Large Language Model Safety: A Holistic Survey
作者: Dan Shi, Tianhao Shen, Yufei Huang, Zhigen Li, Yongqi Leng, Renren Jin, Chuang Liu, Xinwei Wu, Zishan Guo, Linhao Yu, Ling Shi, Bojian Jiang, Deyi Xiong
分类: cs.AI, cs.CL
发布日期: 2024-12-23
备注: 158 pages, 18 figures
🔗 代码/项目: GITHUB
💡 一句话要点
大型语言模型安全:全面综述与风险缓解策略
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型安全 价值对齐 对抗攻击 AI治理 风险评估 伦理考量 可解释性
📋 核心要点
- 大型语言模型在快速发展的同时,也带来了价值对齐、对抗攻击、滥用和自主AI风险等安全挑战,需要全面评估和缓解。
- 本综述旨在通过整合技术解决方案、伦理考量和治理框架,为LLM安全提供一个多方面的综合方法。
- 该研究为学术界、工业界和政策制定者提供LLM安全挑战和机遇的见解,并促进AI技术在安全和有益方向上的发展。
📝 摘要(中文)
大型语言模型(LLM)的快速发展和部署在人工智能领域开辟了新纪元,其在自然语言理解和生成方面展现出前所未有的能力。然而,这些模型日益融入关键应用也引发了重大的安全问题,因此有必要对其潜在风险和相关缓解策略进行全面考察。本综述全面概述了当前LLM安全态势,涵盖四大类问题:价值对齐偏差、对抗攻击的鲁棒性、滥用以及自主AI风险。除了对这四个方面的缓解方法和评估资源进行全面回顾外,我们还探讨了与LLM安全相关的四个主题:LLM代理的安全影响、可解释性在增强LLM安全中的作用、一系列AI公司和机构为LLM安全提出的技术路线图,以及旨在保障LLM安全的AI治理,包括对国际合作、政策建议和未来监管方向的讨论。我们的研究结果强调,必须采取积极主动、多方面的LLM安全方法,强调技术解决方案、伦理考量和健全治理框架的整合。本综述旨在为学术研究人员、行业从业者和政策制定者提供基础资源,深入了解LLM安全集成到社会所面临的挑战和机遇。最终,它旨在为LLM的安全和有益发展做出贡献,与利用AI促进社会进步和福祉的总体目标保持一致。相关论文的精选列表已在https://github.com/tjunlp-lab/Awesome-LLM-Safety-Papers上公开。
🔬 方法详解
问题定义:大型语言模型(LLM)虽然在自然语言处理方面表现出色,但同时也面临着严重的安全问题。现有方法在价值对齐、对抗攻击防御、防止滥用以及应对自主AI风险等方面存在不足,无法有效保障LLM的安全性。这些问题可能导致模型产生有害内容、被恶意利用或产生不可控的行为。
核心思路:本综述的核心思路是对LLM安全问题进行全面梳理和分类,并对现有的缓解方法和评估资源进行系统性的总结和分析。通过识别不同类型的安全风险,并探讨相应的技术、伦理和治理策略,旨在为LLM的安全发展提供指导。这种方法强调了多学科交叉的重要性,需要技术专家、伦理学家和政策制定者共同努力。
技术框架:该综述的技术框架主要包括以下几个阶段:1) 定义LLM安全的关键领域,包括价值对齐、鲁棒性、滥用和自主AI风险;2) 收集和整理相关文献,包括研究论文、技术报告和政策文件;3) 对现有方法进行分类和评估,识别其优缺点;4) 探讨LLM代理的安全影响、可解释性的作用以及AI治理的策略;5) 总结研究结果,并提出未来研究方向和政策建议。
关键创新:本综述的关键创新在于其全面性和系统性。它不仅涵盖了LLM安全的主要技术挑战,还探讨了伦理和社会影响,并提出了相应的治理框架。与以往的研究相比,本综述更加注重多学科交叉,强调技术、伦理和政策的协同作用。此外,该综述还提供了一个公开的资源列表,方便研究人员查找相关文献。
关键设计:本综述的关键设计在于其分类框架和评估方法。它将LLM安全问题分为四个主要类别,并对每个类别下的现有方法进行了详细的评估。此外,该综述还探讨了LLM代理的安全影响、可解释性的作用以及AI治理的策略。这些设计使得本综述能够全面地覆盖LLM安全的关键问题,并为未来的研究提供指导。
🖼️ 关键图片

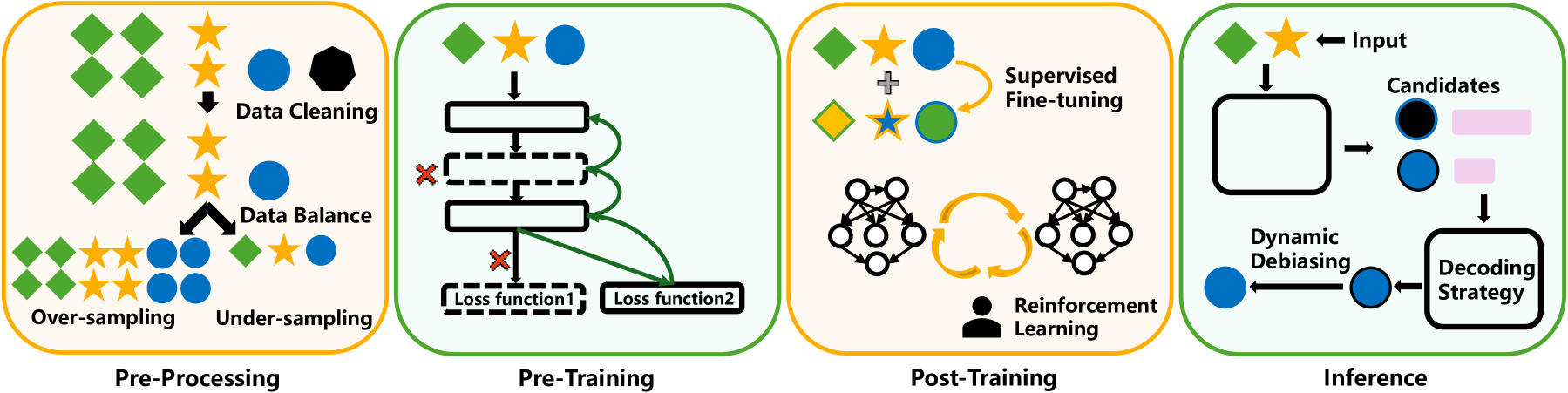
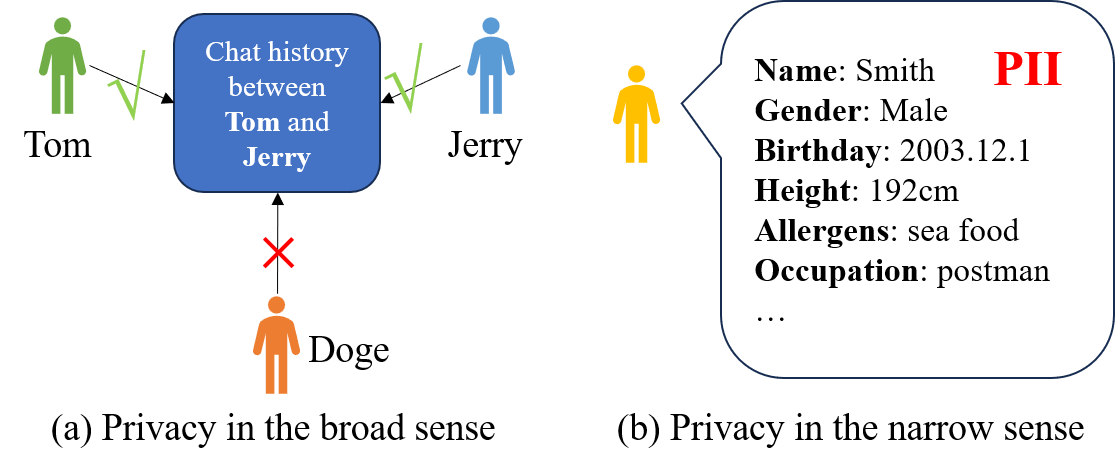
📊 实验亮点
该综述全面梳理了LLM安全领域的四大风险:价值对齐偏差、对抗攻击的鲁棒性、滥用和自主AI风险,并系统性地总结了现有缓解方法和评估资源。此外,探讨了LLM代理的安全影响、可解释性的作用以及AI治理策略,为LLM安全研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于多个领域,包括但不限于:AI安全评估、LLM风险管理、AI伦理规范制定、以及相关政策法规的制定。通过对LLM安全风险的全面理解和有效缓解,可以促进LLM在医疗、金融、教育等领域的安全应用,并降低潜在的社会风险。
📄 摘要(原文)
The rapid development and deployment of large language models (LLMs) have introduced a new frontier in artificial intelligence, marked by unprecedented capabilities in natural language understanding and generation. However, the increasing integration of these models into critical applications raises substantial safety concerns, necessitating a thorough examination of their potential risks and associated mitigation strategies. This survey provides a comprehensive overview of the current landscape of LLM safety, covering four major categories: value misalignment, robustness to adversarial attacks, misuse, and autonomous AI risks. In addition to the comprehensive review of the mitigation methodologies and evaluation resources on these four aspects, we further explore four topics related to LLM safety: the safety implications of LLM agents, the role of interpretability in enhancing LLM safety, the technology roadmaps proposed and abided by a list of AI companies and institutes for LLM safety, and AI governance aimed at LLM safety with discussions on international cooperation, policy proposals, and prospective regulatory directions. Our findings underscore the necessity for a proactive, multifaceted approach to LLM safety, emphasizing the integration of technical solutions, ethical considerations, and robust governance frameworks. This survey is intended to serve as a foundational resource for academy researchers, industry practitioners, and policymakers, offering insights into the challenges and opportunities associated with the safe integration of LLMs into society. Ultimately, it seeks to contribute to the safe and beneficial development of LLMs, aligning with the overarching goal of harnessing AI for societal advancement and well-being. A curated list of related papers has been publicly available at https://github.com/tjunlp-lab/Awesome-LLM-Safety-Papers.