Survey of Large Multimodal Model Datasets, Application Categories and Taxonomy
作者: Priyaranjan Pattnayak, Hitesh Laxmichand Patel, Bhargava Kumar, Amit Agarwal, Ishan Banerjee, Srikant Panda, Tejaswini Kumar
分类: cs.AI, cs.CV, cs.LG
发布日期: 2024-12-23
💡 一句话要点
综述大规模多模态模型数据集、应用类别与分类体系,促进多模态学习研究。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大规模数据集 数据集综述 人工智能 基准测试
📋 核心要点
- 多模态学习旨在融合多种数据类型,但缺乏系统性的数据集整理与分析。
- 该综述通过调研现有数据集,构建多模态数据集的分类体系,为研究提供参考。
- 综述强调了大规模数据集和基准测试在多模态模型训练和评估中的关键作用。
📝 摘要(中文)
多模态学习是人工智能领域一个快速发展的方向,旨在通过整合和分析文本、图像、音频和视频等多种类型的数据,构建更通用和鲁棒的系统。受到人类通过多种感官吸收信息能力的启发,该方法支持文本到视频转换、视觉问答和图像描述等应用。本综述重点介绍了支持多模态语言模型(MLLM)的最新数据集进展。大规模多模态数据集至关重要,因为它们允许对这些模型进行彻底的测试和训练。本研究着重于这些数据集对该领域的贡献,考察了各种数据集,包括用于训练、特定领域任务和实际应用的数据集。它还强调了基准数据集对于评估模型在各种场景、可扩展性和适用性方面的性能至关重要。由于多模态学习始终在变化,克服这些障碍将有助于人工智能研究和应用达到新的高度。
🔬 方法详解
问题定义:目前多模态学习领域缺乏对现有大规模数据集的系统性梳理和分类,研究人员难以快速了解和选择合适的数据集进行模型训练和评估。现有方法通常关注特定任务或模态,缺乏对多模态数据集的整体性视角。
核心思路:该综述的核心思路是对现有的大规模多模态数据集进行全面的调研和整理,并根据其特性(如数据类型、规模、应用领域等)构建一个分类体系。通过对这些数据集的分析,为研究人员提供一个清晰的概览,帮助他们更好地选择和利用这些数据资源。
技术框架:该综述没有提出新的模型或算法,而是一个对现有数据集的整理和分析。其框架主要包括以下几个阶段:1) 数据集收集:收集当前主流的大规模多模态数据集;2) 特征提取:提取每个数据集的关键特征,如数据类型、规模、标注信息、应用领域等;3) 分类体系构建:基于提取的特征,构建一个多层次的分类体系,将数据集划分为不同的类别;4) 分析与总结:对每个类别的数据集进行分析和总结,指出其优缺点和适用场景。
关键创新:该综述的创新点在于其对大规模多模态数据集的系统性整理和分类。它提供了一个全面的视角,帮助研究人员更好地了解和利用这些数据资源。此外,该综述还强调了基准测试在多模态模型评估中的重要性,并对现有基准数据集进行了分析。
关键设计:该综述的关键设计在于其分类体系的构建。具体的分类标准和层次结构未知,但可以推测其可能包括数据类型(如图像、文本、音频、视频)、应用领域(如视觉问答、图像描述、文本到视频生成)和数据集规模等因素。
🖼️ 关键图片

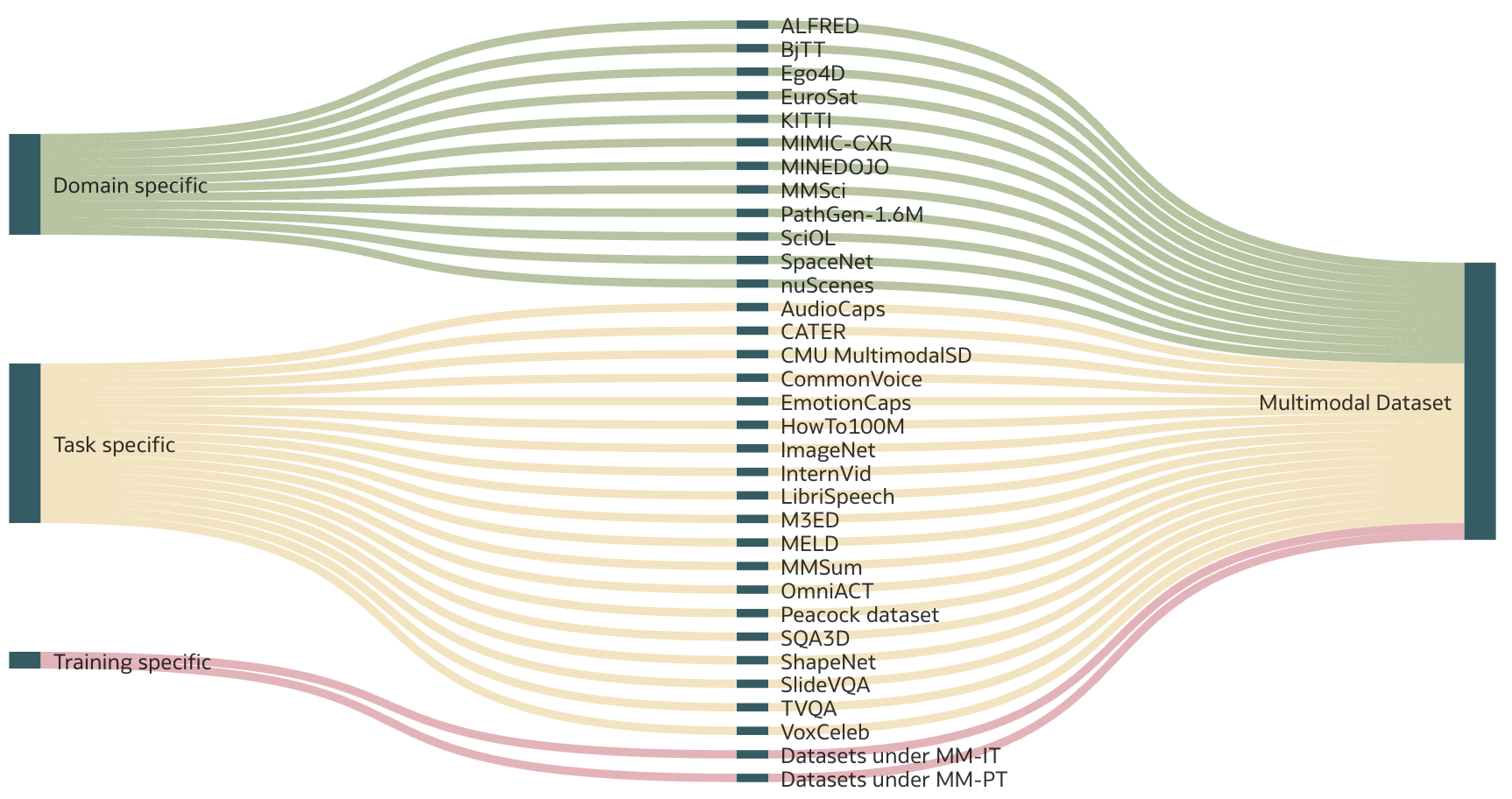
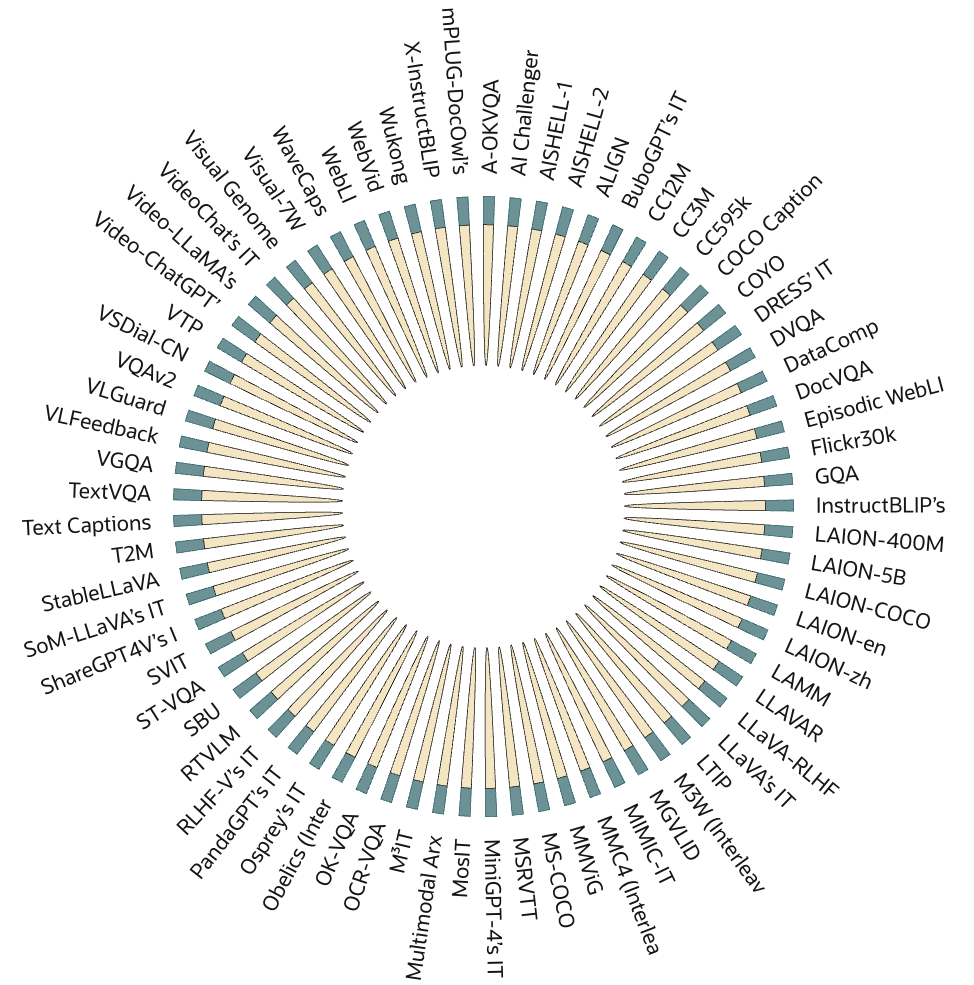
📊 实验亮点
由于是综述类文章,没有具体的实验结果。其亮点在于对现有大规模多模态数据集进行了系统性的整理和分类,为研究人员提供了一个全面的资源概览。具体的数据集数量、规模和分类标准未知,但该综述为后续研究奠定了基础。
🎯 应用场景
该综述的研究成果可广泛应用于多模态人工智能模型的开发和评估。通过提供全面的数据集概览和分类,研究人员可以更高效地选择合适的数据集进行模型训练,加速多模态学习算法的研发进程。此外,该综述强调的基准测试对于模型性能评估和比较具有重要意义,有助于推动多模态学习领域的标准化和规范化。
📄 摘要(原文)
Multimodal learning, a rapidly evolving field in artificial intelligence, seeks to construct more versatile and robust systems by integrating and analyzing diverse types of data, including text, images, audio, and video. Inspired by the human ability to assimilate information through many senses, this method enables applications such as text-to-video conversion, visual question answering, and image captioning. Recent developments in datasets that support multimodal language models (MLLMs) are highlighted in this overview. Large-scale multimodal datasets are essential because they allow for thorough testing and training of these models. With an emphasis on their contributions to the discipline, the study examines a variety of datasets, including those for training, domain-specific tasks, and real-world applications. It also emphasizes how crucial benchmark datasets are for assessing models' performance in a range of scenarios, scalability, and applicability. Since multimodal learning is always changing, overcoming these obstacles will help AI research and applications reach new heights.