D-Judge: How Far Are We? Assessing the Discrepancies Between AI-synthesized and Natural Images through Multimodal Guidance
作者: Renyang Liu, Ziyu Lyu, Wei Zhou, See-Kiong Ng
分类: cs.AI, cs.CV, cs.MM
发布日期: 2024-12-23 (更新: 2025-08-11)
备注: Accepted by ACM MM 2025
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
D-Judge:通过多模态指导评估AI合成图像与自然图像的差距
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI生成内容 图像质量评估 多模态学习 数据集构建 基准测试
📋 核心要点
- 现有AI生成图像与自然图像存在显著差异,缺乏系统性的量化评估方法。
- 构建大规模多模态数据集D-ANI,并提出AI-自然图像差异评估基准D-Judge。
- 通过五个维度评估AI生成图像,揭示其与自然图像的差距,强调人类判断的重要性。
📝 摘要(中文)
在快速发展的人工智能生成内容(AIGC)领域,一个核心挑战是如何区分AI合成图像和自然图像。尽管先进的生成模型在生成视觉上引人注目的图像方面表现出令人印象深刻的能力,但与自然图像相比,仍然存在显著差异。为了系统地研究和量化这些差异,我们构建了一个大规模多模态数据集D-ANI,包含5000张自然图像和超过44万张由九个代表性模型生成的AIGI样本,这些模型使用单模态和多模态提示,包括文本到图像(T2I)、图像到图像(I2I)和文本和图像到图像(TI2I)。然后,我们引入了一个AI-自然图像差异评估基准(D-Judge),以解决一个关键问题:AI生成的图像(AIGI)与真正逼真的图像有多大差距?我们的细粒度评估框架从五个维度评估D-ANI数据集:朴素视觉质量、语义对齐、审美吸引力、下游任务适用性和协调的人工验证。广泛的实验揭示了这些维度上的显著差异,突出了将定量指标与人类判断对齐以实现对AI生成图像质量的全面理解的重要性。
🔬 方法详解
问题定义:论文旨在解决如何系统性地评估AI合成图像与自然图像之间差异的问题。现有方法缺乏细粒度的评估框架,无法全面衡量AI生成图像的质量,尤其是在语义对齐、审美和下游任务适用性等方面。此外,现有评估方法往往忽视了人类主观判断的重要性。
核心思路:论文的核心思路是通过构建一个大规模多模态数据集D-ANI,并在此基础上建立一个综合性的评估基准D-Judge,从多个维度量化AI生成图像与自然图像的差异。该方法强调将定量指标与人类主观评价相结合,以更全面地理解AI生成图像的质量。
技术框架:D-Judge评估框架主要包含以下几个阶段:1) 构建大规模多模态数据集D-ANI,包含自然图像和由不同AI模型生成的图像;2) 定义五个评估维度:朴素视觉质量、语义对齐、审美吸引力、下游任务适用性和协调的人工验证;3) 针对每个维度设计相应的评估指标和实验;4) 分析实验结果,揭示AI生成图像与自然图像的差异,并探讨不同评估指标之间的关系。
关键创新:论文的关键创新在于:1) 构建了大规模多模态数据集D-ANI,为AI生成图像的评估提供了丰富的数据基础;2) 提出了D-Judge评估基准,从多个维度全面评估AI生成图像的质量;3) 强调了人类主观判断在AI生成图像评估中的重要性,并将人类评价纳入评估框架。
关键设计:D-ANI数据集包含5000张自然图像和超过44万张AI生成图像,这些图像由九个代表性模型生成,并使用单模态和多模态提示。评估维度包括:朴素视觉质量(使用FID、IS等指标)、语义对齐(评估生成图像与提示的匹配程度)、审美吸引力(使用NIMA等指标)、下游任务适用性(评估生成图像在图像分类、目标检测等任务上的性能)和协调的人工验证(通过人工标注评估图像的真实感和质量)。
🖼️ 关键图片
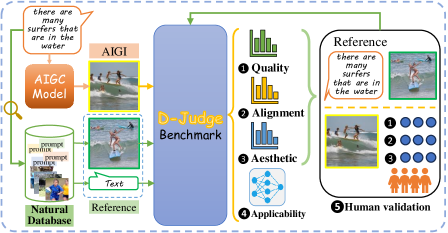

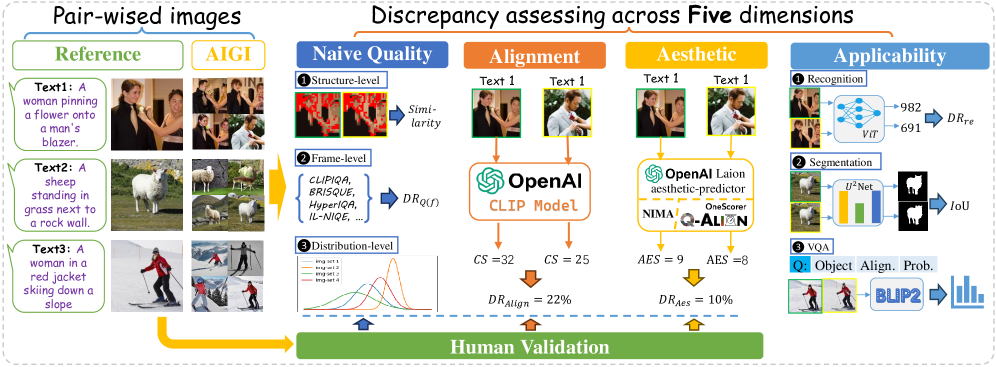
📊 实验亮点
实验结果表明,AI生成图像在朴素视觉质量上与自然图像的差距正在缩小,但在语义对齐、审美吸引力和下游任务适用性等方面仍存在显著差异。例如,在语义对齐方面,AI生成图像与提示的匹配程度仍有待提高。此外,实验还表明,将定量指标与人类主观评价相结合,可以更全面地评估AI生成图像的质量。
🎯 应用场景
该研究成果可应用于AIGC模型的改进和评估,帮助开发者更好地理解AI生成图像的优缺点,从而开发出更逼真、更符合人类审美的图像生成模型。此外,该研究还可以应用于图像取证领域,帮助鉴别AI合成图像,防止其被用于恶意目的。未来,该研究可以扩展到视频生成领域,评估AI生成视频的质量和真实性。
📄 摘要(原文)
In the rapidly evolving field of Artificial Intelligence Generated Content (AIGC), a central challenge is distinguishing AI-synthesized images from natural ones. Despite the impressive capabilities of advanced generative models in producing visually compelling images, significant discrepancies remain when compared to natural images. To systematically investigate and quantify these differences, we construct a large-scale multimodal dataset, D-ANI, comprising 5,000 natural images and over 440,000 AIGI samples generated by nine representative models using both unimodal and multimodal prompts, including Text-to-Image (T2I), Image-to-Image (I2I), and Text-and-Image-to-Image (TI2I). We then introduce an AI-Natural Image Discrepancy assessment benchmark (D-Judge) to address the critical question: how far are AI-generated images (AIGIs) from truly realistic images? Our fine-grained evaluation framework assesses the D-ANI dataset across five dimensions: naive visual quality, semantic alignment, aesthetic appeal, downstream task applicability, and coordinated human validation. Extensive experiments reveal substantial discrepancies across these dimensions, highlighting the importance of aligning quantitative metrics with human judgment to achieve a comprehensive understanding of AI-generated image quality. Code: https://github.com/ryliu68/DJudge ; Data: https://huggingface.co/datasets/Renyang/DANI.