You Name It, I Run It: An LLM Agent to Execute Tests of Arbitrary Projects
作者: Islem Bouzenia, Michael Pradel
分类: cs.SE, cs.AI
发布日期: 2024-12-13 (更新: 2025-04-30)
备注: PUBLISHED AT ISSTA 2025
期刊: ISSTA 2025
💡 一句话要点
提出ExecutionAgent,利用LLM自主执行任意项目的测试,提升测试执行成功率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动化测试 大型语言模型 软件测试 代码质量 持续集成
📋 核心要点
- 现有测试执行方法难以应对不同项目在编程语言、构建系统和测试框架上的多样性。
- ExecutionAgent利用LLM作为智能代理,通过元提示和迭代优化,自主构建和测试项目。
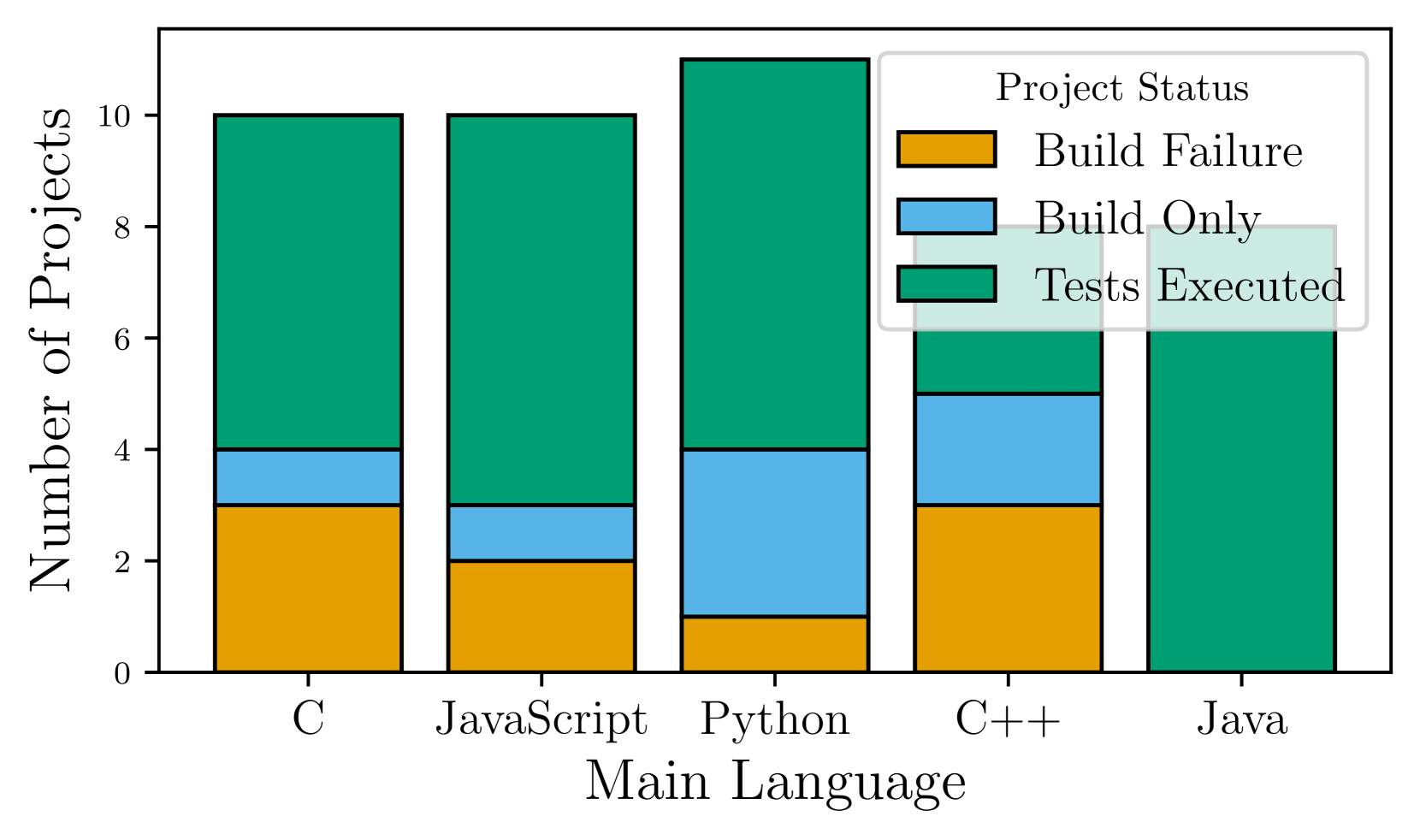
- 实验表明,ExecutionAgent在50个开源项目上成功执行了33个,相比现有技术提升了6.6倍。
📝 摘要(中文)
在许多场景中,执行项目的测试套件至关重要,例如评估代码质量和覆盖率、验证开发者或自动化工具所做的代码更改以及确保与依赖项的兼容性。尽管其重要性,但在实践中执行项目的测试套件可能具有挑战性,因为不同的项目使用不同的编程语言、软件生态系统、构建系统、测试框架和其他工具。这些挑战使得创建一种可靠的、通用的测试执行方法变得困难,该方法适用于不同的项目。本文提出ExecutionAgent,一种自动化技术,用于准备从源代码构建任意项目并运行其测试用例的脚本。受到人类开发者处理此任务方式的启发,我们的方法是一种基于大型语言模型(LLM)的代理,它可以自主执行命令并与主机系统交互。该代理使用元提示来收集有关给定项目相关最新技术的指南,并且它基于先前步骤的反馈迭代地改进其过程。我们的评估将ExecutionAgent应用于50个使用14种不同编程语言和许多不同构建和测试工具的开源项目。该方法成功执行了33/50个项目的测试套件,同时将ground truth测试套件执行的测试结果匹配到仅7.5%的偏差。这些结果比以前可用的最佳技术提高了6.6倍。该方法带来的成本是合理的,每个项目的平均执行时间为74分钟,LLM成本为0.16美元。我们设想ExecutionAgent可以作为开发人员、自动化编程工具和研究人员的宝贵工具,他们需要在各种项目中执行测试。
🔬 方法详解
问题定义:论文旨在解决自动化测试执行在面对不同项目时遇到的挑战。现有方法往往需要针对特定项目进行定制,无法通用地处理各种编程语言、构建系统和测试框架带来的复杂性。这使得大规模、自动化的测试变得困难,阻碍了代码质量评估、持续集成和软件维护等任务的效率。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大理解和推理能力,模拟人类开发者解决测试执行问题的过程。通过将LLM作为一个智能代理,使其能够自主地探索项目结构、理解构建和测试流程,并生成相应的执行脚本。这种方法避免了硬编码的规则和模板,从而提高了通用性和适应性。
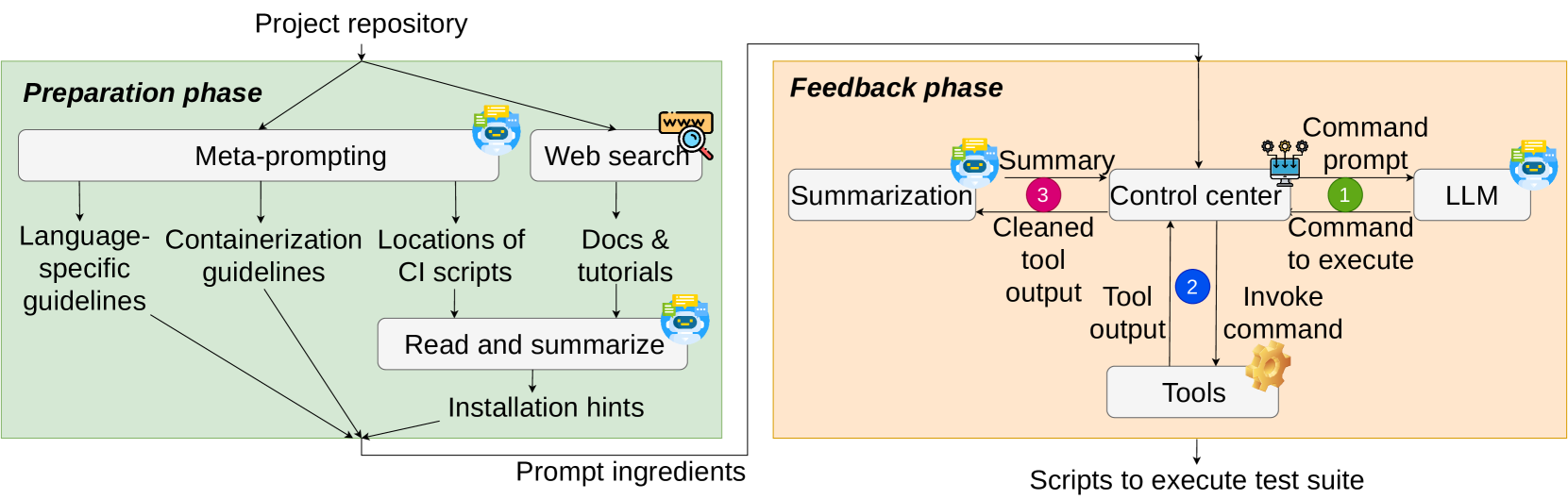
技术框架:ExecutionAgent的整体框架包含以下几个主要阶段:1) 项目分析:LLM代理分析项目源代码,识别编程语言、依赖关系和构建系统。2) 元提示:代理使用元提示技术,从外部资源(如文档、论坛)获取关于项目相关技术的最新信息和最佳实践。3) 脚本生成:基于项目分析和元提示,代理生成构建和测试执行脚本。4) 迭代执行与反馈:代理执行生成的脚本,并根据执行结果(如错误信息、测试结果)进行迭代优化。5) 结果验证:将代理执行的测试结果与ground truth进行比较,评估其准确性。
关键创新:ExecutionAgent的关键创新在于将LLM作为一个自主的测试执行代理,并引入了元提示和迭代优化机制。与传统的基于规则或模板的测试执行方法相比,ExecutionAgent能够更好地理解项目的语义,并根据实际情况进行调整。元提示使得代理能够获取最新的技术信息,避免了知识过时的问题。迭代优化则允许代理从错误中学习,逐步提高测试执行的成功率。
关键设计:ExecutionAgent的关键设计包括:1) LLM选择:论文使用了GPT-4等先进的LLM模型,以保证其强大的理解和推理能力。2) 元提示策略:设计了有效的元提示模板,引导LLM代理获取相关技术信息。3) 反馈机制:定义了清晰的错误信息和测试结果反馈机制,使代理能够有效地进行迭代优化。4) 安全措施:采取了安全措施,防止LLM代理执行恶意代码或访问敏感信息。
🖼️ 关键图片
📊 实验亮点
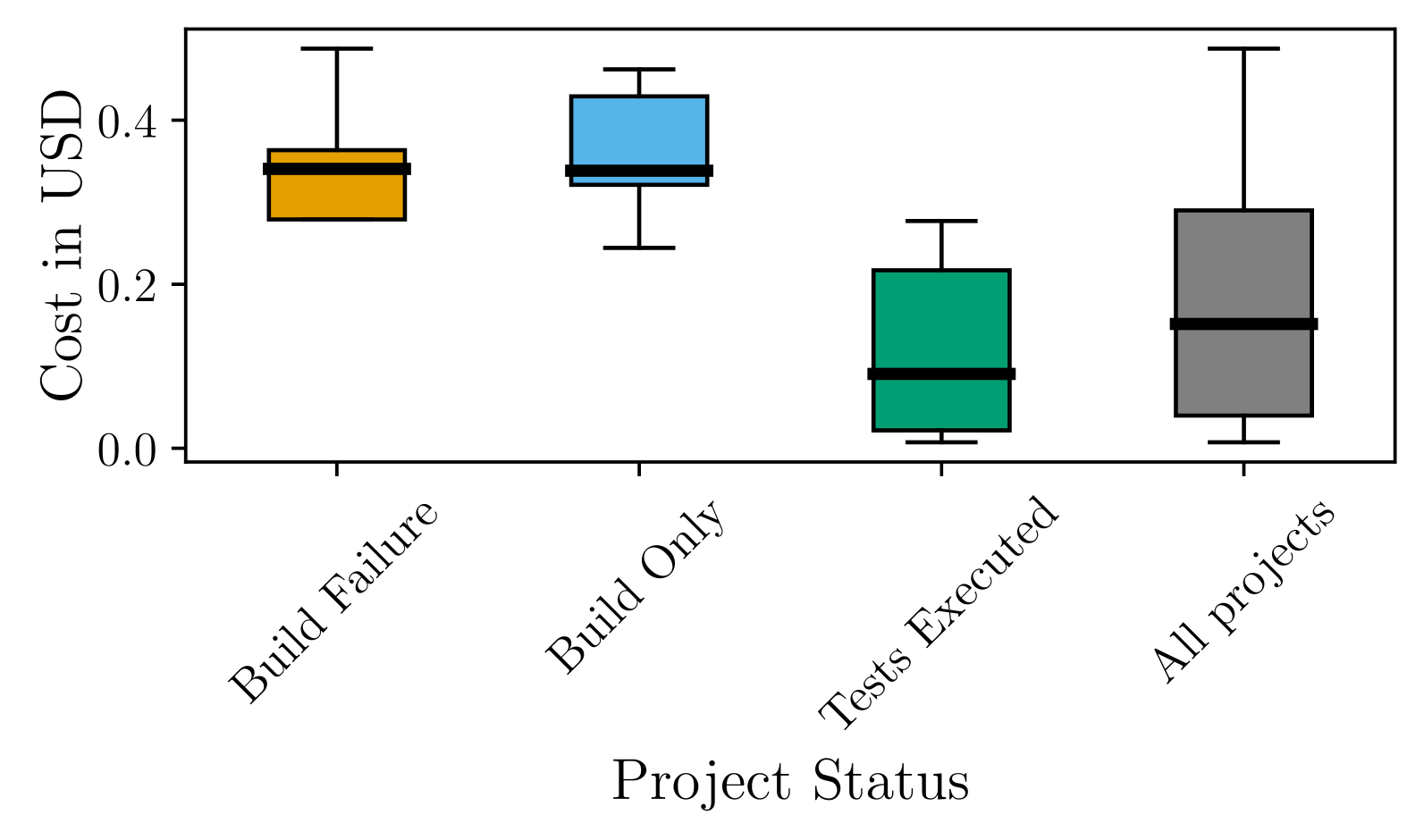
ExecutionAgent在包含14种编程语言的50个开源项目上进行了评估,成功执行了其中33个项目的测试套件,成功率达到66%。与现有最佳技术相比,测试执行成功率提高了6.6倍。同时,测试结果与ground truth的偏差仅为7.5%。平均每个项目的执行时间为74分钟,LLM成本为0.16美元,表明该方法在性能和成本方面都具有竞争力。
🎯 应用场景
ExecutionAgent可应用于软件开发生命周期的多个阶段,例如持续集成/持续部署(CI/CD)、代码质量评估、自动化漏洞检测和软件维护。它能够帮助开发者和自动化工具更高效地执行测试,提高代码质量,并降低软件维护成本。此外,该技术还可以用于教育领域,帮助学生快速上手新项目,并理解其构建和测试流程。
📄 摘要(原文)
The ability to execute the test suite of a project is essential in many scenarios, e.g., to assess code quality and code coverage, to validate code changes made by developers or automated tools, and to ensure compatibility with dependencies. Despite its importance, executing the test suite of a project can be challenging in practice because different projects use different programming languages, software ecosystems, build systems, testing frameworks, and other tools. These challenges make it difficult to create a reliable, universal test execution method that works across different projects. This paper presents ExecutionAgent, an automated technique that prepares scripts for building an arbitrary project from source code and running its test cases. Inspired by the way a human developer would address this task, our approach is a large language model (LLM)-based agent that autonomously executes commands and interacts with the host system. The agent uses meta-prompting to gather guidelines on the latest technologies related to the given project, and it iteratively refines its process based on feedback from the previous steps. Our evaluation applies ExecutionAgent to 50 open-source projects that use 14 different programming languages and many different build and testing tools. The approach successfully executes the test suites of 33/50 projects, while matching the test results of ground truth test suite executions with a deviation of only 7.5%. These results improve over the best previously available technique by 6.6x. The costs imposed by the approach are reasonable, with an execution time of 74 minutes and LLM costs of USD 0.16, on average per project. We envision ExecutionAgent to serve as a valuable tool for developers, automated programming tools, and researchers that need to execute tests across a wide variety of projects.