Tree-of-Code: A Tree-Structured Exploring Framework for End-to-End Code Generation and Execution in Complex Task Handling
作者: Ziyi Ni, Yifan Li, Ning Yang, Dou Shen, Pin Lv, Daxiang Dong
分类: cs.SE, cs.AI
发布日期: 2024-12-19 (更新: 2025-08-04)
备注: This idea was first submitted to the NeuralPS Workshop "System 2 Reasoning At Scale" in September 2024. Its OpenReview: https://openreview.net/forum?id=8NKAL8Ngxk¬eId=8NKAL8Ngxk. It was then submitted to the NAACL 2025 in October 2024, which is recorded in: https://openreview.net/forum?id=S0ZUWD3Vy5¬eId=S0ZUWD3Vy5. Now this paper has been accepted for publication in ACL 2025 Findings
💡 一句话要点
提出Tree-of-Code框架,用于复杂任务中端到端代码生成与执行,提升LLM推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 复杂推理 自我监督学习 树搜索算法
📋 核心要点
- 现有CodeAct方法在复杂推理任务中,依赖片段化思维生成代码,导致不一致和缺乏有效监督。
- 提出Tree-of-Code框架,通过CodeProgram范式利用代码逻辑对齐全局推理,实现端到端代码生成与自我监督。
- 实验表明,Tree-of-Code在准确率上显著优于CodeAct,且交互轮次更少,验证了其有效性。
📝 摘要(中文)
解决复杂推理任务是智能体在现实世界中的关键应用。受益于大型语言模型(LLM)在代码数据上的预训练,诸如CodeAct等方法成功地使用代码作为LLM智能体的动作,取得了良好的效果。然而,CodeAct依赖于片段化的思维贪婪地生成下一个动作的代码块,导致不一致性和不稳定性。此外,CodeAct缺乏与动作相关的真值(GT),使得其在多轮交互中的监督信号和终止条件存在疑问。为了解决这些问题,我们首先引入了一种简单而有效的端到端代码生成范式CodeProgram,它利用代码的系统逻辑来与全局推理对齐,并实现有凝聚力的问题解决。然后,我们提出了Tree-of-Code(ToC),它基于代码的可执行性来自我增长CodeProgram节点,并在无GT场景中实现自我监督。在两个数据集上使用十个流行的零样本LLM进行的实验结果表明,ToC显著提高了近20%的准确率,且交互轮次减少到CodeAct的1/4以下。一些LLM甚至在单轮CodeProgram上的表现优于多轮CodeAct。为了进一步研究功效和效率之间的权衡,我们测试了不同的ToC树大小和探索机制。我们还强调了ToC的端到端数据生成在监督和强化微调方面的潜力。
🔬 方法详解
问题定义:现有基于代码的LLM智能体,如CodeAct,在解决复杂推理任务时,采用贪婪的方式生成代码片段,缺乏全局一致性,且依赖片段化思维。此外,由于缺乏动作相关的真值(GT),多轮交互过程中的监督信号和终止条件难以确定。
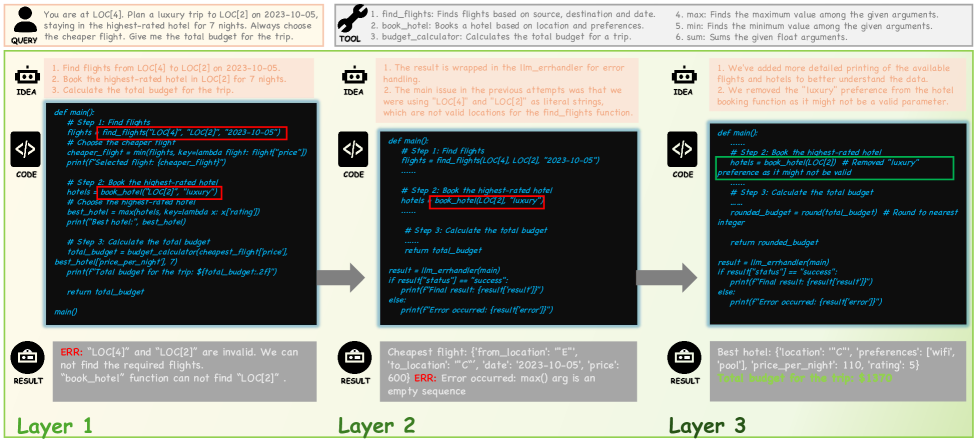
核心思路:论文的核心思路是利用代码的系统逻辑来对齐全局推理,从而实现更连贯的问题解决。通过构建一个树状结构(Tree-of-Code),智能体可以探索不同的代码路径,并基于代码的可执行性进行自我评估和监督,无需依赖人工标注的真值。
技术框架:Tree-of-Code框架包含以下主要步骤:1) CodeProgram生成:LLM生成一个完整的、可执行的代码程序,而不是片段化的代码块。2) 树结构探索:基于CodeProgram,框架通过不同的探索策略(例如,广度优先搜索、深度优先搜索)生成树状结构,每个节点代表一个不同的CodeProgram变体。3) 自我评估与监督:利用代码的可执行性,框架可以自动评估每个CodeProgram的性能,并使用这些评估结果作为监督信号来指导LLM的学习。4) 结果选择:最终,框架选择在树结构中表现最佳的CodeProgram作为最终答案。
关键创新:该论文的关键创新在于提出了Tree-of-Code框架,它将代码生成过程组织成一个树状结构,并利用代码的可执行性进行自我监督。这与传统的贪婪式代码生成方法不同,后者依赖于片段化的思维和人工标注的真值。Tree-of-Code框架能够更好地探索代码空间,并生成更一致、更可靠的代码程序。
关键设计:Tree-of-Code框架的关键设计包括:1) CodeProgram的生成方式:如何引导LLM生成完整的、可执行的代码程序。2) 树结构的探索策略:如何有效地探索代码空间,例如,使用广度优先搜索或深度优先搜索。3) 自我评估指标:如何利用代码的可执行性来评估每个CodeProgram的性能,例如,使用单元测试或集成测试。4) 监督信号的生成方式:如何使用自我评估结果来生成监督信号,例如,使用强化学习或模仿学习。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Tree-of-Code框架在两个数据集上使用十个流行的零样本LLM时,准确率比CodeAct提高了近20%,且交互轮次减少到CodeAct的1/4以下。一些LLM甚至在单轮CodeProgram上的表现优于多轮CodeAct,验证了该框架的有效性和效率。
🎯 应用场景
Tree-of-Code框架可应用于各种需要复杂推理和代码生成的场景,例如自动化程序修复、软件漏洞挖掘、智能编程助手和机器人控制等。该框架通过提高代码生成的一致性和可靠性,能够提升这些应用领域的性能和效率,并降低对人工干预的依赖。
📄 摘要(原文)
Solving complex reasoning tasks is a key real-world application of agents. Thanks to the pretraining of Large Language Models (LLMs) on code data, recent approaches like CodeAct successfully use code as LLM agents' action, achieving good results. However, CodeAct greedily generates the next action's code block by relying on fragmented thoughts, resulting in inconsistency and instability. Moreover, CodeAct lacks action-related ground-truth (GT), making its supervision signals and termination conditions questionable in multi-turn interactions. To address these issues, we first introduce a simple yet effective end-to-end code generation paradigm, CodeProgram, which leverages code's systematic logic to align with global reasoning and enable cohesive problem-solving. Then, we propose Tree-of-Code (ToC), which self-grows CodeProgram nodes based on the executable nature of the code and enables self-supervision in a GT-free scenario. Experimental results on two datasets using ten popular zero-shot LLMs show ToC remarkably boosts accuracy by nearly 20% over CodeAct with less than 1/4 turns. Several LLMs even perform better on one-turn CodeProgram than on multi-turn CodeAct. To further investigate the trade-off between efficacy and efficiency, we test different ToC tree sizes and exploration mechanisms. We also highlight the potential of ToC's end-to-end data generation for supervised and reinforced fine-tuning.