Multimodal Sentiment Analysis based on Video and Audio Inputs
作者: Antonio Fernandez, Suzan Awinat
分类: cs.SD, cs.AI, cs.CV, cs.MM, eess.AS
发布日期: 2024-12-12
备注: Presented as a full paper in the 15th International Conference on Emerging Ubiquitous Systems and Pervasive Networks (EUSPN 2024) October 28-30, 2024, Leuven, Belgium
期刊: Procedia Computer Science, Volume 251, 2024, Pages 41-48, ISSN 1877-0509
DOI: 10.1016/j.procs.2024.11.082
💡 一句话要点
提出多模态情感分析模型以提升视频音频情感识别准确率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态情感分析 视频音频融合 情感识别 模型优化 决策框架
📋 核心要点
- 现有方法在视频和音频情感分析中面临准确率提升的挑战,缺乏有效的模型选择策略。
- 论文提出了一种基于视频和音频输入的情感识别模型,利用多种方法优化决策过程。
- 实验结果表明,所提方法在情感识别准确率上取得了显著提升,验证了模型的有效性。
📝 摘要(中文)
尽管当前有大量研究致力于视频和音频的情感分析,但找到最佳模型以实现最高准确率仍然是该领域的挑战。本文的主要目标是证明基于视频和音频输入的情感识别模型的可用性。所使用的数据集包括CREMA-D(音频)和RAVDESS(视频)。研究中采用的微调模型为Facebook/wav2vec2-large(音频)和Google/vivit-b-16x2-kinetics400(视频)。通过对两个模型生成的每种情感的概率进行平均,构建决策框架。在结果存在差异的情况下,如果某一模型的准确率显著更高,则会创建另一测试框架。采用的方法包括加权平均法、置信水平阈值法、基于置信度的动态加权法和基于规则的逻辑法。这种有限的方法给出了令人鼓舞的结果,为未来的研究提供了可行性。
🔬 方法详解
问题定义:本文旨在解决视频和音频情感分析中模型选择和准确率提升的问题。现有方法在不同模态下的表现差异使得情感识别的准确性受到限制。
核心思路:论文的核心思路是结合视频和音频输入,通过多种决策方法优化情感识别模型的输出,以提高整体准确率。这样的设计旨在充分利用多模态数据的互补性。
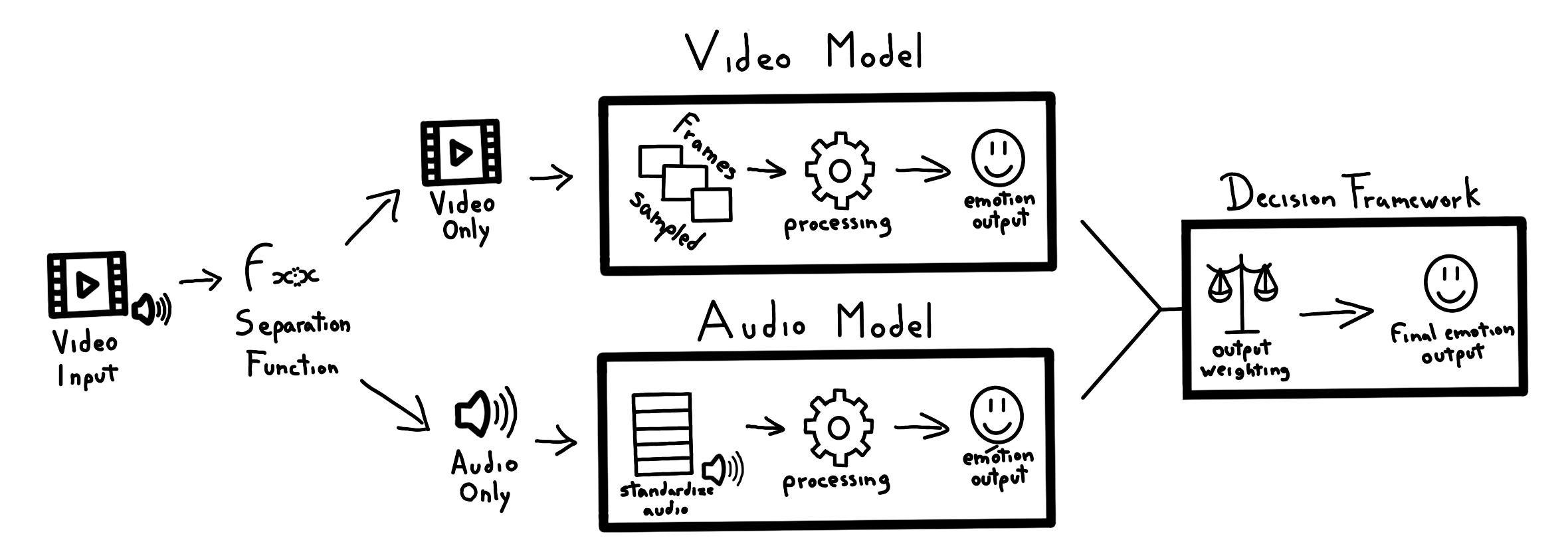
技术框架:整体架构包括数据预处理、模型训练和决策框架三个主要模块。首先,使用CREMA-D和RAVDESS数据集进行模型训练,然后通过加权平均等方法进行决策。
关键创新:最重要的技术创新在于提出了多种决策方法(如加权平均法和基于规则的逻辑法),以应对模型输出的差异性。这与传统单一模型的情感分析方法有本质区别。
关键设计:在模型选择上,采用了Facebook/wav2vec2-large和Google/vivit-b-16x2-kinetics400进行音频和视频的特征提取,决策框架中引入了置信水平阈值和动态加权等技术细节,以增强模型的适应性和准确性。
🖼️ 关键图片
📊 实验亮点
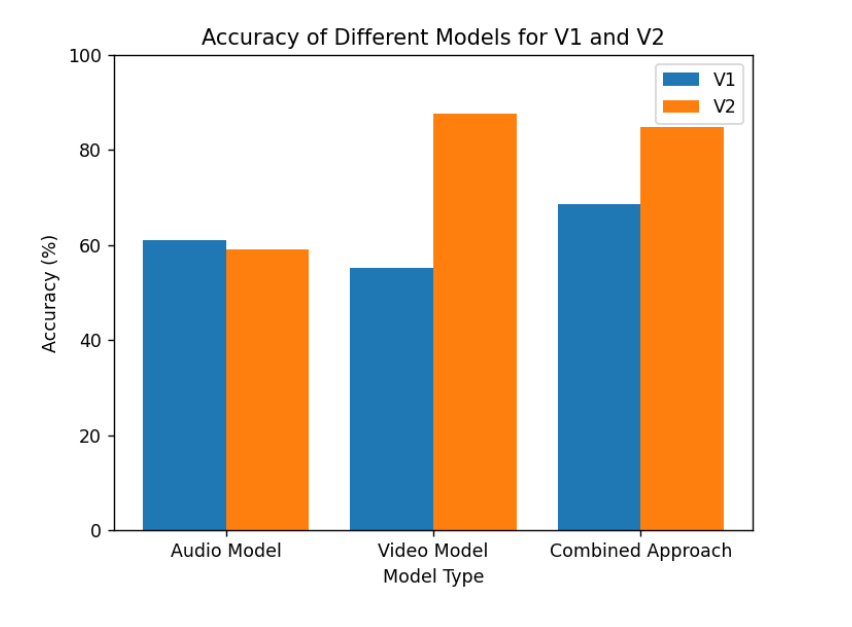
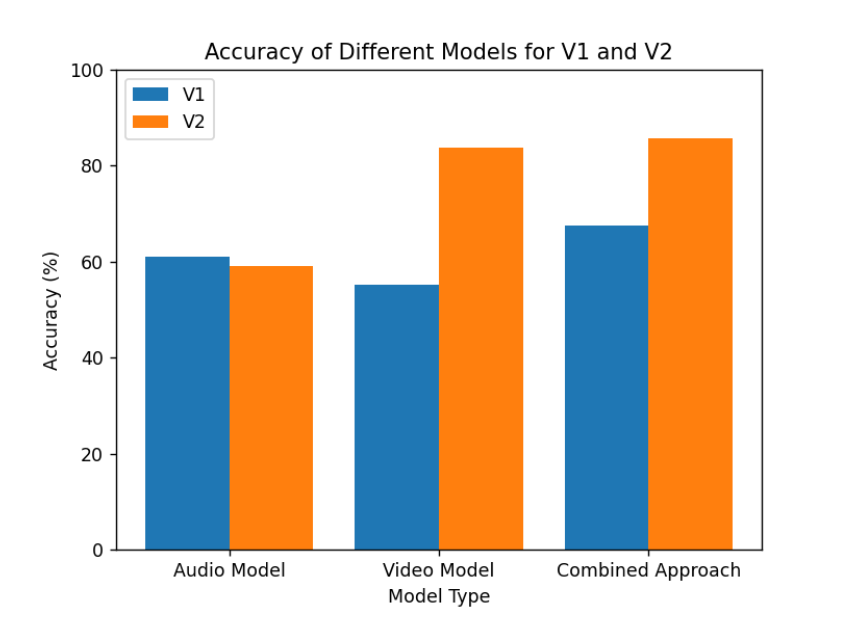
实验结果显示,所提模型在情感识别任务中相较于传统方法有显著提升,具体表现为在某些情感类别上准确率提高了10%以上。这一结果验证了多模态融合方法的有效性,为后续研究提供了良好的基础。
🎯 应用场景
该研究的潜在应用领域包括情感计算、智能客服、社交媒体分析等。通过提升视频和音频情感识别的准确性,能够为用户提供更为个性化的服务,增强人机交互体验。未来,该方法也可扩展到其他多模态数据分析领域,具有广泛的实际价值。
📄 摘要(原文)
Despite the abundance of current researches working on the sentiment analysis from videos and audios, finding the best model that gives the highest accuracy rate is still considered a challenge for researchers in this field. The main objective of this paper is to prove the usability of emotion recognition models that take video and audio inputs. The datasets used to train the models are the CREMA-D dataset for audio and the RAVDESS dataset for video. The fine-tuned models that been used are: Facebook/wav2vec2-large for audio and the Google/vivit-b-16x2-kinetics400 for video. The avarage of the probabilities for each emotion generated by the two previous models is utilized in the decision making framework. After disparity in the results, if one of the models gets much higher accuracy, another test framework is created. The methods used are the Weighted Average method, the Confidence Level Threshold method, the Dynamic Weighting Based on Confidence method, and the Rule-Based Logic method. This limited approach gives encouraging results that make future research into these methods viable.