Cultural Evolution of Cooperation among LLM Agents
作者: Aron Vallinder, Edward Hughes
分类: cs.MA, cs.AI
发布日期: 2024-12-13
备注: 15 pages, 6 figures
💡 一句话要点
研究LLM智能体文化演进,揭示合作行为差异及社会规范形成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM智能体 合作演化 社会规范 迭代博弈 间接互惠
📋 核心要点
- 现有研究对大规模部署的LLM智能体之间的长期交互动态缺乏了解,尤其是在合作行为和社会规范演化方面。
- 通过模拟LLM智能体在迭代捐赠者博弈中的多代交互,研究其间接互惠行为的演变,探索合作规范的形成。
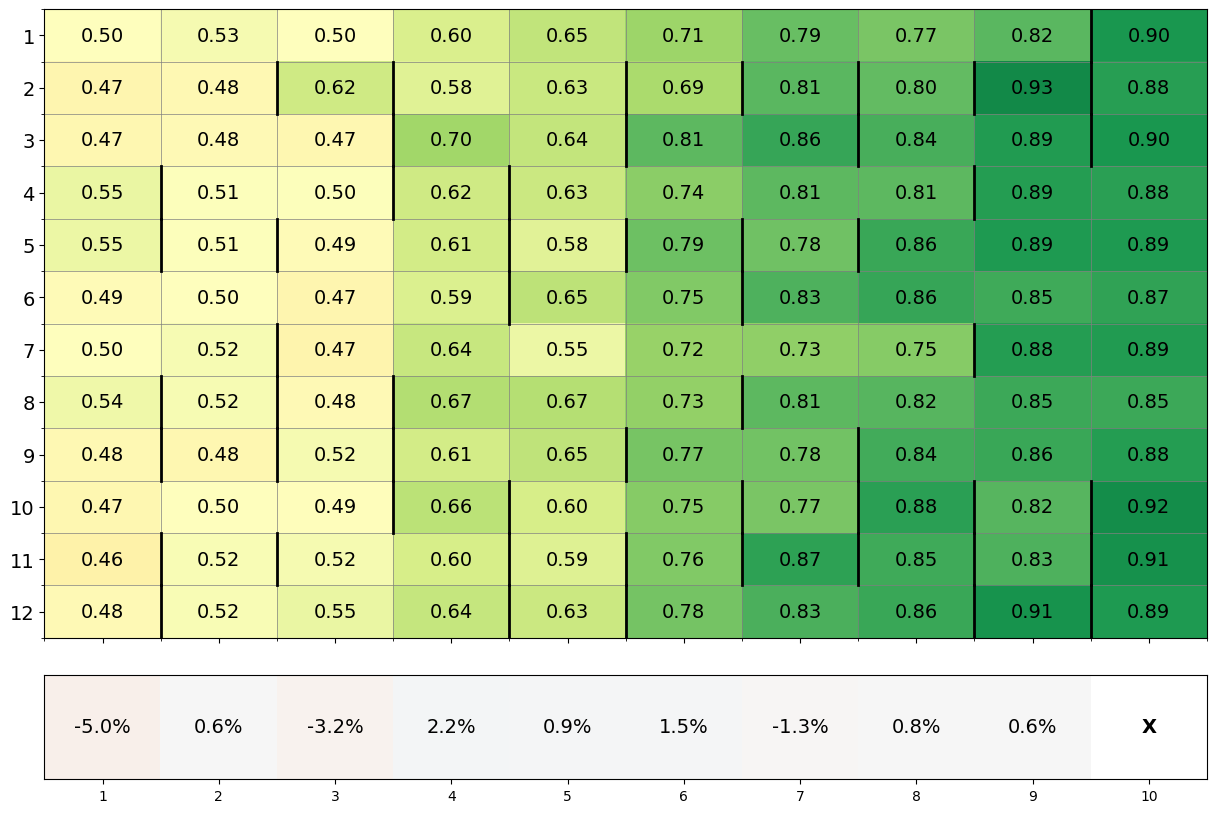
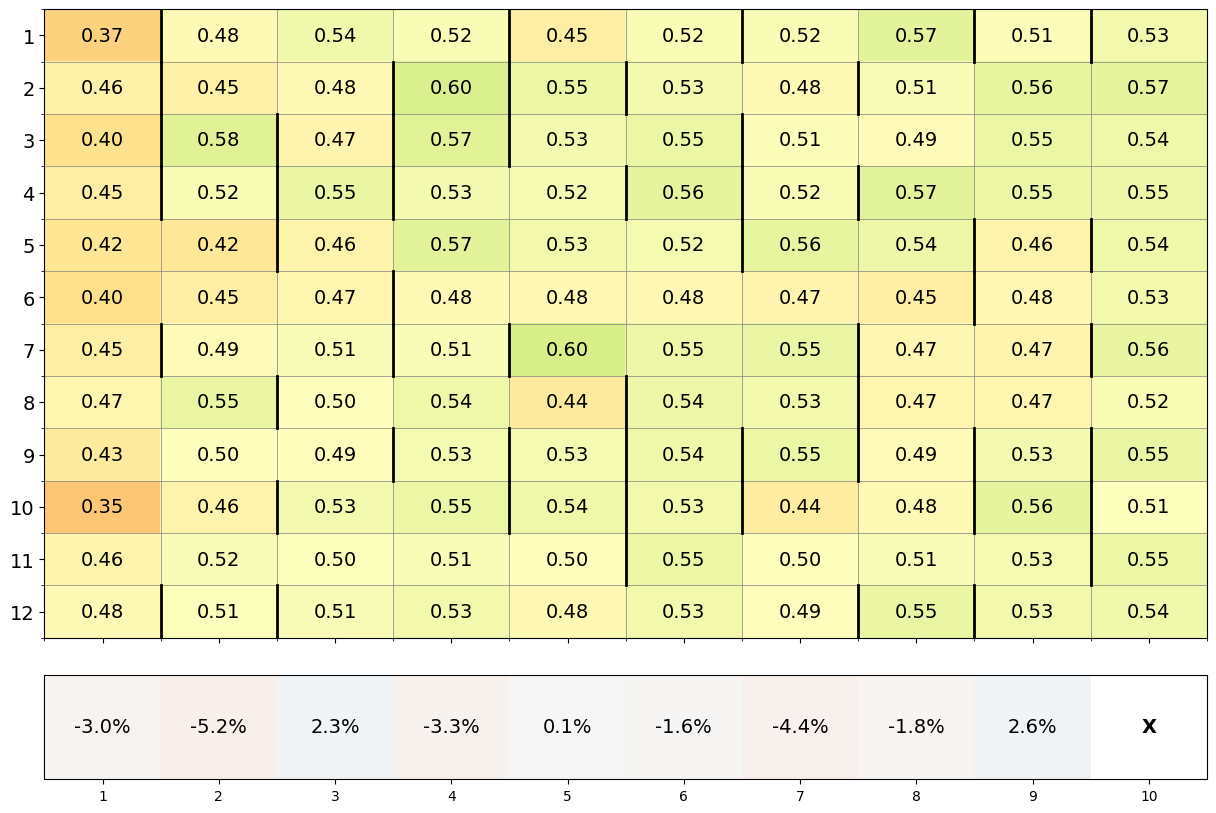
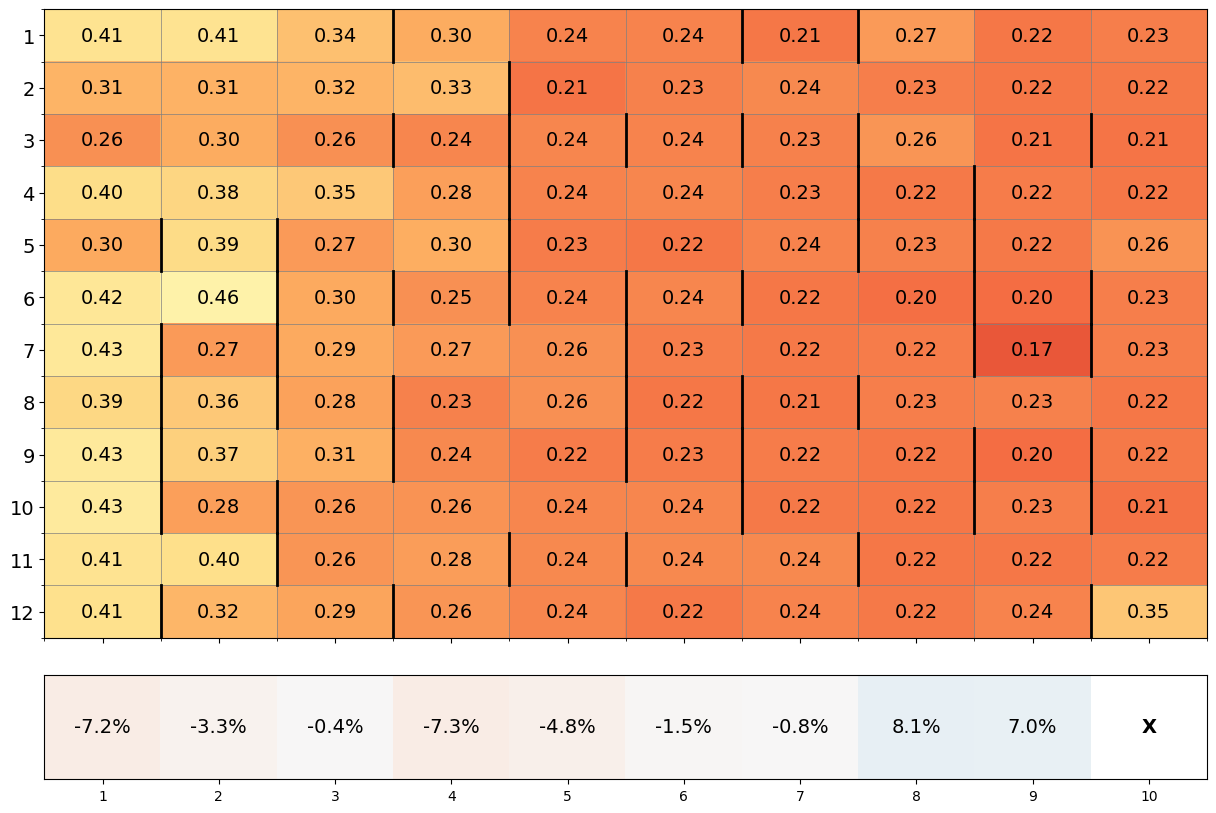
- 实验表明,不同LLM模型(Claude 3.5 Sonnet、Gemini 1.5 Flash、GPT-4o)在合作演化方面存在显著差异,且对初始条件敏感。
📝 摘要(中文)
大型语言模型(LLMs)为构建通用人工智能体提供了一个引人注目的基础。这些智能体可能很快就会大规模部署在现实世界中,代表个人(例如,AI助手)或群体(例如,AI加速的公司)的利益。目前,对于多个LLM智能体经过多代迭代部署的交互动态知之甚少。本文研究了LLM智能体“社会”是否能在面对背叛激励时学习互利的社会规范,这是人类社会的一个显著特征,对文明的成功至关重要。具体来说,我们研究了LLM智能体在经典迭代捐赠者博弈中进行多代演化时,间接互惠行为的演变,其中智能体可以观察同行的近期行为。我们发现,不同基础模型之间的合作演变差异显著,Claude 3.5 Sonnet智能体社会获得的平均分数明显高于Gemini 1.5 Flash,而Gemini 1.5 Flash又优于GPT-4o。此外,Claude 3.5 Sonnet可以利用额外的惩罚机制来获得更高的分数,而Gemini 1.5 Flash和GPT-4o则无法做到。对于每个模型类别,我们还观察到不同随机种子之间涌现行为的差异,这表明存在一种尚未充分研究的对初始条件的敏感依赖性。我们认为,我们的评估体系可以激发一种廉价且信息丰富的新型LLM基准,重点关注LLM智能体部署对社会合作基础设施的影响。
🔬 方法详解
问题定义:论文旨在研究在多智能体环境中,LLM智能体能否自发演化出合作行为和社会规范。现有方法缺乏对LLM智能体长期交互动态的深入研究,尤其是在存在背叛激励的情况下,智能体如何学习互利合作,以及不同LLM模型在合作演化上的差异。
核心思路:论文的核心思路是将LLM智能体置于一个模拟的社会环境中,通过迭代博弈的方式,观察它们在多代交互中如何学习和演化合作策略。这种方法模拟了人类社会的合作机制,并允许研究者探索不同LLM模型在合作行为上的差异。通过观察智能体的行为和得分,可以评估其合作能力和社会规范学习能力。
技术框架:整体框架包括以下几个主要阶段: 1. 环境设置:构建一个迭代捐赠者博弈环境,其中LLM智能体可以观察其他智能体的行为。 2. 智能体交互:让LLM智能体在博弈环境中进行多代交互,每一代智能体根据上一代智能体的行为调整自己的策略。 3. 行为观察与评估:记录每个智能体的行为和得分,分析合作行为的演变趋势。 4. 模型对比:对比不同LLM模型(Claude 3.5 Sonnet、Gemini 1.5 Flash、GPT-4o)在合作演化上的表现。
关键创新:论文的关键创新在于: 1. 多代演化模拟:通过模拟LLM智能体的多代交互,研究合作行为的长期演化。 2. 模型差异性分析:对比不同LLM模型在合作演化上的差异,揭示模型特性对合作行为的影响。 3. 惩罚机制研究:探索惩罚机制对LLM智能体合作行为的影响。
关键设计: 1. 迭代捐赠者博弈:使用经典的迭代捐赠者博弈作为智能体交互的环境,该博弈能够模拟合作与背叛之间的权衡。 2. 观察窗口:智能体可以观察其他智能体最近的行为,从而形成对其他智能体声誉的判断。 3. 惩罚机制:允许智能体对不合作的智能体进行惩罚,以促进合作行为的形成。 4. 随机种子:使用不同的随机种子来初始化智能体,以研究初始条件对合作演化的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,不同LLM模型在合作演化方面存在显著差异。Claude 3.5 Sonnet智能体社会获得的平均分数明显高于Gemini 1.5 Flash,而Gemini 1.5 Flash又优于GPT-4o。此外,Claude 3.5 Sonnet能够有效利用惩罚机制来进一步提高合作水平,而Gemini 1.5 Flash和GPT-4o则未能成功利用惩罚机制。研究还发现,合作行为的演化对初始条件具有敏感依赖性。
🎯 应用场景
该研究成果可应用于开发更具社会责任感和合作精神的AI智能体,例如AI助手、AI驱动的客户服务系统等。通过理解LLM智能体合作行为的演化规律,可以设计出更有效的机制来促进智能体之间的合作,从而提高整体效率和公平性。此外,该研究也为评估和比较不同LLM模型的社会适应性提供了一种新的方法。
📄 摘要(原文)
Large language models (LLMs) provide a compelling foundation for building generally-capable AI agents. These agents may soon be deployed at scale in the real world, representing the interests of individual humans (e.g., AI assistants) or groups of humans (e.g., AI-accelerated corporations). At present, relatively little is known about the dynamics of multiple LLM agents interacting over many generations of iterative deployment. In this paper, we examine whether a "society" of LLM agents can learn mutually beneficial social norms in the face of incentives to defect, a distinctive feature of human sociality that is arguably crucial to the success of civilization. In particular, we study the evolution of indirect reciprocity across generations of LLM agents playing a classic iterated Donor Game in which agents can observe the recent behavior of their peers. We find that the evolution of cooperation differs markedly across base models, with societies of Claude 3.5 Sonnet agents achieving significantly higher average scores than Gemini 1.5 Flash, which, in turn, outperforms GPT-4o. Further, Claude 3.5 Sonnet can make use of an additional mechanism for costly punishment to achieve yet higher scores, while Gemini 1.5 Flash and GPT-4o fail to do so. For each model class, we also observe variation in emergent behavior across random seeds, suggesting an understudied sensitive dependence on initial conditions. We suggest that our evaluation regime could inspire an inexpensive and informative new class of LLM benchmarks, focussed on the implications of LLM agent deployment for the cooperative infrastructure of society.