A Survey on Large Language Model-based Agents for Statistics and Data Science
作者: Maojun Sun, Ruijian Han, Binyan Jiang, Houduo Qi, Defeng Sun, Yancheng Yuan, Jian Huang
分类: cs.AI, cs.CL, cs.LG, stat.OT
发布日期: 2024-12-18 (更新: 2025-09-14)
期刊: Am. Statist. (2025) 1-14
DOI: 10.1080/00031305.2025.2561140
💡 一句话要点
综述:基于大型语言模型的数据科学智能体,简化数据分析流程。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数据智能体 数据科学 自动化分析 智能代理
📋 核心要点
- 传统数据分析流程复杂,专业门槛高,阻碍了非专业人士利用数据。
- 利用大型语言模型构建数据智能体,通过规划、推理等能力,自动化数据分析流程。
- 通过案例分析,展示了数据智能体在实际场景中的应用,并指出了未来发展方向。
📝 摘要(中文)
近年来,基于大型语言模型(LLM)的数据科学智能体,即“数据智能体”,已显示出改变传统数据分析模式的巨大潜力。本综述概述了基于LLM的数据智能体的演变、能力和应用,强调了它们在简化复杂数据任务和降低非专业用户入门门槛方面的作用。我们探讨了基于LLM的框架设计的当前趋势,详细介绍了诸如规划、推理、反思、多智能体协作、用户界面、知识集成和系统设计等关键特征,这些特征使智能体能够以最少的人工干预来解决以数据为中心的问题。此外,我们分析了几个案例研究,以展示各种数据智能体在实际场景中的实际应用。最后,我们确定了关键挑战,并提出了未来的研究方向,以推动数据智能体发展成为智能统计分析软件。
🔬 方法详解
问题定义:传统数据分析流程复杂,需要专业的数据科学家进行操作,成本高昂且效率较低。现有方法难以让非专业人士轻松地进行数据分析,存在较高的技术壁垒。因此,如何降低数据分析的门槛,让更多人能够利用数据成为一个重要的问题。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大能力,构建数据智能体,使其能够自动化地完成数据分析任务。通过赋予智能体规划、推理、反思等能力,使其能够理解用户意图,并自主地执行数据分析流程。
技术框架:论文综述了基于LLM的数据智能体的整体架构和流程,主要包括以下模块:规划模块(负责制定数据分析方案)、推理模块(负责执行数据分析步骤)、反思模块(负责评估分析结果并进行改进)、多智能体协作模块(多个智能体协同完成复杂任务)、用户界面模块(提供用户友好的交互方式)、知识集成模块(整合外部知识以提升分析能力)和系统设计模块(保证系统的稳定性和可扩展性)。
关键创新:该综述的关键创新在于系统性地总结了基于LLM的数据智能体的研究进展,并指出了其在简化数据分析流程、降低用户门槛方面的潜力。通过对现有框架的分析,揭示了数据智能体的关键特征和设计要素。
关键设计:论文主要关注数据智能体的整体框架设计,并未涉及具体的参数设置、损失函数或网络结构等技术细节。未来的研究方向包括如何设计更有效的规划和推理算法,如何提升智能体的反思能力,以及如何更好地整合外部知识。
🖼️ 关键图片
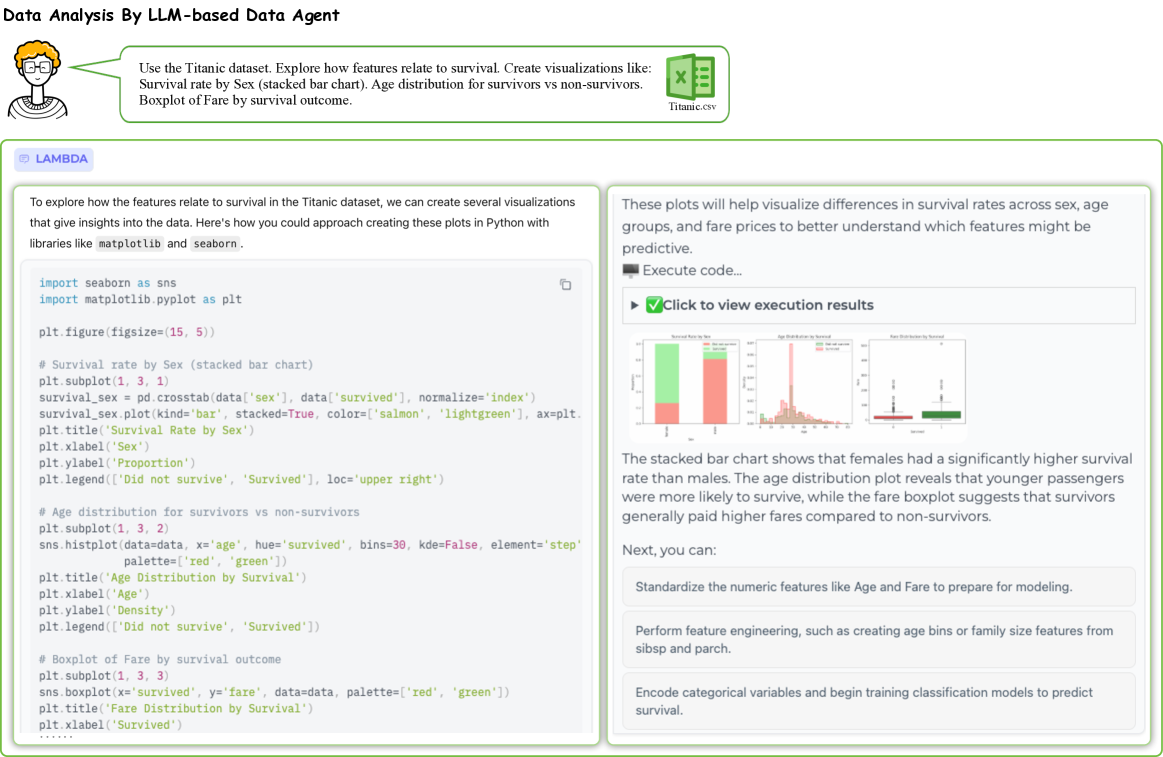
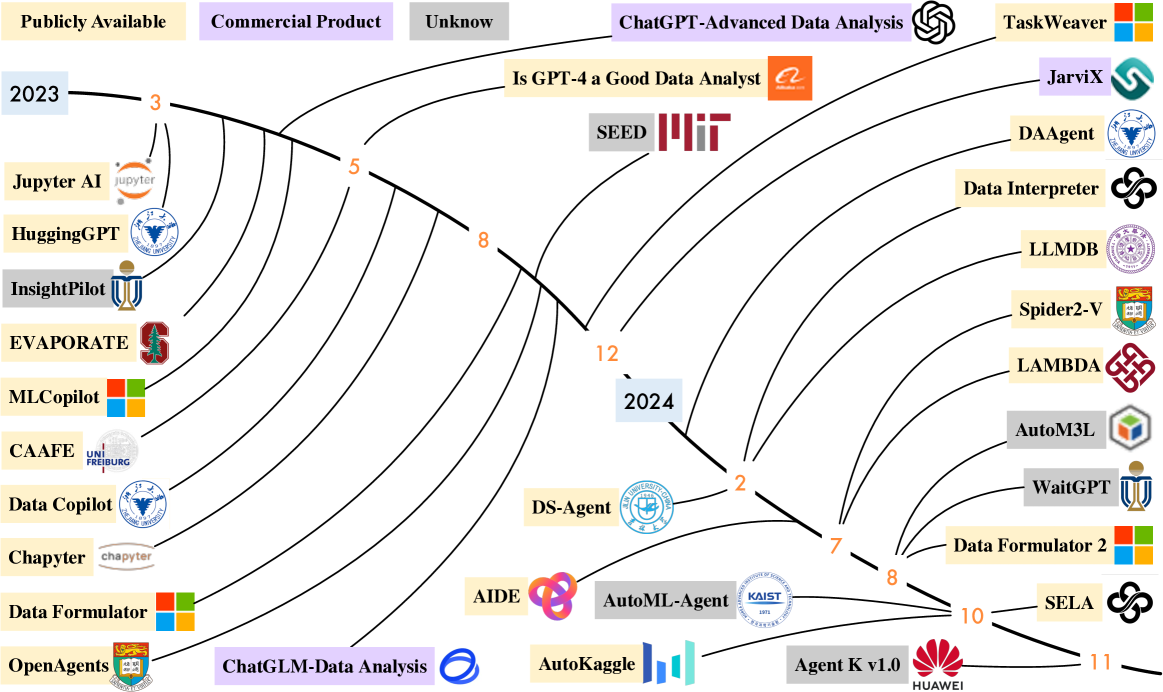
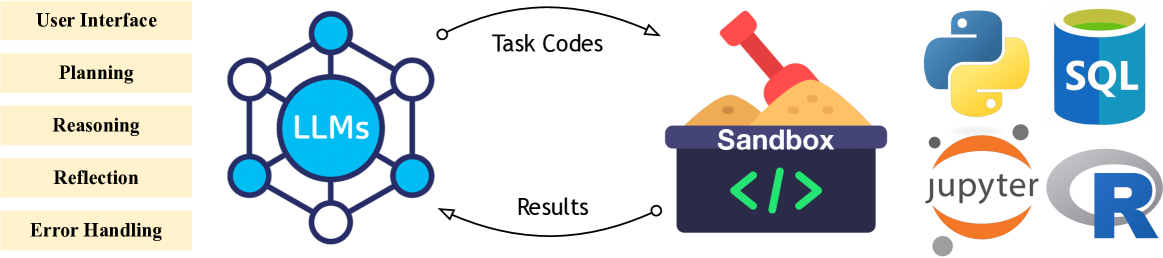
📊 实验亮点
该综述通过案例研究展示了数据智能体在实际场景中的应用,例如自动化报告生成、异常检测等。虽然没有提供具体的性能数据,但强调了数据智能体在简化数据分析流程和降低用户门槛方面的优势。未来的研究可以关注如何进一步提升数据智能体的准确性和效率。
🎯 应用场景
该研究成果可应用于多个领域,例如商业智能、金融分析、医疗健康等。通过数据智能体,非专业人士也能轻松进行数据分析,从而做出更明智的决策。未来,数据智能体有望成为企业和个人进行数据驱动决策的重要工具。
📄 摘要(原文)
In recent years, data science agents powered by Large Language Models (LLMs), known as "data agents," have shown significant potential to transform the traditional data analysis paradigm. This survey provides an overview of the evolution, capabilities, and applications of LLM-based data agents, highlighting their role in simplifying complex data tasks and lowering the entry barrier for users without related expertise. We explore current trends in the design of LLM-based frameworks, detailing essential features such as planning, reasoning, reflection, multi-agent collaboration, user interface, knowledge integration, and system design, which enable agents to address data-centric problems with minimal human intervention. Furthermore, we analyze several case studies to demonstrate the practical applications of various data agents in real-world scenarios. Finally, we identify key challenges and propose future research directions to advance the development of data agents into intelligent statistical analysis software.