Deep reinforcement learning with time-scale invariant memory
作者: Md Rysul Kabir, James Mochizuki-Freeman, Zoran Tiganj
分类: cs.AI, cs.LG
发布日期: 2024-12-19
💡 一句话要点
提出基于时间尺度不变记忆的深度强化学习,提升Agent在不同时间尺度下的鲁棒性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 时间尺度不变性 循环神经网络 记忆模型 认知科学
📋 核心要点
- 现有深度强化学习Agent在处理不同时间尺度任务时存在鲁棒性问题,尤其是在长时依赖关系的学习上。
- 论文核心思想是将认知科学中的时间尺度不变记忆模型融入深度强化学习,使Agent能够更好地处理不同时间尺度的时间关系。
- 实验结果表明,与LSTM等传统循环神经网络相比,该方法显著提升了Agent在不同时间尺度下的学习能力和泛化能力。
📝 摘要(中文)
本文将计算神经科学中时间尺度不变记忆模型整合到深度强化学习(RL)Agent中。认知科学和神经科学为时间信用分配的行为和神经方面提供了卓越的见解。特别地,在行为中观察到并在神经数据中得到支持的学习动态的尺度不变性,是控制动物感知的主要原则之一:时间关系的比例重缩放不会改变整体学习效率。首先,论文提供了理论分析,然后通过实验证明,与使用常用循环记忆架构(如LSTM)构建的Agent不同,这种Agent可以在各种时间尺度上稳健地学习。该结果表明,将神经科学和认知科学的计算原理融入深度神经网络可以增强对复杂时间动态的适应性,从而反映人类学习的一些核心特性。
🔬 方法详解
问题定义:现有的深度强化学习方法,特别是基于循环神经网络(如LSTM)的方法,在处理具有不同时间尺度的任务时表现不佳。这些方法难以捕捉长时依赖关系,并且对时间尺度的变化敏感,导致学习效率低下和泛化能力差。因此,需要一种能够有效处理不同时间尺度时间关系的深度强化学习方法。
核心思路:论文的核心思路是将认知科学和神经科学中关于时间感知和记忆的原理融入到深度强化学习Agent中。具体来说,论文采用了一种时间尺度不变的记忆模型,该模型能够以一种与时间尺度无关的方式存储和检索信息,从而使Agent能够更好地处理不同时间尺度的时间关系。这种设计借鉴了动物在感知和学习过程中表现出的尺度不变性。
技术框架:该方法将时间尺度不变记忆模型集成到深度强化学习Agent的循环神经网络结构中。Agent通过与环境交互,收集经验数据,并使用强化学习算法(如Q-learning或策略梯度)来更新其策略。时间尺度不变记忆模型负责存储和检索与时间相关的状态信息,并将其提供给Agent的决策模块。整体流程与标准的深度强化学习流程相似,但关键在于循环记忆模块的替换。
关键创新:该论文的关键创新在于将计算神经科学中时间尺度不变记忆模型引入到深度强化学习中。与传统的循环神经网络(如LSTM)相比,该模型能够更好地处理不同时间尺度的时间关系,并且具有更强的鲁棒性和泛化能力。这种方法为解决深度强化学习中长期依赖问题提供了一种新的思路。
关键设计:论文中时间尺度不变记忆模型的具体实现细节未知,摘要中没有详细说明。但是,可以推测其设计可能包含以下关键要素:1) 一种能够以尺度不变的方式编码时间信息的机制;2) 一种能够根据当前时间尺度自适应地检索相关记忆的机制;3) 一种能够将检索到的记忆与当前状态信息融合的机制。损失函数和网络结构的选择可能取决于具体的强化学习算法和任务。
🖼️ 关键图片
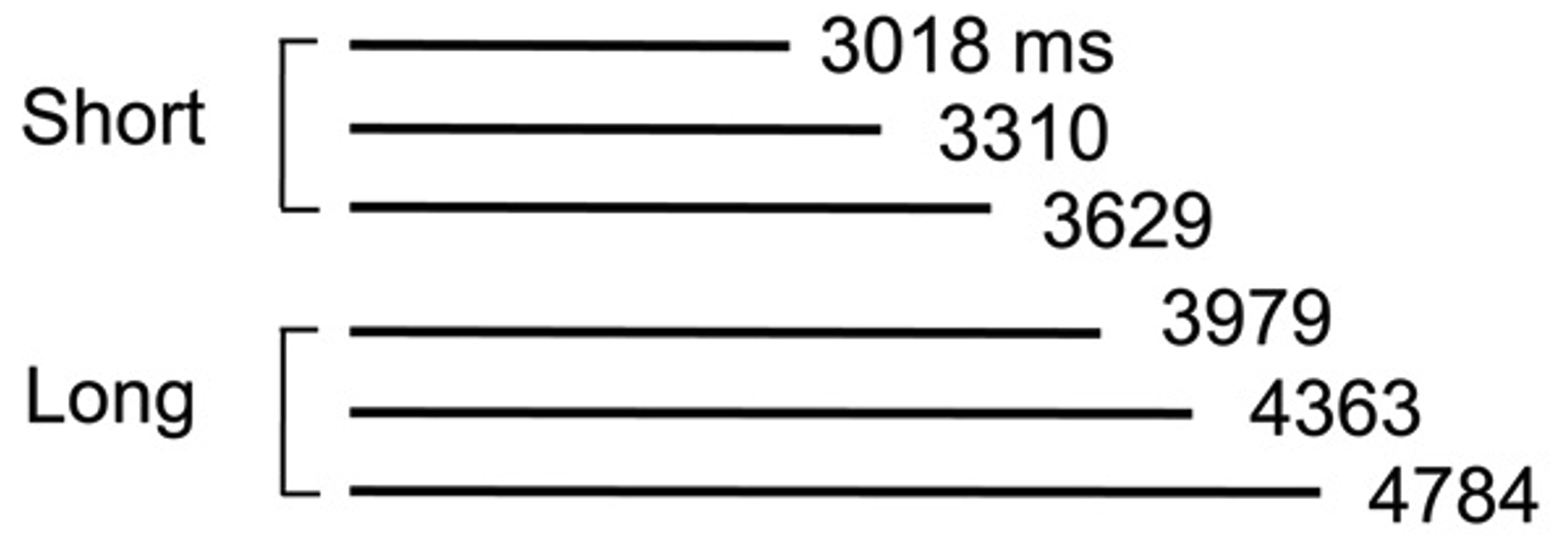
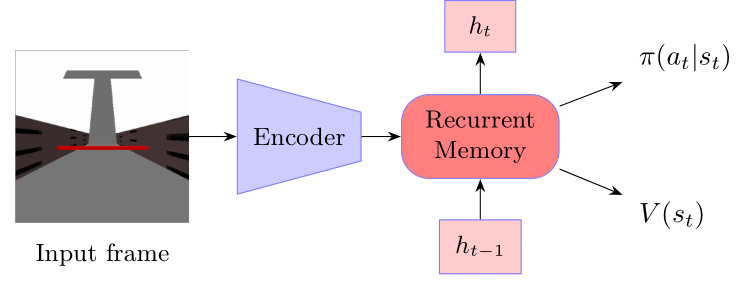
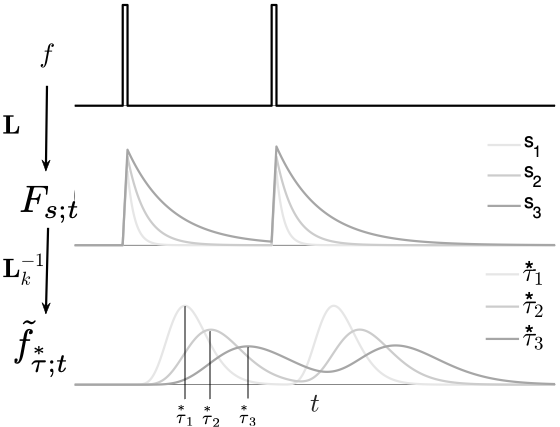
📊 实验亮点
实验结果表明,与使用LSTM等传统循环记忆架构构建的Agent相比,该方法构建的Agent可以在各种时间尺度上稳健地学习。具体的性能数据和提升幅度在摘要中没有给出,需要参考论文正文。但总体而言,该方法在处理不同时间尺度任务时表现出更强的鲁棒性和泛化能力,验证了时间尺度不变记忆模型在深度强化学习中的有效性。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、金融交易等需要处理复杂时间动态的领域。例如,在机器人控制中,机器人需要根据过去的行为和环境状态来预测未来的状态,并做出相应的决策。时间尺度不变记忆模型可以帮助机器人更好地处理不同时间尺度的信息,从而提高其控制精度和鲁棒性。在金融交易中,交易员需要分析历史数据来预测未来的市场趋势,并制定交易策略。该模型可以帮助交易员更好地捕捉市场中的长期依赖关系,从而提高其盈利能力。
📄 摘要(原文)
The ability to estimate temporal relationships is critical for both animals and artificial agents. Cognitive science and neuroscience provide remarkable insights into behavioral and neural aspects of temporal credit assignment. In particular, scale invariance of learning dynamics, observed in behavior and supported by neural data, is one of the key principles that governs animal perception: proportional rescaling of temporal relationships does not alter the overall learning efficiency. Here we integrate a computational neuroscience model of scale invariant memory into deep reinforcement learning (RL) agents. We first provide a theoretical analysis and then demonstrate through experiments that such agents can learn robustly across a wide range of temporal scales, unlike agents built with commonly used recurrent memory architectures such as LSTM. This result illustrates that incorporating computational principles from neuroscience and cognitive science into deep neural networks can enhance adaptability to complex temporal dynamics, mirroring some of the core properties of human learning.