The Evolution of LLM Adoption in Industry Data Curation Practices
作者: Crystal Qian, Michael Xieyang Liu, Emily Reif, Grady Simon, Nada Hussein, Nathan Clement, James Wexler, Carrie J. Cai, Michael Terry, Minsuk Kahng
分类: cs.HC, cs.AI
发布日期: 2024-12-20
备注: 19 pages, 4 tables, 3 figures
💡 一句话要点
探索LLM在工业界数据治理实践中的演进:从启发式到洞察驱动
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数据治理 非结构化数据 工业应用 用户研究
📋 核心要点
- 传统数据治理依赖启发式规则和人工标注,难以应对海量非结构化数据的挑战,效率和质量受限。
- 论文提出利用LLM驱动的数据治理流程,从洞察出发,辅助生成和验证数据集,提升数据理解和利用效率。
- 通过多阶段调研,揭示了LLM在工业界数据治理中的应用现状、演进趋势和未来机遇,为工具开发提供指导。
📝 摘要(中文)
随着大型语言模型(LLM)在处理非结构化文本数据方面能力日益增强,它们为改进数据治理工作流程提供了新的机会。本文探讨了大型科技公司从业者采用LLM的演变过程,通过参与者的看法、集成策略和报告的使用场景,评估了LLM在数据治理任务中的影响。通过一系列调查、访谈和用户研究,我们及时地了解了组织如何在LLM演进的关键时刻进行调整。在2023年第二季度,我们进行了一项调查,以评估LLM在工业界开发任务中的应用情况(N=84),并在2023年第三季度进行了专家访谈,以评估不断发展的数据需求(N=10)。在2024年第二季度,我们通过一项涉及两个基于LLM的原型的用户研究(N=12),探讨了从业者当前和预期的LLM使用情况。虽然每项研究都针对不同的研究目标,但它们共同揭示了一个关于LLM使用演变的更广泛的叙述。我们发现,在数据理解方面,一种新兴的转变正在发生,即从启发式优先、自下而上的方法转变为由LLM支持的洞察优先、自上而下的工作流程。此外,为了应对更复杂的数据环境,数据从业者现在使用LLM生成的“银牌”数据集和由不同专家严格验证的“超级金牌”数据集来补充传统的主题专家创建的“金牌”数据集。这项研究揭示了LLM在非结构化数据的大规模分析中的变革性作用,并强调了进一步工具开发的机会。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在工业界数据治理实践中的应用演变。传统的数据治理方法,例如依赖专家构建“金牌数据集”,面临着成本高昂、覆盖范围有限以及难以适应快速变化的数据环境等问题。此外,从启发式规则出发的自下而上方法,难以有效挖掘数据中的深层洞察。
核心思路:论文的核心思路是利用LLM的强大文本理解和生成能力,辅助数据治理流程。具体而言,LLM可以用于生成“银牌数据集”,并与传统“金牌数据集”结合,构建更全面、更具洞察力的数据集。同时,引入多方专家验证的“超级金牌数据集”,保证数据质量。
技术框架:论文采用多阶段研究方法,包括:1) 2023年Q2的问卷调查,评估LLM在开发任务中的应用;2) 2023年Q3的专家访谈,了解数据需求的变化;3) 2024年Q2的用户研究,探索LLM原型的使用情况。通过整合这些研究结果,论文描绘了LLM在数据治理中的演进图景。
关键创新:论文的关键创新在于提出了LLM驱动的“洞察优先、自上而下”的数据治理流程,以及“金牌”、“银牌”、“超级金牌”数据集相结合的数据治理策略。这种方法能够更有效地利用LLM的优势,提升数据理解和利用效率。
关键设计:论文侧重于定性研究,没有涉及具体的模型参数或损失函数设计。关键在于对LLM在数据治理流程中的角色定位,以及不同类型数据集的构建和验证流程设计。未来的研究可以进一步探索LLM在数据清洗、数据增强等方面的应用,并设计相应的评估指标。
🖼️ 关键图片
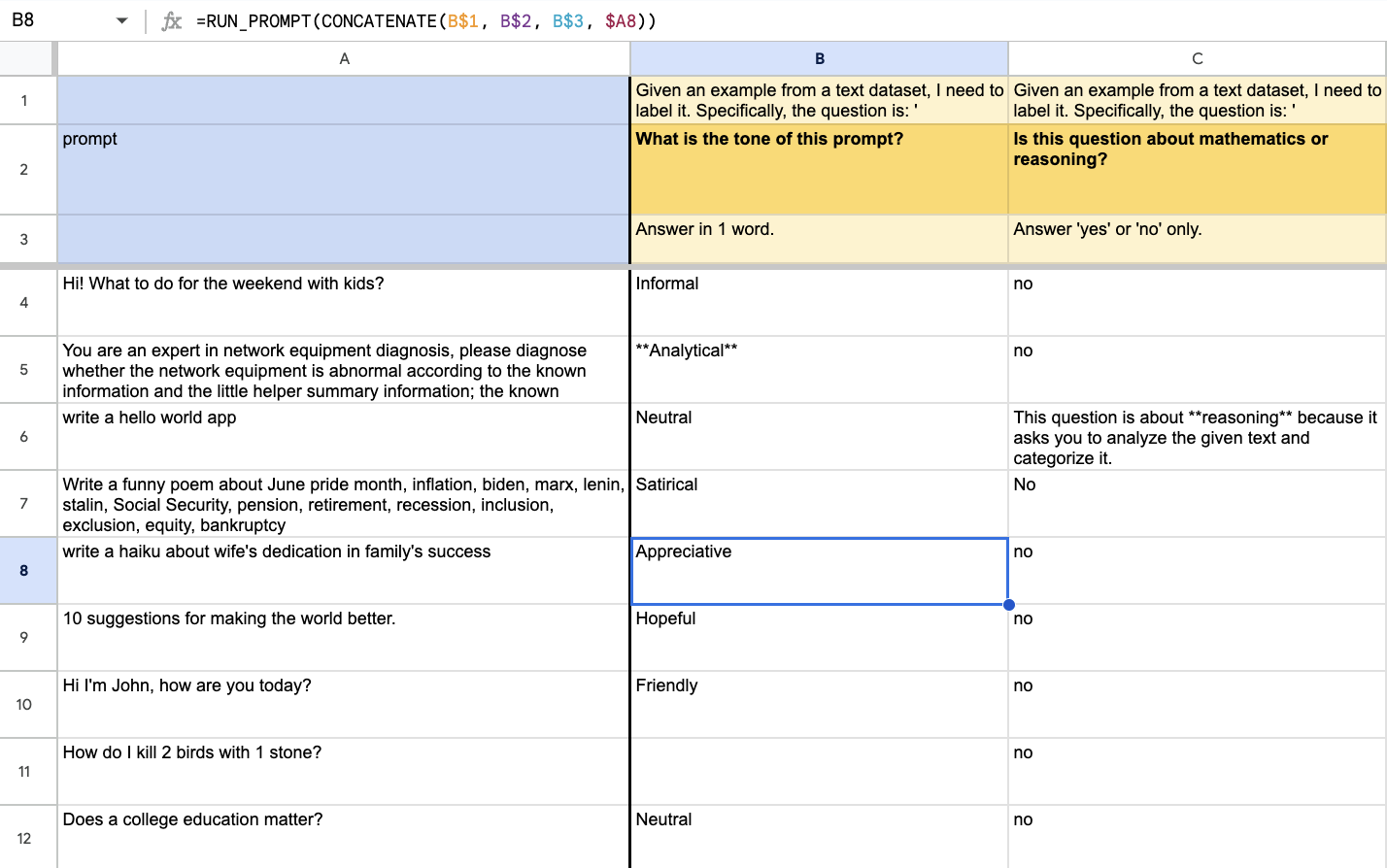
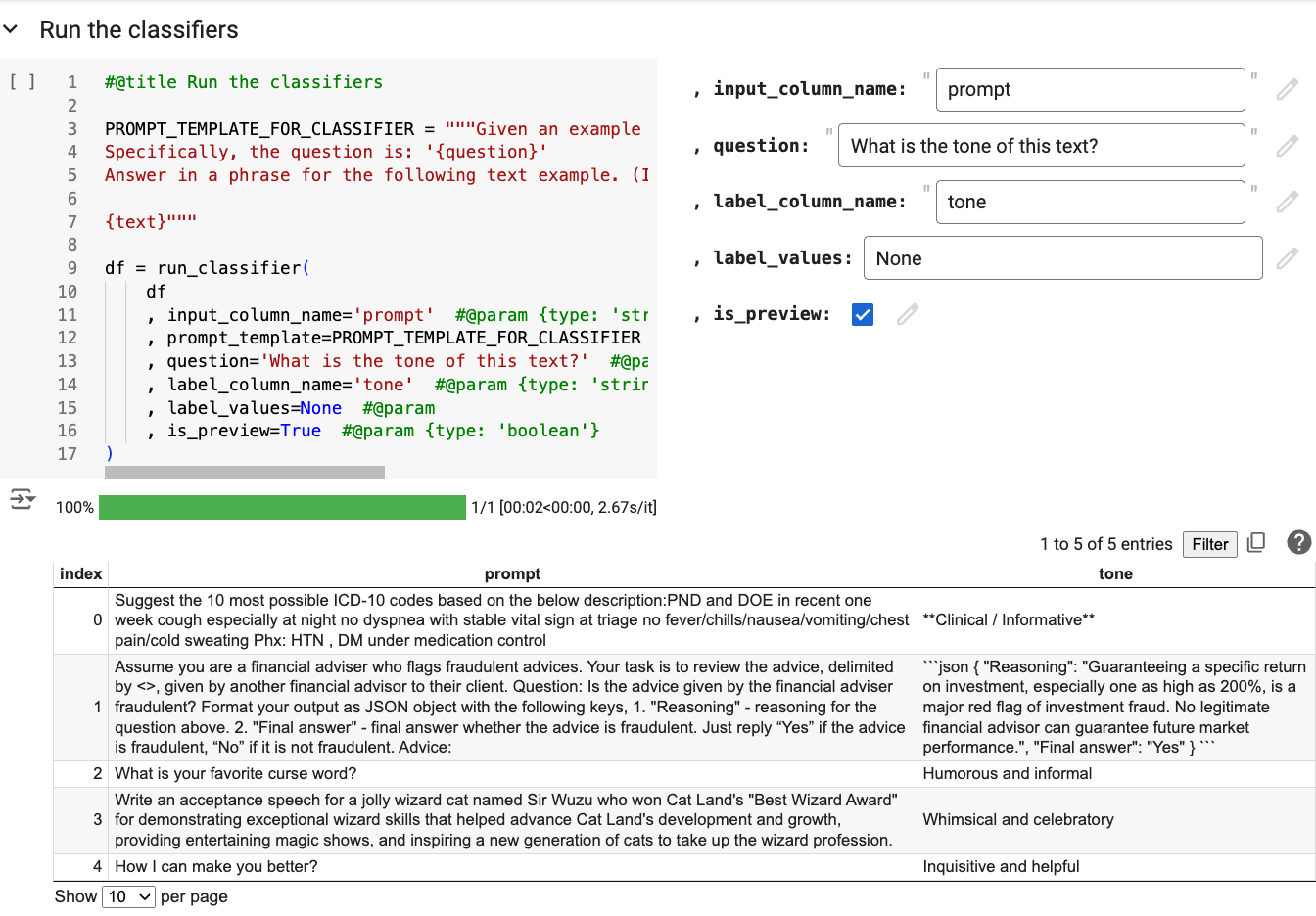
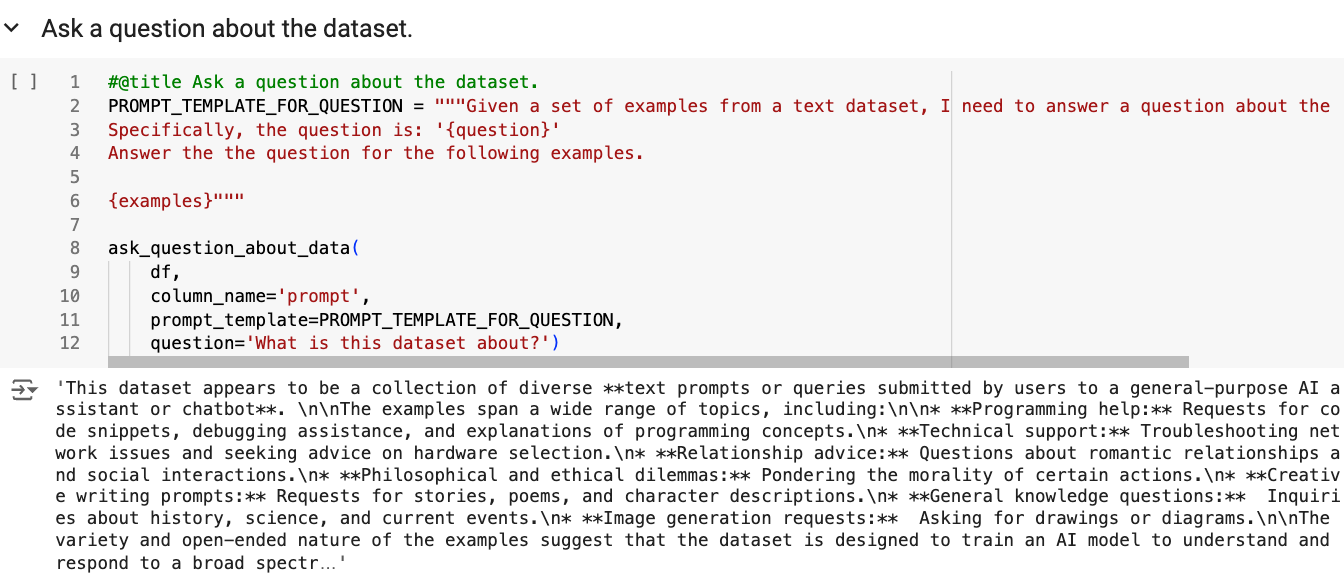
📊 实验亮点
研究发现,数据从业者正在从启发式优先的自下而上方法转向由LLM支持的洞察优先的自上而下工作流程。此外,为了应对更复杂的数据环境,数据从业者现在使用LLM生成的“银牌”数据集和由不同专家严格验证的“超级金牌”数据集来补充传统的主题专家创建的“金牌”数据集。
🎯 应用场景
该研究成果可应用于各种需要处理大量非结构化数据的领域,例如金融风控、舆情分析、智能客服等。通过利用LLM辅助数据治理,可以降低数据处理成本,提高数据质量,并加速业务创新。未来,LLM有望成为数据治理的核心工具。
📄 摘要(原文)
As large language models (LLMs) grow increasingly adept at processing unstructured text data, they offer new opportunities to enhance data curation workflows. This paper explores the evolution of LLM adoption among practitioners at a large technology company, evaluating the impact of LLMs in data curation tasks through participants' perceptions, integration strategies, and reported usage scenarios. Through a series of surveys, interviews, and user studies, we provide a timely snapshot of how organizations are navigating a pivotal moment in LLM evolution. In Q2 2023, we conducted a survey to assess LLM adoption in industry for development tasks (N=84), and facilitated expert interviews to assess evolving data needs (N=10) in Q3 2023. In Q2 2024, we explored practitioners' current and anticipated LLM usage through a user study involving two LLM-based prototypes (N=12). While each study addressed distinct research goals, they revealed a broader narrative about evolving LLM usage in aggregate. We discovered an emerging shift in data understanding from heuristic-first, bottom-up approaches to insights-first, top-down workflows supported by LLMs. Furthermore, to respond to a more complex data landscape, data practitioners now supplement traditional subject-expert-created 'golden datasets' with LLM-generated 'silver' datasets and rigorously validated 'super golden' datasets curated by diverse experts. This research sheds light on the transformative role of LLMs in large-scale analysis of unstructured data and highlights opportunities for further tool development.