CSL-L2M: Controllable Song-Level Lyric-to-Melody Generation Based on Conditional Transformer with Fine-Grained Lyric and Musical Controls
作者: Li Chai, Donglin Wang
分类: eess.AS, cs.AI, cs.SD, eess.SP
发布日期: 2024-12-13 (更新: 2025-01-15)
备注: Accepted at AAAI-25
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
CSL-L2M:提出一种可控的歌词到旋律生成方法,通过细粒度的歌词和音乐控制生成高质量旋律。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 歌词到旋律生成 AI音乐生成 Transformer 可控生成 音乐表示学习
📋 核心要点
- 现有歌词到旋律生成方法难以学习歌词和旋律之间复杂的相关性,导致生成结果可控性差、质量不高且结构性不足。
- CSL-L2M通过引入REMI-Aligned音乐表示,并结合细粒度的歌词和音乐控制,利用Transformer解码器生成高质量旋律。
- 实验结果表明,CSL-L2M在旋律质量、可控性和结构性方面均优于现有方法,实现了显著的性能提升。
📝 摘要(中文)
歌词到旋律生成是人工智能音乐生成领域中一项极具挑战性的任务。由于歌词和旋律之间存在严格但又微弱的相关性,以往的方法存在可控性弱、生成质量低和结构性差等问题。为了解决这些挑战,我们提出了一种可控的歌曲级歌词到旋律生成方法CSL-L2M,该方法基于带有细粒度歌词和音乐控制的in-attention Transformer解码器,能够生成与给定歌词和用户指定的音乐属性相匹配的完整歌曲旋律。具体来说,我们首先引入了REMI-Aligned,这是一种新颖的音乐表示方法,它结合了歌词和旋律之间严格的音节级和句子级对齐,从而促进了精确的对齐建模。随后,从句子级的Transformer编码器独立提取的句子级语义歌词嵌入与词级的词性嵌入和音节级的音调嵌入相结合,作为细粒度的控制,以增强歌词对旋律生成的可控性。然后,我们引入了人工标注的音乐标签、句子级的统计音乐属性以及从预训练的VQ-VAE中提取的学习音乐特征,分别作为粗粒度、细粒度和高保真度的控制,从而使用户能够控制旋律生成。最后,利用in-attention Transformer解码器技术,通过上述歌词和音乐条件对完整歌曲的旋律生成进行细粒度的控制。实验结果表明,我们提出的CSL-L2M优于最先进的模型,生成具有更高质量、更好可控性和增强结构的旋律。演示和源代码可在https://lichaiustc.github.io/CSL-L2M/上找到。
🔬 方法详解
问题定义:论文旨在解决歌词到旋律生成任务中,现有方法可控性弱、生成质量低和结构性差的问题。现有方法难以准确捕捉歌词和旋律之间复杂且微妙的关系,导致生成的旋律与歌词的匹配度不高,缺乏用户可控性,并且整体音乐结构不够合理。
核心思路:论文的核心思路是通过引入细粒度的歌词和音乐控制,增强模型对生成过程的控制能力。具体来说,利用音节级和句子级的对齐信息,以及多种音乐特征,为模型提供更丰富的上下文信息,从而生成更符合用户期望的旋律。这种设计旨在弥合歌词和旋律之间的语义鸿沟,并提高生成结果的质量和可控性。
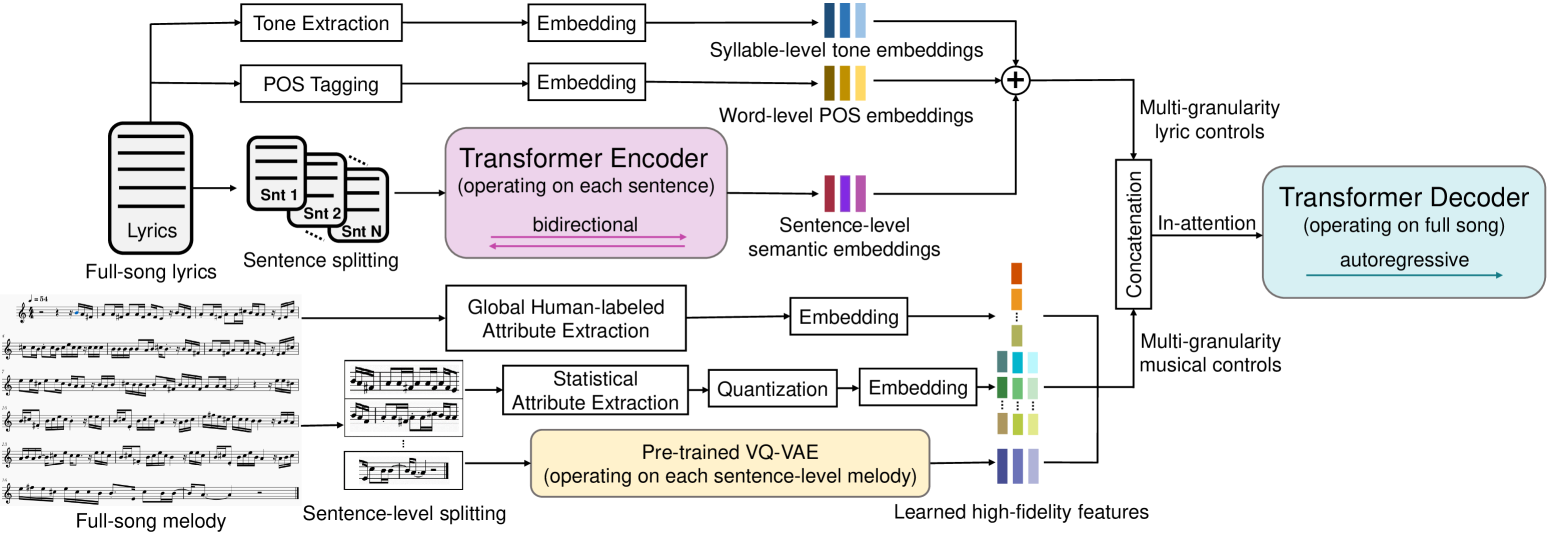
技术框架:CSL-L2M的整体框架包括以下几个主要模块:1) REMI-Aligned音乐表示模块,用于对歌词和旋律进行精确对齐;2) 歌词编码器,用于提取句子级的语义歌词嵌入、词级的词性嵌入和音节级的音调嵌入;3) 音乐特征提取模块,用于提取人工标注的音乐标签、句子级的统计音乐属性以及从预训练的VQ-VAE中提取的学习音乐特征;4) in-attention Transformer解码器,用于根据上述歌词和音乐条件生成完整歌曲的旋律。
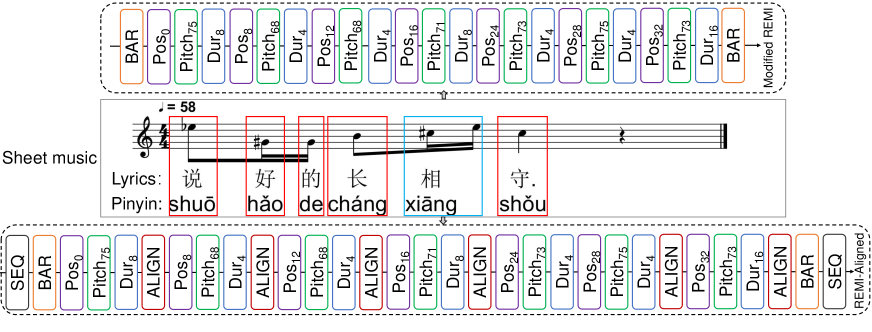
关键创新:论文的关键创新点在于:1) 提出了REMI-Aligned音乐表示方法,能够精确地对齐歌词和旋律;2) 引入了细粒度的歌词和音乐控制,包括音节级、句子级和歌曲级的多种特征,增强了模型的可控性;3) 使用in-attention Transformer解码器,能够更好地利用上下文信息,生成结构更合理的旋律。与现有方法相比,CSL-L2M能够更有效地学习歌词和旋律之间的关系,并生成更高质量、更可控的旋律。
关键设计:REMI-Aligned音乐表示方法通过在REMI表示的基础上,添加音节和句子级别的对齐信息,使得模型能够更准确地学习歌词和旋律之间的对应关系。歌词编码器采用句子级的Transformer编码器,以提取更丰富的语义信息。音乐特征提取模块利用预训练的VQ-VAE提取高保真度的音乐特征。in-attention Transformer解码器采用多头注意力机制,能够更好地捕捉长距离依赖关系。损失函数包括旋律生成的交叉熵损失和对齐损失,以保证生成旋律的准确性和对齐性。
🖼️ 关键图片
📊 实验亮点
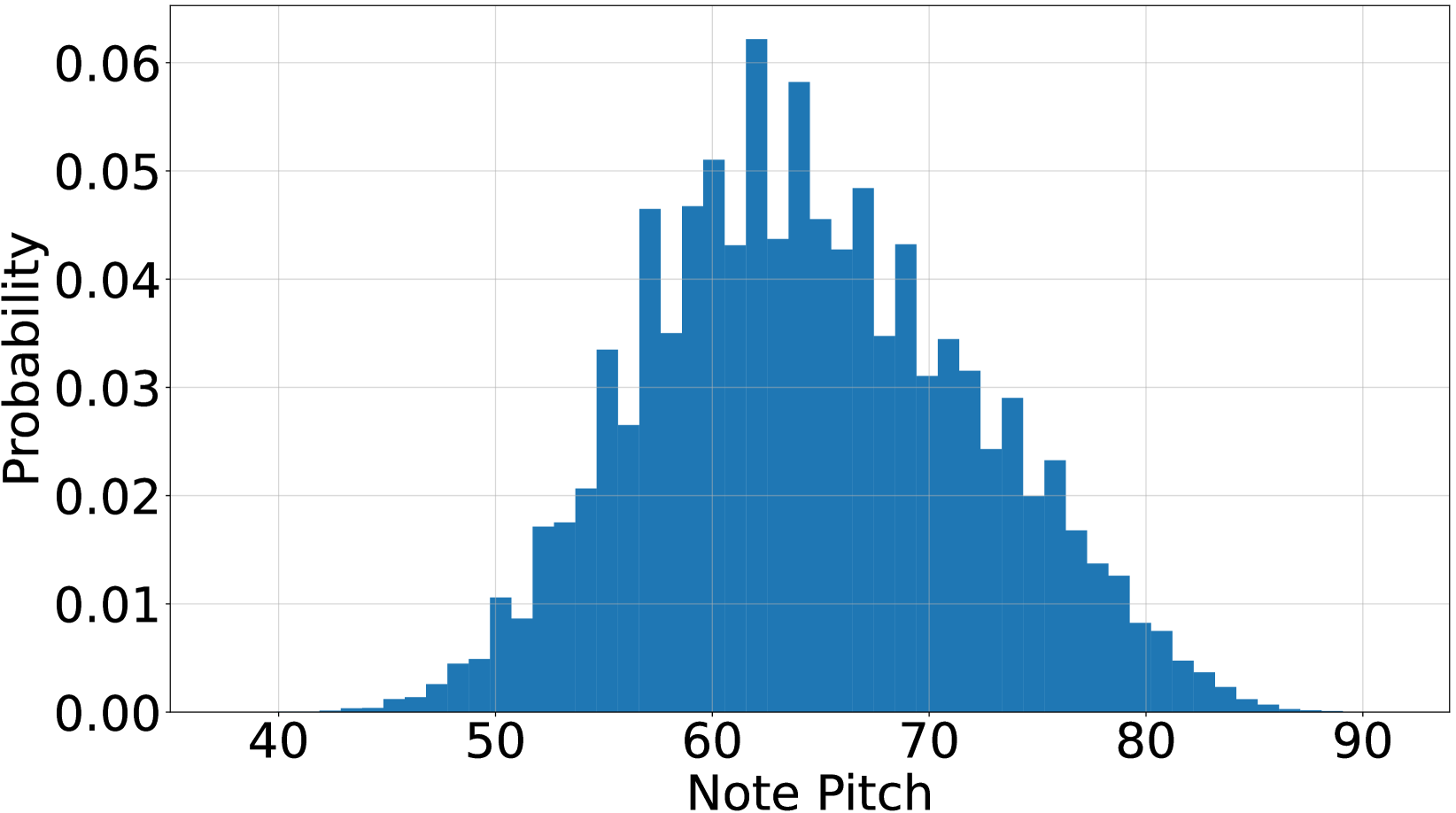
实验结果表明,CSL-L2M在旋律质量、可控性和结构性方面均优于现有方法。具体来说,CSL-L2M在客观指标如音高准确率、节奏准确率等方面取得了显著提升,并且在主观评价中,用户对CSL-L2M生成的旋律的满意度更高。与基线模型相比,CSL-L2M能够生成更符合歌词语义、更具音乐性的旋律。
🎯 应用场景
CSL-L2M具有广泛的应用前景,可用于辅助音乐创作、自动生成歌曲、个性化音乐推荐等领域。该技术可以帮助音乐人快速生成旋律,激发创作灵感,降低音乐创作门槛。此外,该技术还可以应用于游戏、广告等领域,自动生成符合特定场景的背景音乐,提升用户体验。未来,该技术有望进一步发展,实现更加智能化的音乐创作和生成。
📄 摘要(原文)
Lyric-to-melody generation is a highly challenging task in the field of AI music generation. Due to the difficulty of learning strict yet weak correlations between lyrics and melodies, previous methods have suffered from weak controllability, low-quality and poorly structured generation. To address these challenges, we propose CSL-L2M, a controllable song-level lyric-to-melody generation method based on an in-attention Transformer decoder with fine-grained lyric and musical controls, which is able to generate full-song melodies matched with the given lyrics and user-specified musical attributes. Specifically, we first introduce REMI-Aligned, a novel music representation that incorporates strict syllable- and sentence-level alignments between lyrics and melodies, facilitating precise alignment modeling. Subsequently, sentence-level semantic lyric embeddings independently extracted from a sentence-wise Transformer encoder are combined with word-level part-of-speech embeddings and syllable-level tone embeddings as fine-grained controls to enhance the controllability of lyrics over melody generation. Then we introduce human-labeled musical tags, sentence-level statistical musical attributes, and learned musical features extracted from a pre-trained VQ-VAE as coarse-grained, fine-grained and high-fidelity controls, respectively, to the generation process, thereby enabling user control over melody generation. Finally, an in-attention Transformer decoder technique is leveraged to exert fine-grained control over the full-song melody generation with the aforementioned lyric and musical conditions. Experimental results demonstrate that our proposed CSL-L2M outperforms the state-of-the-art models, generating melodies with higher quality, better controllability and enhanced structure. Demos and source code are available at https://lichaiustc.github.io/CSL-L2M/.