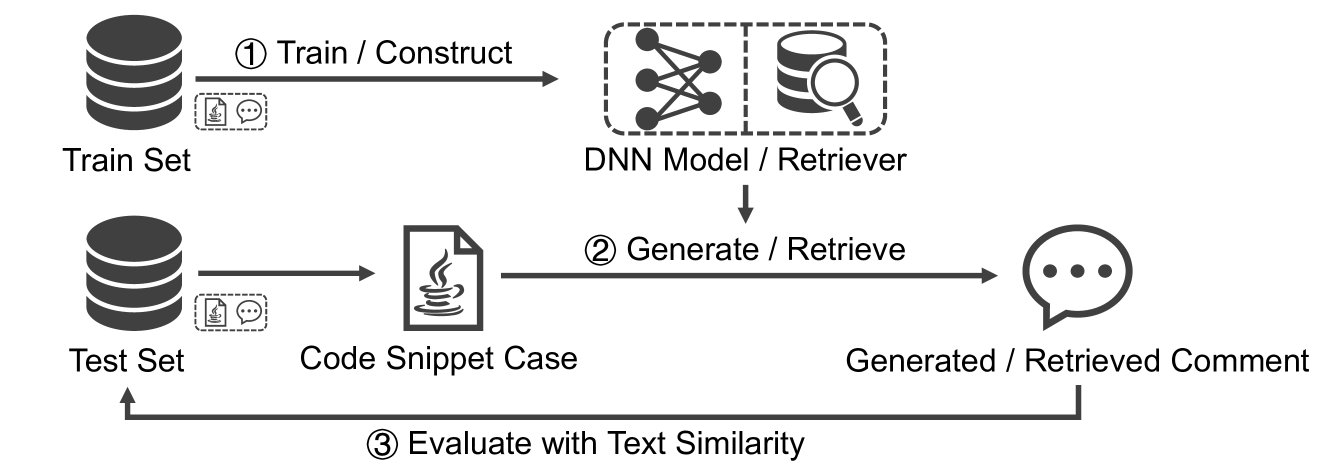


📊 实验亮点
实验结果表明,只有不到10%的基准评论适合自动化生成,传统的文本相似度指标无法有效区分高质量和低质量评论。DeepCRCEval框架能够更可靠地评估代码审查评论生成模型的性能,并且利用LLM评估器可以将评估时间和成本分别降低88.78%和90.32%。LLM-Reviewer基线模型也展示了在评论生成中关注任务实际目标的巨大潜力。
🎯 应用场景
该研究成果可应用于自动化代码审查工具的开发和评估,帮助开发者更有效地进行代码审查,提高代码质量,减少缺陷。通过DeepCRCEval框架,可以更准确地评估代码审查评论生成模型的性能,从而推动相关技术的发展。此外,LLM-Reviewer基线模型展示了LLM在代码审查领域的巨大潜力,未来可用于构建更智能的代码审查助手。
📄 摘要(原文)
Code review is a vital but demanding aspect of software development, generating significant interest in automating review comments. Traditional evaluation methods for these comments, primarily based on text similarity, face two major challenges: inconsistent reliability of human-authored comments in open-source projects and the weak correlation of text similarity with objectives like enhancing code quality and detecting defects. This study empirically analyzes benchmark comments using a novel set of criteria informed by prior research and developer interviews. We then similarly revisit the evaluation of existing methodologies. Our evaluation framework, DeepCRCEval, integrates human evaluators and Large Language Models (LLMs) for a comprehensive reassessment of current techniques based on the criteria set. Besides, we also introduce an innovative and efficient baseline, LLM-Reviewer, leveraging the few-shot learning capabilities of LLMs for a target-oriented comparison. Our research highlights the limitations of text similarity metrics, finding that less than 10% of benchmark comments are high quality for automation. In contrast, DeepCRCEval effectively distinguishes between high and low-quality comments, proving to be a more reliable evaluation mechanism. Incorporating LLM evaluators into DeepCRCEval significantly boosts efficiency, reducing time and cost by 88.78% and 90.32%, respectively. Furthermore, LLM-Reviewer demonstrates significant potential of focusing task real targets in comment generation.