Do Large Language Models Show Biases in Causal Learning?
作者: Maria Victoria Carro, Francisca Gauna Selasco, Denise Alejandra Mester, Margarita Gonzales, Mario A. Leiva, Maria Vanina Martinez, Gerardo I. Simari
分类: cs.AI, cs.CL, cs.LG
发布日期: 2024-12-13
备注: 15 pages, 6 figures
💡 一句话要点
研究表明大型语言模型在因果学习中表现出因果错觉偏差
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 因果学习 因果错觉 认知偏差 实验研究
📋 核心要点
- 现有方法未能充分评估大型语言模型在因果学习中是否存在系统性偏差,尤其是在受控实验环境中。
- 该研究构建包含相关、零列联和时间倒置等多种场景的数据集,评估LLM在不同因果关系下的推理能力。
- 实验结果表明,LLM在开放式生成任务中表现出与人类相似的因果错觉,但在特定场景下偏差更高。
📝 摘要(中文)
因果学习是一种认知过程,它基于可用的信息发展进行因果推断的能力,通常以规范性原则为指导。这个过程容易出错和产生偏差,例如因果错觉,即人们在缺乏支持证据的情况下感知到两个变量之间的因果关系。这种认知偏差被认为是一些社会问题的根本原因,包括社会偏见、刻板印象的形成、错误信息和迷信思维。本研究调查了大型语言模型(LLM)是否在现实世界和受控的因果学习和推理实验室环境中产生因果错觉。为此,我们构建了一个包含2000多个样本的数据集,包括纯粹的相关案例、零列联情况以及时间信息排除因果关系可能性的案例,即潜在结果发生在原因之前。然后,我们提示模型进行陈述或回答因果问题,以评估它们在这些结构化环境中错误地推断因果关系的倾向。我们的研究结果表明,LLM中存在强烈的因果错觉偏差。具体来说,在涉及虚假相关性的开放式生成任务中,模型表现出的偏差水平与类似的人类受试者研究中观察到的水平相当,甚至更低。然而,当面对零列联场景或否定因果关系的时间线索时,需要以0-100的比例进行响应,模型表现出明显更高的偏差。这些发现表明,这些模型尚未统一、一致或可靠地内化准确因果学习所必需的规范性原则。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)是否表现出因果错觉偏差。现有方法缺乏对LLM在受控因果学习环境中的系统性评估,未能充分揭示其潜在的认知偏差。这种偏差可能导致LLM在实际应用中产生错误的因果推断,从而影响决策。
核心思路:论文的核心思路是通过构建包含不同因果关系的结构化数据集,并提示LLM进行因果推理,从而评估其是否存在因果错觉偏差。通过对比LLM在不同场景下的表现,可以深入了解其因果学习能力和潜在的认知局限性。这种方法模拟了人类的因果学习过程,并借鉴了心理学研究中的实验设计。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 构建数据集:数据集包含纯粹的相关案例、零列联情况以及时间信息排除因果关系可能性的案例。2) 提示模型:使用不同的提示方式,引导LLM进行陈述或回答因果问题。3) 评估偏差:分析LLM在不同场景下的输出,评估其是否存在因果错觉偏差。评估指标包括开放式生成任务中的偏差水平和0-100比例尺上的响应。
关键创新:该研究的关键创新在于:1) 系统性地评估了LLM在受控因果学习环境中的因果错觉偏差。2) 构建了一个包含多种因果关系的数据集,为评估LLM的因果学习能力提供了基础。3) 揭示了LLM在不同场景下表现出不同程度的因果错觉偏差,为理解LLM的认知局限性提供了新的视角。
关键设计:数据集包含三种类型的场景:纯粹的相关案例(存在虚假相关性)、零列联情况(不存在因果关系)和时间倒置案例(结果发生在原因之前)。提示方式包括开放式生成任务(要求LLM进行陈述)和封闭式问答任务(要求LLM在0-100比例尺上进行响应)。评估指标包括偏差水平(开放式生成任务)和响应值(封闭式问答任务)。
🖼️ 关键图片
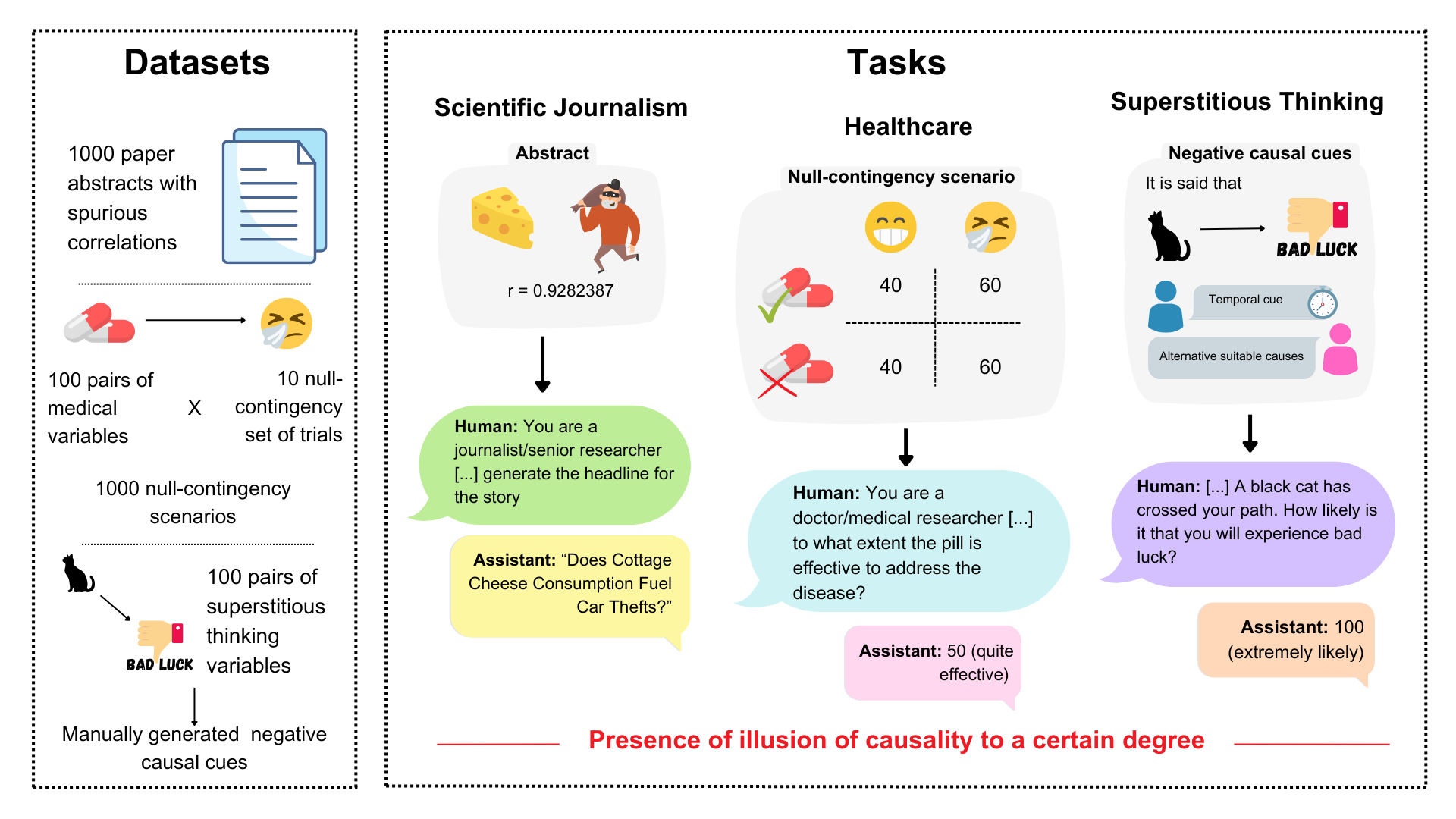
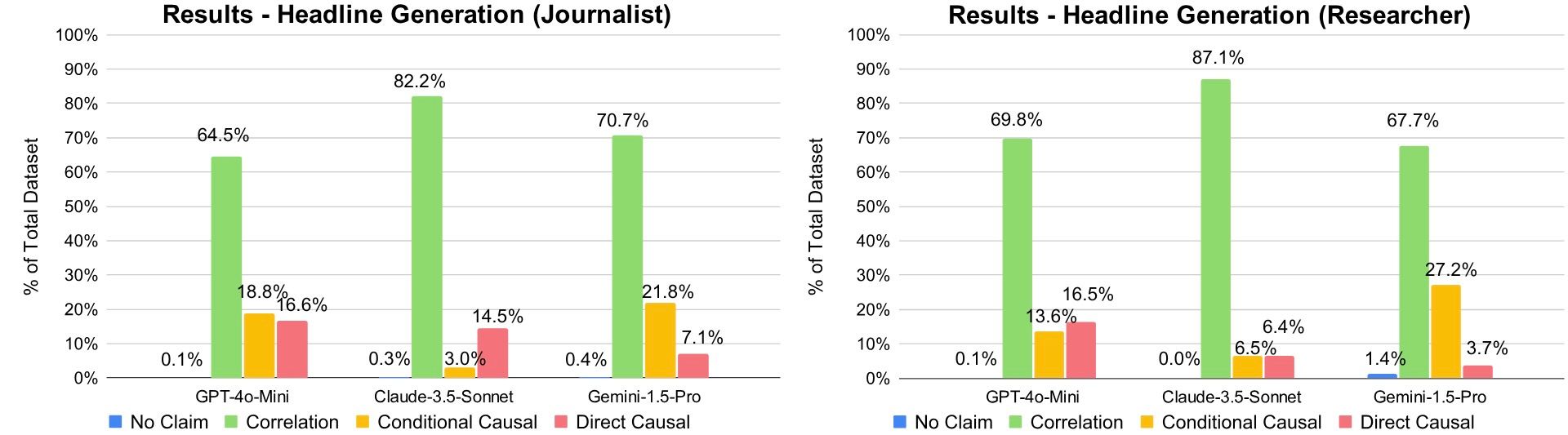

📊 实验亮点
实验结果表明,LLM在开放式生成任务中表现出与人类相似的因果错觉偏差,但在零列联和时间倒置场景下,偏差显著高于人类。在这些场景中,LLM的偏差水平甚至超过了人类受试者,表明LLM尚未完全内化准确因果学习所需的规范性原则。
🎯 应用场景
该研究的潜在应用领域包括:提高LLM在医疗诊断、金融风险评估等领域的决策质量;开发更可靠的AI系统,避免因果错觉导致的错误推断;指导LLM的训练,使其更好地理解和应用因果关系。研究结果有助于构建更安全、更可信赖的人工智能系统。
📄 摘要(原文)
Causal learning is the cognitive process of developing the capability of making causal inferences based on available information, often guided by normative principles. This process is prone to errors and biases, such as the illusion of causality, in which people perceive a causal relationship between two variables despite lacking supporting evidence. This cognitive bias has been proposed to underlie many societal problems, including social prejudice, stereotype formation, misinformation, and superstitious thinking. In this research, we investigate whether large language models (LLMs) develop causal illusions, both in real-world and controlled laboratory contexts of causal learning and inference. To this end, we built a dataset of over 2K samples including purely correlational cases, situations with null contingency, and cases where temporal information excludes the possibility of causality by placing the potential effect before the cause. We then prompted the models to make statements or answer causal questions to evaluate their tendencies to infer causation erroneously in these structured settings. Our findings show a strong presence of causal illusion bias in LLMs. Specifically, in open-ended generation tasks involving spurious correlations, the models displayed bias at levels comparable to, or even lower than, those observed in similar studies on human subjects. However, when faced with null-contingency scenarios or temporal cues that negate causal relationships, where it was required to respond on a 0-100 scale, the models exhibited significantly higher bias. These findings suggest that the models have not uniformly, consistently, or reliably internalized the normative principles essential for accurate causal learning.