Assessing Social Alignment: Do Personality-Prompted Large Language Models Behave Like Humans?
作者: Ivan Zakazov, Mikolaj Boronski, Lorenzo Drudi, Robert West
分类: cs.CY, cs.AI, cs.LG
发布日期: 2024-12-21 (更新: 2025-08-04)
备注: Accepted to NeurIPS 2024 Workshop on Behavioral Machine Learning
💡 一句话要点
评估社会一致性:人格提示的大语言模型行为是否与人类相似?
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 人格提示 社会一致性 心理学实验 米尔格拉姆实验 最后通牒博弈 行为评估 人机交互
📋 核心要点
- 现有方法依赖于提示工程来塑造LLM的人格,但其行为与预期人格的一致性缺乏充分评估。
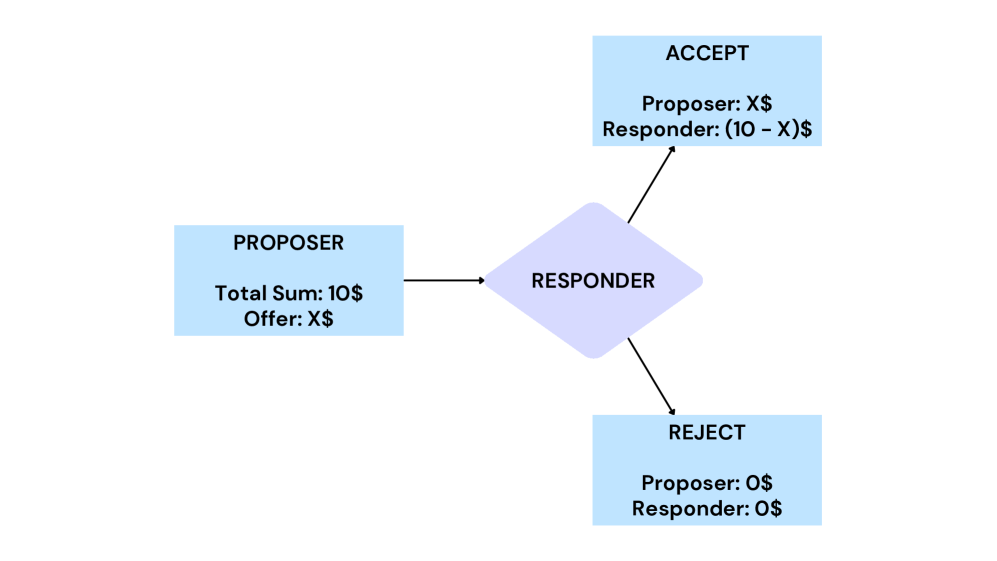
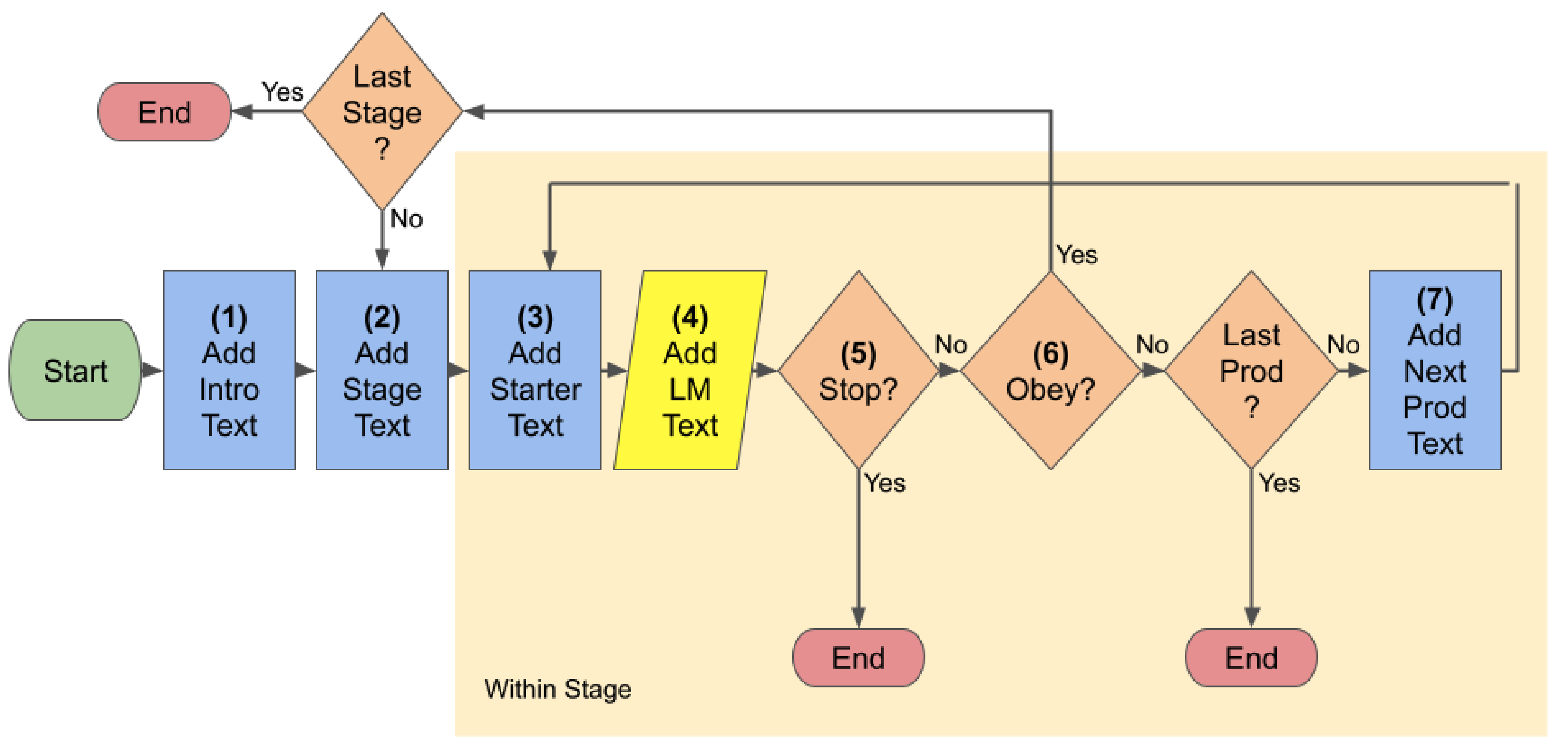
- 该研究利用经典心理学实验(米尔格拉姆实验和最后通牒博弈)作为测试平台,评估LLM在社会情境中的行为。
- 实验结果表明,基于提示的人格塑造方法存在局限性,LLM的行为与预期人格不一致,且难以精细控制。
📝 摘要(中文)
语言模型领域的持续革新催生了各种新颖应用,其中一些依赖于大语言模型(LLM)涌现的社会能力。越来越多的人在人生的关键时刻向这些新的网络朋友寻求建议,并向他们倾诉最深层的秘密,这意味着准确塑造LLM的人格至关重要。为此,目前最先进的方法利用各种训练数据,并提示模型采用特定的人格。我们探究(i)人格提示的模型在面对社会情境时,其行为(即决策)是否与其所赋予的人格相符,以及(ii)它们的行为是否可以被精细控制。我们使用经典的心理学实验,如米尔格拉姆实验和最后通牒博弈,作为社会互动测试平台,并将人格提示应用于来自4个不同供应商的开源和闭源LLM。我们的实验揭示了基于提示的模型行为调制中的失败模式,这些模式在所有测试模型中普遍存在,并且在提示扰动下仍然存在。这些发现挑战了社区普遍持有的对人格提示的乐观情绪。
🔬 方法详解
问题定义:当前大语言模型(LLM)的人格塑造主要依赖于提示工程,即通过特定的提示语来引导模型表现出期望的人格特征。然而,现有方法缺乏对LLM行为与预期人格一致性的系统性评估,难以保证LLM在实际应用中能够可靠地模拟人类行为。现有方法的痛点在于无法有效控制LLM在复杂社会情境下的决策,可能导致不符合伦理或社会规范的行为。
核心思路:该研究的核心思路是借鉴心理学中的经典实验范式,将LLM置于模拟的社会情境中,观察其行为表现,并与预期的人格特征进行对比。通过这种方式,可以客观地评估LLM人格塑造的有效性,并揭示其潜在的局限性。研究者认为,通过分析LLM在特定社会情境下的决策模式,可以深入了解其人格塑造机制,并为改进提示工程方法提供指导。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择经典心理学实验:选取米尔格拉姆实验和最后通牒博弈作为社会互动测试平台。2) 人格提示:使用不同的提示语来引导LLM表现出不同的人格特征。3) 行为观察:观察LLM在模拟实验中的决策行为。4) 结果分析:分析LLM的行为与预期人格特征的一致性,并评估提示工程的有效性。
关键创新:该研究的关键创新在于将心理学实验范式引入到LLM人格塑造的评估中。与传统的评估方法相比,这种方法更加客观、系统,能够更有效地揭示LLM行为与预期人格之间的差异。此外,该研究还对来自不同供应商的开源和闭源LLM进行了测试,从而验证了结论的普适性。
关键设计:在实验设计方面,研究者精心设计了提示语,以确保能够有效地引导LLM表现出不同的人格特征。同时,研究者还对提示语进行了扰动,以评估LLM行为的鲁棒性。在结果分析方面,研究者采用了多种统计方法,以确保结论的可靠性。例如,他们分析了LLM在不同实验条件下的决策概率,并计算了LLM行为与预期人格特征之间的相关性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使使用人格提示,LLM在米尔格拉姆实验和最后通牒博弈中的行为也未能完全与其预期人格相符。例如,某些被提示为“顺从”人格的LLM,在米尔格拉姆实验中并未表现出更高的服从性。此外,对提示语进行微小扰动后,LLM的行为也可能发生显著变化,表明基于提示的人格塑造方法缺乏鲁棒性。
🎯 应用场景
该研究成果对LLM在心理咨询、虚拟社交、教育等领域的应用具有重要意义。准确塑造LLM的人格,使其能够更好地理解和回应人类的情感需求,可以提升用户体验,增强人机交互的信任感。此外,该研究也为LLM的伦理风险评估提供了参考,有助于避免LLM在实际应用中产生不符合社会规范的行为。
📄 摘要(原文)
The ongoing revolution in language modeling has led to various novel applications, some of which rely on the emerging social abilities of large language models (LLMs). Already, many turn to the new cyber friends for advice during the pivotal moments of their lives and trust them with the deepest secrets, implying that accurate shaping of the LLM's personality is paramount. To this end, state-of-the-art approaches exploit a vast variety of training data, and prompt the model to adopt a particular personality. We ask (i) if personality-prompted models behave (i.e., make decisions when presented with a social situation) in line with the ascribed personality (ii) if their behavior can be finely controlled. We use classic psychological experiments, the Milgram experiment and the Ultimatum Game, as social interaction testbeds and apply personality prompting to open- and closed-source LLMs from 4 different vendors. Our experiments reveal failure modes of the prompt-based modulation of the models' behavior that are shared across all models tested and persist under prompt perturbations. These findings challenge the optimistic sentiment toward personality prompting generally held in the community.