Can LLMs Obfuscate Code? A Systematic Analysis of Large Language Models into Assembly Code Obfuscation
作者: Seyedreza Mohseni, Seyedali Mohammadi, Deepa Tilwani, Yash Saxena, Gerald Ketu Ndawula, Sriram Vema, Edward Raff, Manas Gaur
分类: cs.CR, cs.AI, cs.CL
发布日期: 2024-12-20 (更新: 2025-01-29)
备注: To appear in AAAI 2025, Main Track
💡 一句话要点
利用LLM生成混淆汇编代码:MetamorphASM基准测试与系统分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码混淆 大型语言模型 汇编代码 恶意软件 安全分析
📋 核心要点
- 现有代码混淆工具依赖源码,且新增混淆方式成本高,限制了恶意代码的变异能力。
- 利用LLM直接生成混淆汇编代码,无需源码,降低了恶意代码变异的门槛,增加了攻击的灵活性。
- 构建了包含328,200个混淆汇编样本的MetamorphASM数据集,并评估了多种LLM在代码混淆生成上的性能。
📝 摘要(中文)
恶意软件作者经常使用代码混淆来增加恶意软件的检测难度。现有的代码混淆工具通常需要访问原始源代码(例如C++或Java),并且添加新的混淆技术是一个复杂且耗费人力的过程。本研究探讨了大型语言模型(LLM)是否能够生成新的混淆汇编代码。如果答案是肯定的,这将对反病毒引擎构成威胁,并可能增加攻击者创建新混淆模式的灵活性。通过开发MetamorphASM基准测试,包括MetamorphASM数据集(MAD)以及死代码、寄存器替换和控制流更改三种代码混淆技术,我们肯定了这一可能性。MetamorphASM系统地评估了LLM使用MAD生成和分析混淆代码的能力,MAD包含328,200个混淆汇编代码样本。我们发布了该数据集,并分析了各种LLM(例如GPT-3.5/4、GPT-4o-mini、Starcoder、CodeGemma、CodeLlama、CodeT5和LLaMA 3.1)在生成混淆汇编代码方面的成功率。评估使用了既定的信息论指标和人工审查,以确保正确性,并为研究人员研究和开发针对此风险的补救措施奠定基础。
🔬 方法详解
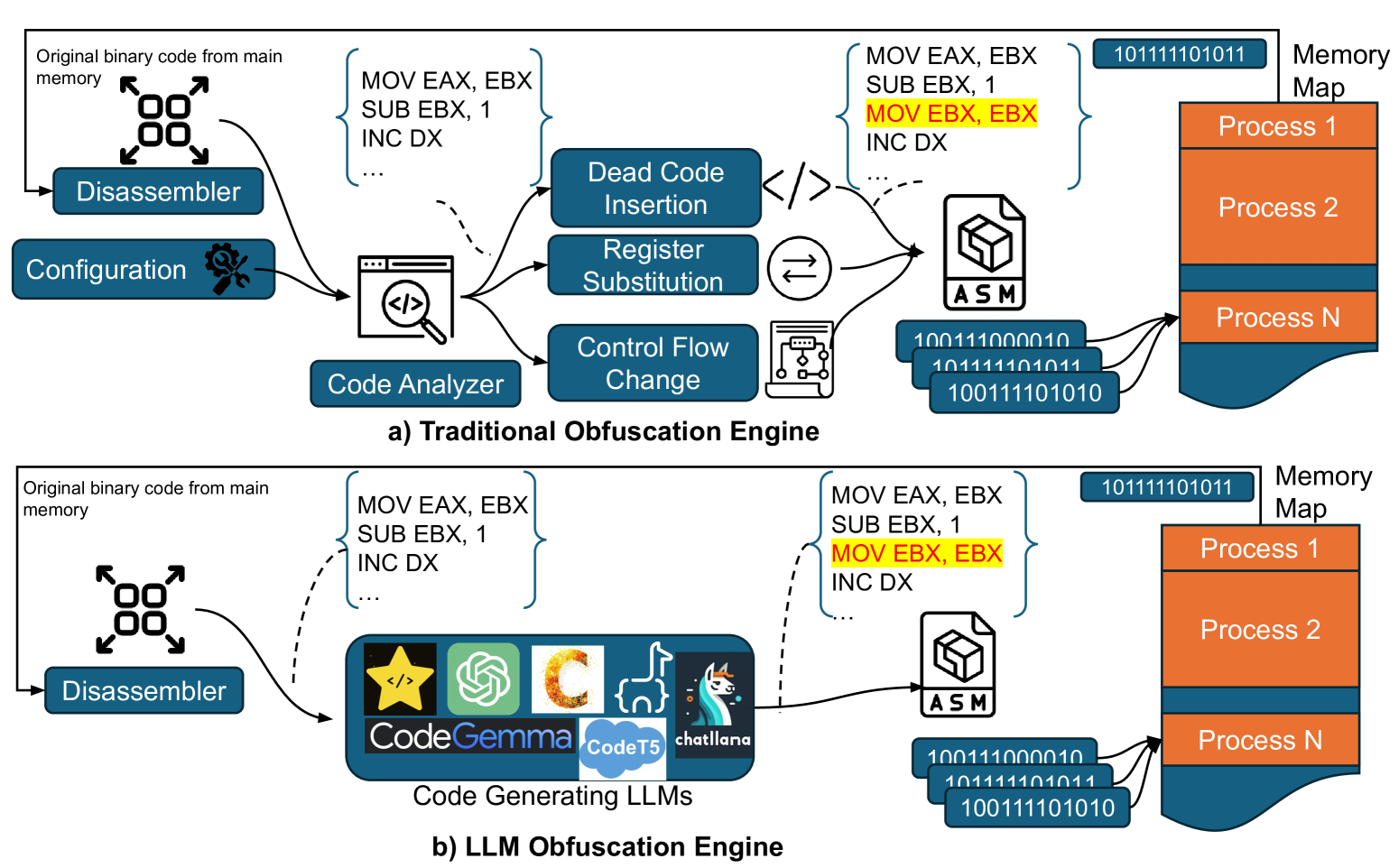
问题定义:论文旨在研究LLM是否能够生成有效的混淆汇编代码,从而绕过反病毒引擎的检测。现有代码混淆工具的痛点在于需要访问源代码,并且添加新的混淆技术需要大量的人工工作,这限制了恶意软件作者快速生成和部署新型恶意软件的能力。
核心思路:论文的核心思路是利用LLM强大的代码生成能力,直接生成混淆后的汇编代码,而无需依赖原始的源代码。这种方法可以极大地简化代码混淆的过程,并允许恶意软件作者快速尝试各种不同的混淆策略。这样设计的目的是为了评估LLM在恶意代码生成方面的潜在风险,并为未来的安全研究提供参考。
技术框架:论文构建了MetamorphASM基准测试,包含以下几个主要组成部分:1) MetamorphASM数据集(MAD):包含328,200个混淆汇编代码样本,涵盖多种混淆技术。2) 三种代码混淆技术:死代码插入、寄存器替换和控制流更改。3) 评估指标:使用信息论指标和人工审查来评估LLM生成的混淆代码的质量和正确性。4) LLM评估:对多种LLM(例如GPT-3.5/4、GPT-4o-mini、Starcoder、CodeGemma、CodeLlama、CodeT5和LLaMA 3.1)进行评估,分析它们在生成混淆汇编代码方面的性能。
关键创新:论文最重要的技术创新点在于探索了利用LLM直接生成混淆汇编代码的可能性。与现有方法相比,该方法无需访问源代码,并且可以快速生成各种不同的混淆模式。这为恶意软件作者提供了一种新的、更灵活的混淆手段,同时也对反病毒引擎提出了新的挑战。
关键设计:论文的关键设计包括:1) MAD数据集的构建,确保数据集的多样性和代表性。2) 三种混淆技术的选择,涵盖了常见的汇编代码混淆手段。3) 评估指标的选择,既包括自动化的信息论指标,也包括人工审查,以确保评估的全面性和准确性。论文未提供关于LLM训练或微调的特定参数设置,而是侧重于评估现有LLM在零样本或少样本情况下的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,某些LLM(如GPT-4)在生成混淆汇编代码方面表现出一定的能力,能够成功生成包含死代码、寄存器替换和控制流更改的混淆代码。然而,不同LLM的性能差异显著,且生成的代码质量参差不齐。人工审查发现,部分LLM生成的代码存在逻辑错误或无法执行的问题。MetamorphASM数据集的发布为后续研究提供了宝贵的资源。
🎯 应用场景
该研究成果可应用于恶意软件分析与检测、安全漏洞挖掘、反病毒引擎开发等领域。通过了解LLM生成混淆代码的能力,安全研究人员可以更好地应对新型恶意软件的威胁,并开发更有效的检测和防御机制。此外,该研究还可以促进对LLM安全性的更深入理解,并为开发更安全的LLM应用提供指导。
📄 摘要(原文)
Malware authors often employ code obfuscations to make their malware harder to detect. Existing tools for generating obfuscated code often require access to the original source code (e.g., C++ or Java), and adding new obfuscations is a non-trivial, labor-intensive process. In this study, we ask the following question: Can Large Language Models (LLMs) potentially generate a new obfuscated assembly code? If so, this poses a risk to anti-virus engines and potentially increases the flexibility of attackers to create new obfuscation patterns. We answer this in the affirmative by developing the MetamorphASM benchmark comprising MetamorphASM Dataset (MAD) along with three code obfuscation techniques: dead code, register substitution, and control flow change. The MetamorphASM systematically evaluates the ability of LLMs to generate and analyze obfuscated code using MAD, which contains 328,200 obfuscated assembly code samples. We release this dataset and analyze the success rate of various LLMs (e.g., GPT-3.5/4, GPT-4o-mini, Starcoder, CodeGemma, CodeLlama, CodeT5, and LLaMA 3.1) in generating obfuscated assembly code. The evaluation was performed using established information-theoretic metrics and manual human review to ensure correctness and provide the foundation for researchers to study and develop remediations to this risk.