Trustworthy and Efficient LLMs Meet Databases
作者: Kyoungmin Kim, Anastasia Ailamaki
分类: cs.DB, cs.AI
发布日期: 2024-12-23
💡 一句话要点
提升LLM在数据库应用中的可信度和效率:方法综述与未来方向
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 可信度 效率 数据库 推理 幻觉 知识库
📋 核心要点
- 大型语言模型(LLM)在推理过程中产生幻觉,即输出看似合理但错误的答案,是其在实际应用中的主要挑战。
- 本教程旨在介绍提升LLM可信度和效率的方法,并探讨LLM与数据库结合的新机遇和挑战,为数据库社区提供参考。
- 通过分享LLM的基本概念和策略,本教程旨在降低数据库研究人员和从业者对LLM的陌生感,并鼓励他们参与相关研究。
📝 摘要(中文)
随着以大型语言模型(LLM)为核心的人工智能时代的快速发展,提高LLM的可信度和效率,尤其是在输出生成(推理)方面,受到了广泛关注。这是为了减少LLM看似合理但错误的输出(即幻觉),并满足日益增长的推理需求。本教程探讨了这些努力,并向数据库社区公开它们。理解这些努力对于在数据库任务中利用LLM以及调整数据库技术以适应LLM至关重要。此外,我们深入研究了LLM和数据库之间的协同作用,强调了它们交叉领域中的新机遇和挑战。本教程旨在与数据库研究人员和从业人员分享关于LLM的基本概念和策略,减少对LLM的陌生感,并激发他们参与LLM和数据库之间的交叉研究。
🔬 方法详解
问题定义:LLM在输出生成(推理)过程中,会产生看似合理但错误的输出,即“幻觉”现象。同时,日益增长的推理需求对LLM的效率提出了更高的要求。现有方法在可信度和效率之间难以取得平衡,限制了LLM在数据库任务中的应用。
核心思路:本教程的核心思路是系统性地梳理和介绍提升LLM可信度和效率的方法,并探讨LLM与数据库结合的潜在协同效应。通过降低数据库社区对LLM的陌生感,激发他们在相关领域的创新。
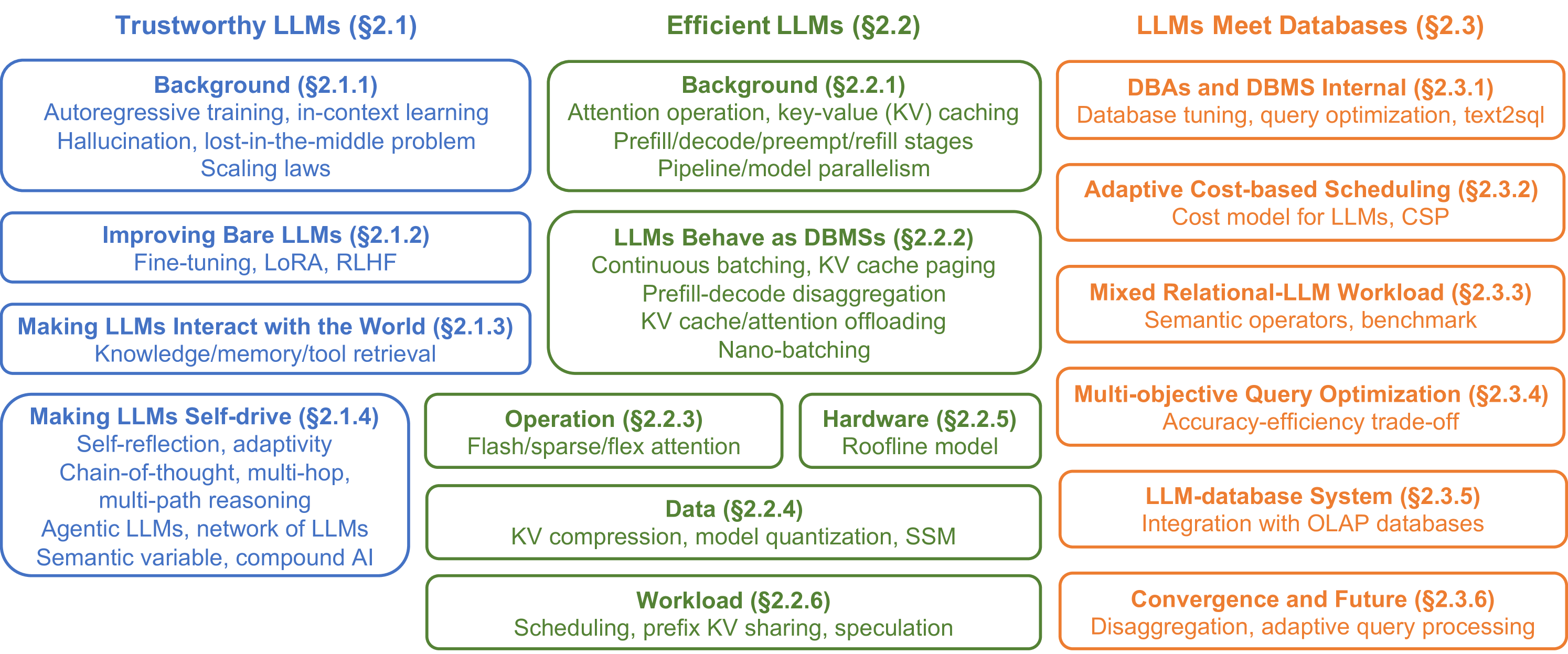
技术框架:本教程主要包含以下几个部分:1) LLM可信度提升方法,包括减少幻觉的技术;2) LLM效率提升方法,包括推理加速技术;3) LLM与数据库的协同应用,包括利用LLM进行数据库查询优化、数据集成等;4) LLM与数据库交叉领域的新机遇和挑战。
关键创新:本教程的关键创新在于其综述性和前瞻性。它不仅总结了现有的LLM可信度和效率提升方法,还探讨了LLM与数据库结合的未来发展方向,为数据库研究人员提供了新的研究思路。
关键设计:本教程没有提出新的算法或模型,而是侧重于对现有技术的梳理和总结。具体的技术细节,例如减少幻觉的方法、推理加速的技术、数据库查询优化方法等,会在教程中进行详细介绍。由于是教程性质,具体参数设置、损失函数、网络结构等细节取决于所介绍的特定技术。
🖼️ 关键图片
📊 实验亮点
本教程重点在于对现有技术的系统性梳理和未来方向的展望,而非具体的实验结果。其价值在于为数据库研究人员提供了一个快速了解LLM及其在数据库领域应用潜力的入口,并激发他们在相关领域进行创新研究。
🎯 应用场景
该研究具有广泛的应用前景,包括智能问答系统、数据分析与挖掘、数据库查询优化、知识图谱构建等。通过提高LLM的可信度和效率,可以使其更好地服务于数据库应用,从而提升数据处理和分析的智能化水平,为各行业带来实际价值。未来,LLM与数据库的深度融合将推动数据管理和人工智能技术的进一步发展。
📄 摘要(原文)
In the rapidly evolving AI era with large language models (LLMs) at the core, making LLMs more trustworthy and efficient, especially in output generation (inference), has gained significant attention. This is to reduce plausible but faulty LLM outputs (a.k.a hallucinations) and meet the highly increased inference demands. This tutorial explores such efforts and makes them transparent to the database community. Understanding these efforts is essential in harnessing LLMs in database tasks and adapting database techniques to LLMs. Furthermore, we delve into the synergy between LLMs and databases, highlighting new opportunities and challenges in their intersection. This tutorial aims to share with database researchers and practitioners essential concepts and strategies around LLMs, reduce the unfamiliarity of LLMs, and inspire joining in the intersection between LLMs and databases.