Enhancing Modality Representation and Alignment for Multimodal Cold-start Active Learning
作者: Meng Shen, Yake Wei, Jianxiong Yin, Deepu Rajan, Di Hu, Simon See
分类: cs.MM, cs.AI, cs.LG
发布日期: 2024-12-12
备注: 11 pages, ACMMM Asia 2024, Oral Presentation
💡 一句话要点
提出MMCSAL方法,解决多模态冷启动主动学习中的模态差距和对齐问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 主动学习 冷启动 模态对齐 模态表示 自监督学习 原型学习
📋 核心要点
- 现有主动学习方法在数据标注初期面临冷启动问题,且很少考虑多模态数据。
- 提出MMCSAL方法,通过引入单模态原型和跨模态对齐正则化来解决模态差距和对齐问题。
- 实验结果表明,MMCSAL在多模态数据选择方面表现出优异的性能。
📝 摘要(中文)
训练多模态模型需要大量标注数据,而主动学习(AL)旨在降低标注成本。大多数AL方法采用warm-start策略,依赖于充足的标注数据来训练一个良好校准的模型,以评估未标注数据的不确定性和多样性。然而,在构建数据集时,初始标注数据通常稀缺,导致冷启动问题。此外,大多数AL方法很少处理多模态数据,突显了该领域的研究空白。本文通过开发一种用于多模态冷启动主动学习(MMCSAL)的两阶段方法来解决这些问题。首先,我们观察到模态差距,即仅使用跨模态配对信息作为自监督信号时,来自不同模态的表示的质心之间存在显著距离。这种模态差距影响数据选择过程,因为我们计算单模态和跨模态距离。为了解决这个问题,我们引入单模态原型来弥合模态差距。其次,传统的AL方法在忽略模态之间对齐的多模态场景中经常失效。因此,我们建议通过正则化来增强跨模态对齐,从而提高AL中选择的多模态数据对的质量。最后,我们的实验证明了MMCSAL在跨三个多模态数据集上选择多模态数据对的有效性。
🔬 方法详解
问题定义:论文旨在解决多模态冷启动主动学习问题。在数据标注初期,标注数据稀缺,导致模型无法准确评估数据的不确定性和多样性,从而影响主动学习的数据选择。此外,现有主动学习方法很少考虑多模态数据,忽略了模态之间的对齐问题。
核心思路:论文的核心思路是通过弥合模态差距和增强跨模态对齐来提高多模态冷启动主动学习的性能。具体来说,引入单模态原型来缩小不同模态表示之间的距离,并通过正则化来增强跨模态对齐,从而提高选择的多模态数据对的质量。
技术框架:MMCSAL方法包含两个主要阶段:模态表示增强和数据选择。在模态表示增强阶段,首先利用跨模态配对信息进行自监督学习,然后引入单模态原型来弥合模态差距,并通过跨模态对齐正则化来增强模态对齐。在数据选择阶段,基于增强的模态表示,计算数据的不确定性和多样性,并选择最具信息量的数据进行标注。
关键创新:论文的关键创新在于:1) 提出了单模态原型来弥合多模态数据中的模态差距,解决了冷启动阶段模态表示不准确的问题;2) 引入跨模态对齐正则化,增强了模态之间的对齐,提高了多模态数据选择的质量。与现有方法相比,MMCSAL方法更适用于多模态冷启动场景。
关键设计:单模态原型通过计算每个模态中已标注数据的均值来获得。跨模态对齐正则化采用对比学习损失,鼓励来自不同模态的对应数据对的表示尽可能接近。数据选择策略结合了不确定性采样和多样性采样,例如使用信息熵评估不确定性,使用余弦距离评估多样性。具体的损失函数和采样权重等参数需要根据具体数据集进行调整。
🖼️ 关键图片


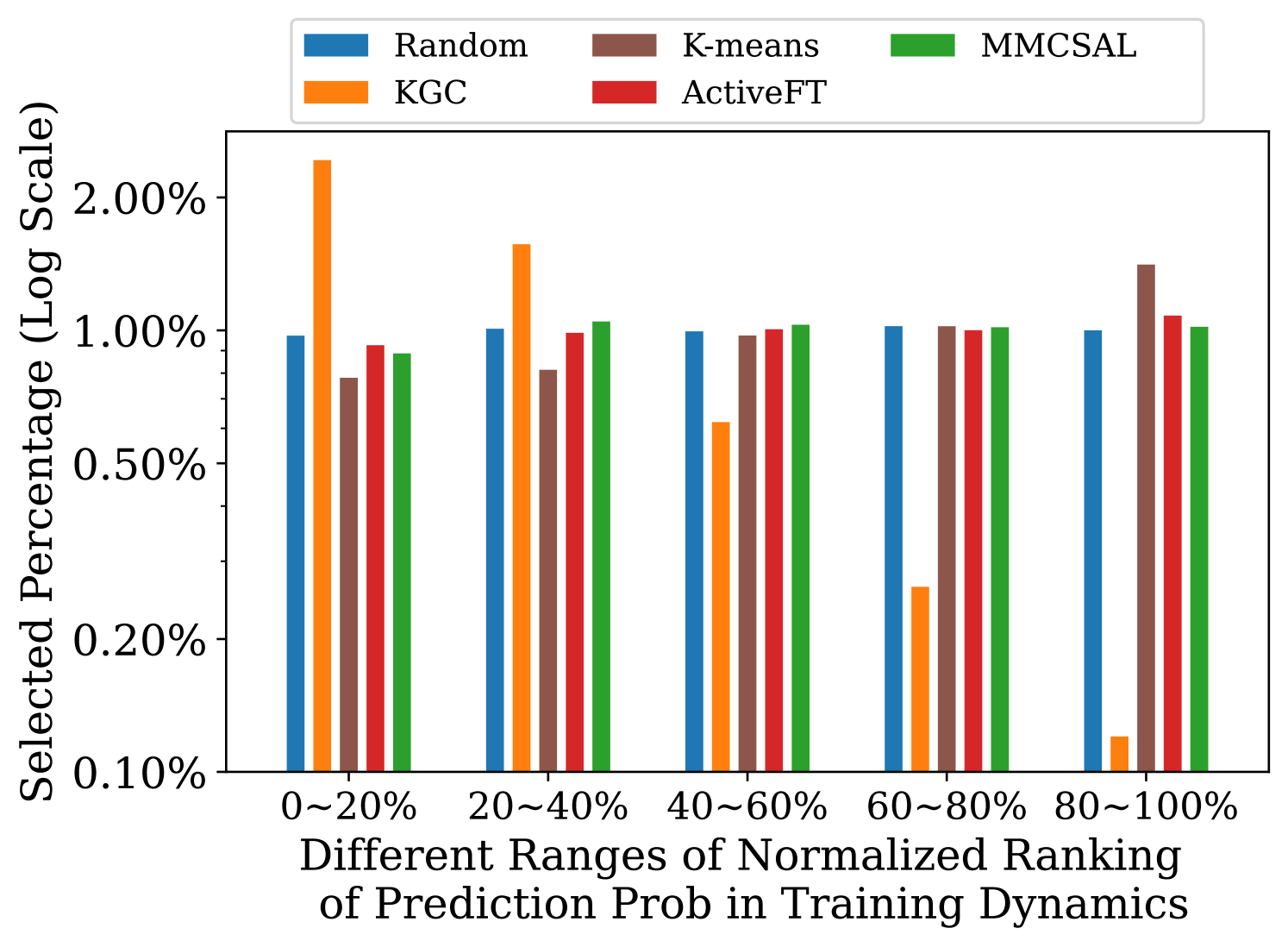
📊 实验亮点
实验结果表明,MMCSAL方法在三个多模态数据集上均取得了显著的性能提升。与传统的warm-start主动学习方法相比,MMCSAL在冷启动阶段能够更快地选择到更有价值的数据,从而加速模型收敛并提高最终性能。具体的性能提升幅度取决于数据集和任务,但总体上优于现有方法。
🎯 应用场景
该研究成果可应用于需要从少量标注数据中学习的多模态任务,例如多模态医学诊断、跨模态信息检索、多模态情感分析等。通过降低标注成本,可以加速多模态模型的开发和部署,提高相关应用的效率和准确性。未来,该方法可以扩展到更多模态和更复杂的任务中。
📄 摘要(原文)
Training multimodal models requires a large amount of labeled data. Active learning (AL) aim to reduce labeling costs. Most AL methods employ warm-start approaches, which rely on sufficient labeled data to train a well-calibrated model that can assess the uncertainty and diversity of unlabeled data. However, when assembling a dataset, labeled data are often scarce initially, leading to a cold-start problem. Additionally, most AL methods seldom address multimodal data, highlighting a research gap in this field. Our research addresses these issues by developing a two-stage method for Multi-Modal Cold-Start Active Learning (MMCSAL). Firstly, we observe the modality gap, a significant distance between the centroids of representations from different modalities, when only using cross-modal pairing information as self-supervision signals. This modality gap affects data selection process, as we calculate both uni-modal and cross-modal distances. To address this, we introduce uni-modal prototypes to bridge the modality gap. Secondly, conventional AL methods often falter in multimodal scenarios where alignment between modalities is overlooked. Therefore, we propose enhancing cross-modal alignment through regularization, thereby improving the quality of selected multimodal data pairs in AL. Finally, our experiments demonstrate MMCSAL's efficacy in selecting multimodal data pairs across three multimodal datasets.