Critical-Questions-of-Thought: Steering LLM reasoning with Argumentative Querying
作者: Federico Castagna, Isabel Sassoon, Simon Parsons
分类: cs.AI, cs.CL
发布日期: 2024-12-19
💡 一句话要点
利用论证查询中的批判性问题,引导LLM进行更有效的推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 逻辑推理 数学推理 论证理论 批判性问题
📋 核心要点
- 现有LLM在逻辑和数学推理方面存在不足,难以泛化到未见过的或与训练数据差异大的问题。
- 论文核心思想是利用论证理论中的批判性问题,引导LLM检查推理过程中的逻辑错误并进行纠正。
- 实验结果表明,该方法能够有效提升LLM在推理和数学任务上的性能,优于基线方法和CoT。
📝 摘要(中文)
研究表明,尽管人工智能研究取得了突破性进展,但即使是最先进的大型语言模型(LLM)在执行逻辑和数学推理时仍然面临挑战。结果表明,LLM仍然主要作为(高度先进的)数据模式识别器,在泛化和解决模型以前从未见过或与训练数据中的样本不接近的推理问题时表现不佳。为了解决这个问题,本文利用论证理论中的批判性问题概念,特别关注图尔敏的论证模型。研究表明,使用这些批判性问题可以提高LLM的推理能力。通过探究模型推理过程背后的原理,LLM可以评估是否发生了逻辑错误,并在向用户提示提供最终回复之前纠正它。其基本思想来自任何有效论证程序的黄金标准:结论的有效性取决于其是否由已接受的前提所蕴含。或者,用不完整信息和推定逻辑来解释这种亚里士多德原则,结论的有效性取决于是否被证明是错误的。这种方法成功地通过推理管道引导模型的输出,从而在基线及其思维链(CoT)实现方面获得更好的性能。为此,对所提出的方法在MT-Bench推理和数学任务中跨一系列LLM进行了广泛的评估。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在逻辑和数学推理方面的不足,尤其是在面对未见过的或与训练数据差异较大的问题时,LLM难以进行有效的泛化和推理。现有方法,如直接提示或思维链(CoT),虽然在一定程度上提高了LLM的推理能力,但仍然容易出现逻辑错误,导致推理结果不准确。
核心思路:论文的核心思路是借鉴论证理论中的批判性问题(Critical Questions)的概念,通过向LLM提出一系列针对其推理过程的质疑,促使LLM反思和检查自身的逻辑推理,从而发现并纠正潜在的错误。这种方法模拟了人类在论证过程中不断质疑和反驳的思维模式,旨在提高LLM推理的可靠性和准确性。
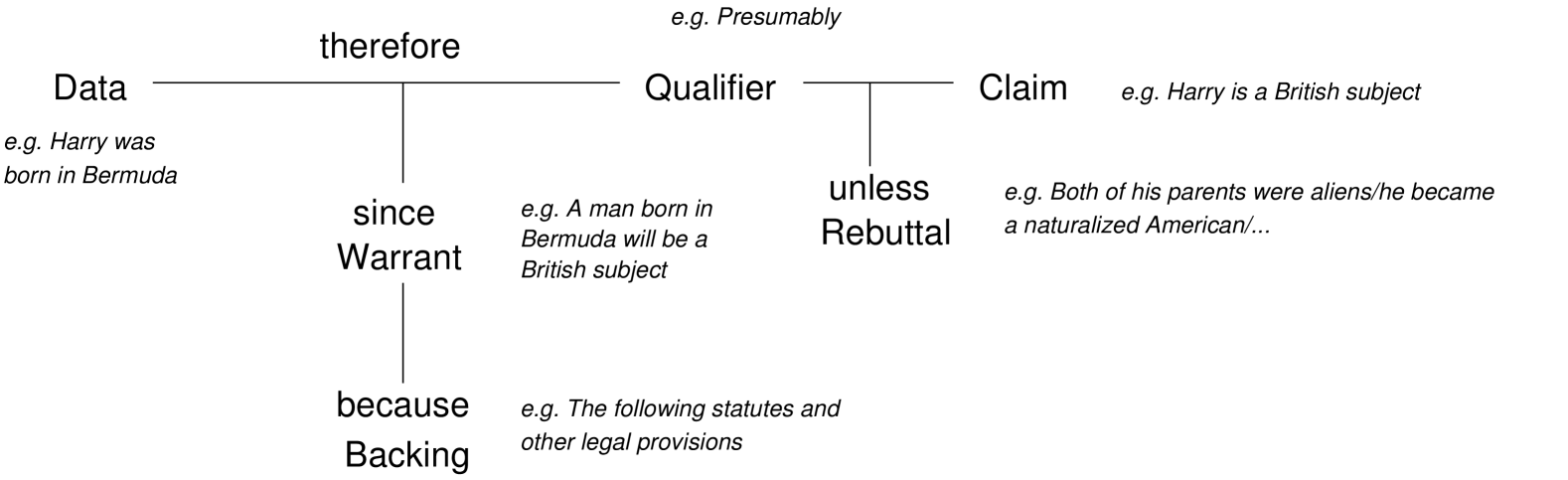
技术框架:该方法构建了一个推理管道,主要包含以下几个阶段:1) 接收用户的问题提示;2) LLM根据问题进行初步推理,生成初步答案和推理过程;3) 根据图尔敏论证模型,针对LLM的推理过程生成一系列批判性问题;4) LLM回答这些批判性问题,并根据回答结果反思和修正其推理过程;5) LLM输出最终的答案。
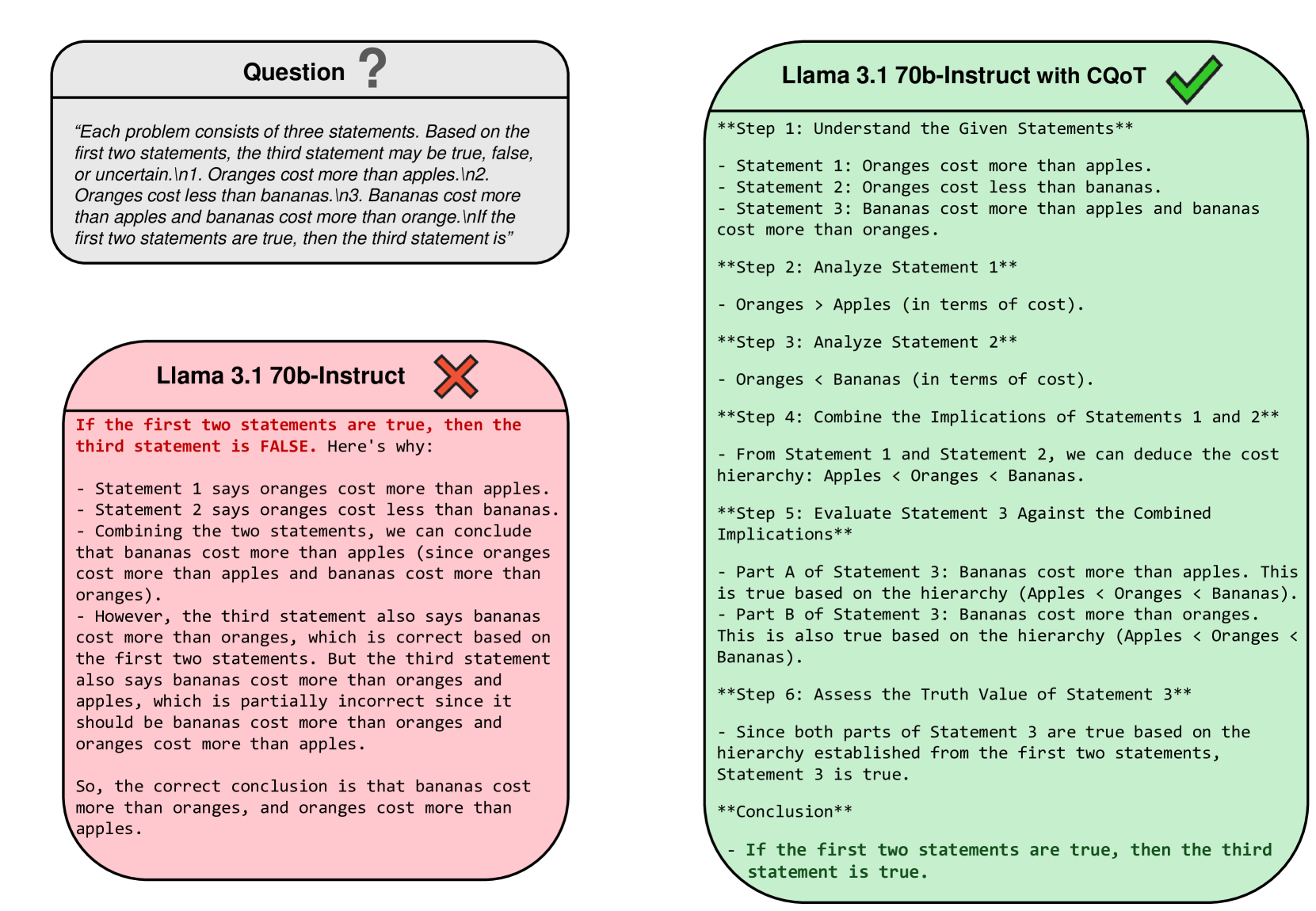
关键创新:该方法最重要的技术创新点在于将论证理论中的批判性问题引入到LLM的推理过程中。与传统的CoT方法相比,该方法不仅仅是简单地引导LLM生成推理步骤,而是通过批判性问题来主动地引导LLM进行自我反思和纠错,从而提高推理的可靠性。
关键设计:关键设计在于如何根据图尔敏论证模型生成有效的批判性问题。具体来说,针对LLM推理过程中的每个步骤,都生成一系列旨在质疑该步骤的合理性、前提的有效性、以及结论的正确性的问题。例如,如果LLM使用了某个前提,则会质疑该前提是否成立;如果LLM得出了某个结论,则会质疑该结论是否能够从前提中合理推导出来。这些问题的设计需要充分考虑LLM的推理特点和潜在的错误类型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在MT-Bench推理和数学任务上,该方法显著优于基线方法和CoT。具体而言,在多个LLM模型上,该方法都取得了明显的性能提升,尤其是在需要复杂逻辑推理的任务上。这些结果表明,通过引入批判性问题,可以有效地提高LLM的推理能力。
🎯 应用场景
该研究成果可应用于需要高可靠性推理的领域,如医疗诊断、金融分析、法律咨询等。通过提高LLM的推理能力,可以辅助专业人士进行决策,减少因推理错误而导致的风险。未来,该方法有望扩展到更复杂的推理场景,并与其他技术相结合,构建更加智能和可靠的人工智能系统。
📄 摘要(原文)
Studies have underscored how, regardless of the recent breakthrough and swift advances in AI research, even state-of-the-art Large Language models (LLMs) continue to struggle when performing logical and mathematical reasoning. The results seem to suggest that LLMs still work as (highly advanced) data pattern identifiers, scoring poorly when attempting to generalise and solve reasoning problems the models have never previously seen or that are not close to samples presented in their training data. To address this compelling concern, this paper makes use of the notion of critical questions from the literature on argumentation theory, focusing in particular on Toulmin's model of argumentation. We show that employing these critical questions can improve the reasoning capabilities of LLMs. By probing the rationale behind the models' reasoning process, the LLM can assess whether some logical mistake is occurring and correct it before providing the final reply to the user prompt. The underlying idea is drawn from the gold standard of any valid argumentative procedure: the conclusion is valid if it is entailed by accepted premises. Or, to paraphrase such Aristotelian principle in a real-world approximation, characterised by incomplete information and presumptive logic, the conclusion is valid if not proved otherwise. This approach successfully steers the models' output through a reasoning pipeline, resulting in better performance against the baseline and its Chain-of-Thought (CoT) implementation. To this end, an extensive evaluation of the proposed approach on the MT-Bench Reasoning and Math tasks across a range of LLMs is provided.