Dynamic Multi-Agent Orchestration and Retrieval for Multi-Source Question-Answer Systems using Large Language Models
作者: Antony Seabra, Claudio Cavalcante, Joao Nepomuceno, Lucas Lago, Nicolaas Ruberg, Sergio Lifschitz
分类: cs.AI
发布日期: 2024-12-23
备注: International Conference on NLP, AI, Computer Science & Engineering (NLAICSE 2024)
💡 一句话要点
提出一种动态多Agent协同检索方法,用于多源问答系统,提升复杂场景下的问答准确率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多Agent系统 大型语言模型 检索增强生成 多源问答 动态检索
📋 核心要点
- 现有问答系统难以有效整合来自非结构化文档和结构化数据库等多种数据源的信息。
- 提出一种动态多Agent协同检索方法,利用SQL Agent、RAG Agent和路由Agent等,动态选择最佳检索策略。
- 在合同管理领域验证了该方法的有效性,结果表明该方法提高了响应的准确性和相关性。
📝 摘要(中文)
本文提出了一种结合大型语言模型(LLM)检索的先进技术,以支持开发稳健的多源问答系统的方法。该方法旨在通过协同的多Agent编排和动态检索方法,整合来自不同数据源的信息,包括非结构化文档(PDF)和结构化数据库。该方法利用专门的Agent,如SQL Agent、检索增强生成(RAG)Agent和路由Agent,这些Agent基于每个查询的性质动态选择最合适的检索策略。为了进一步提高准确性和上下文相关性,我们采用了动态提示工程,该工程实时适应于特定查询的上下文。该方法在合同管理领域得到了验证,在该领域中,复杂的查询通常需要非结构化和结构化数据之间的无缝交互。结果表明,该方法提高了响应的准确性和相关性,为开发可在各种领域和数据源中运行的问答系统提供了一个通用且可扩展的框架。
🔬 方法详解
问题定义:论文旨在解决多源问答系统中,如何有效整合来自不同数据源(如非结构化文档和结构化数据库)的信息,并准确回答复杂查询的问题。现有方法在处理此类问题时,难以根据查询的特性动态选择合适的检索策略,导致准确率和相关性较低。
核心思路:论文的核心思路是利用多Agent协同编排和动态检索,构建一个能够根据查询类型和数据源特点,灵活选择最佳检索策略的问答系统。通过引入不同类型的Agent(如SQL Agent、RAG Agent和路由Agent),实现对结构化和非结构化数据的有效处理和整合。
技术框架:整体框架包含以下几个主要模块:1) 查询接收模块:接收用户提出的问题。2) 路由Agent:根据查询的性质,动态选择合适的Agent进行处理。3) SQL Agent:负责处理结构化数据,执行SQL查询。4) RAG Agent:负责处理非结构化数据,利用检索增强生成技术生成答案。5) 动态提示工程模块:根据查询上下文,动态调整提示词,提高答案的准确性和相关性。6) 答案生成模块:整合各个Agent的输出,生成最终答案。
关键创新:该方法最重要的技术创新点在于动态多Agent协同编排和检索机制。与传统的单Agent或静态检索方法相比,该方法能够根据查询的特性,动态选择最合适的Agent和检索策略,从而提高问答系统的灵活性和准确性。此外,动态提示工程也进一步提升了答案的上下文相关性。
关键设计:路由Agent的设计是关键。路由Agent需要能够准确判断查询的类型和所需的数据源,并选择合适的Agent进行处理。这可能涉及到对查询进行语义分析,并根据预定义的规则或机器学习模型进行决策。此外,动态提示工程需要根据查询上下文,生成合适的提示词,这可能涉及到对查询进行关键词提取和语义理解,并利用大型语言模型生成提示词。
🖼️ 关键图片
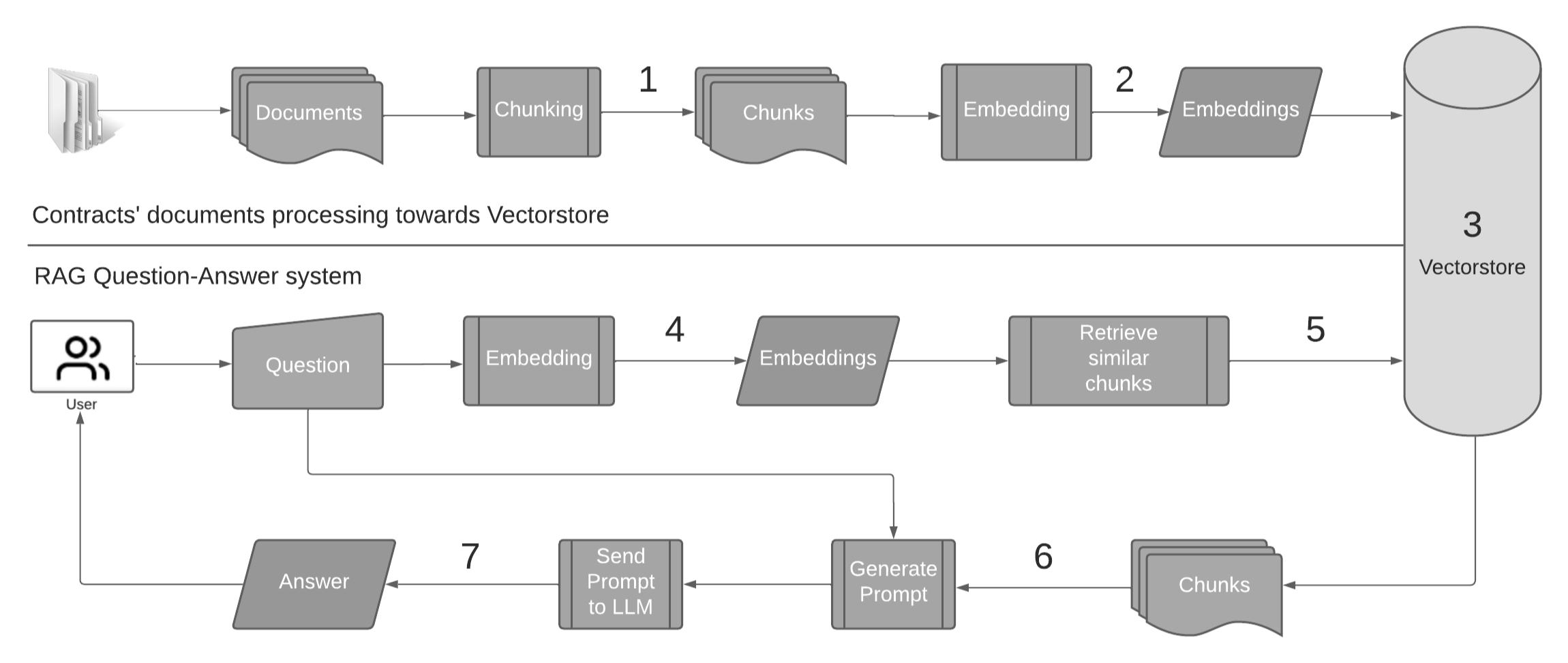


📊 实验亮点
论文在合同管理领域进行了实验验证,结果表明该方法能够有效提高响应的准确性和相关性。虽然论文中没有给出具体的性能数据和对比基线,但强调了该方法在处理复杂查询时,能够实现非结构化和结构化数据之间的无缝交互,从而提升问答系统的整体性能。
🎯 应用场景
该研究成果可广泛应用于需要整合多源数据的问答系统,例如合同管理、客户服务、知识库问答等领域。通过提高问答的准确性和效率,可以显著提升用户体验,并为企业节省时间和成本。未来,该方法可以进一步扩展到更多领域,并与其他技术(如知识图谱)相结合,构建更加智能和强大的问答系统。
📄 摘要(原文)
We propose a methodology that combines several advanced techniques in Large Language Model (LLM) retrieval to support the development of robust, multi-source question-answer systems. This methodology is designed to integrate information from diverse data sources, including unstructured documents (PDFs) and structured databases, through a coordinated multi-agent orchestration and dynamic retrieval approach. Our methodology leverages specialized agents-such as SQL agents, Retrieval-Augmented Generation (RAG) agents, and router agents - that dynamically select the most appropriate retrieval strategy based on the nature of each query. To further improve accuracy and contextual relevance, we employ dynamic prompt engineering, which adapts in real time to query-specific contexts. The methodology's effectiveness is demonstrated within the domain of Contract Management, where complex queries often require seamless interaction between unstructured and structured data. Our results indicate that this approach enhances response accuracy and relevance, offering a versatile and scalable framework for developing question-answer systems that can operate across various domains and data sources.