A Multimodal Social Agent
作者: Athina Bikaki, Ioannis A. Kakadiaris
分类: cs.AI, cs.CL
发布日期: 2024-12-11
备注: 9 pages
💡 一句话要点
MuSA:一种基于多模态LLM的社交智能体,用于自动化社交内容分析。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 社交智能体 内容分析 自动化 问答系统 标题生成 内容分类
📋 核心要点
- 现有方法在理解社交动态和执行社交内容分析任务方面存在不足,缺乏有效的自动化工具。
- MuSA通过集成多模态LLM,利用规划、推理等策略,实现对社交内容的自动化分析和理解。
- 实验结果表明,MuSA在问答、标题生成和内容分类等任务中,性能显著优于基线模型。
📝 摘要(中文)
近年来,大型语言模型(LLMs)在常识推理任务中取得了显著进展。这种能力对于理解社会动态、互动和交流至关重要。然而,将计算机与这些社会能力相结合的潜力仍有待探索。本文介绍了一种基于多模态LLM的智能体MuSA,它分析富含文本的社交内容,以解决特定的人工智能内容分析任务,例如问答、视觉问答、标题生成和分类。MuSA采用规划、推理、行动、优化、批评和改进等策略来完成任务。我们的方法表明,MuSA可以自动化和改进社交内容分析,从而帮助各种应用中的决策过程。我们评估了我们的智能体在问答、标题生成和内容分类任务中的能力。MuSA的性能明显优于我们的基线。
🔬 方法详解
问题定义:论文旨在解决社交内容分析的自动化问题。现有方法在处理复杂的社交互动和多模态信息时效率较低,难以满足快速决策的需求。缺乏能够有效理解和推理社交内容的智能体,导致人工分析成本高昂且容易出错。
核心思路:论文的核心思路是利用大型语言模型(LLMs)的强大推理能力,并结合多模态信息,构建一个能够理解、分析和生成社交内容的智能体。通过模仿人类的认知过程,MuSA能够更好地理解社交动态,并做出更明智的决策。
技术框架:MuSA的技术框架包含以下主要模块:1) 多模态输入处理模块,用于接收和处理文本、图像等多种模态的社交内容;2) LLM推理引擎,利用大型语言模型进行常识推理和社会知识推理;3) 任务规划模块,根据任务目标制定行动计划;4) 行动执行模块,执行计划并生成相应的输出,例如答案、标题或类别标签;5) 优化与改进模块,通过批评和反思,不断优化模型的性能。
关键创新:MuSA的关键创新在于将大型语言模型与多模态信息相结合,并引入了规划、推理、行动、优化、批评和改进等策略。这种方法使得MuSA能够更好地理解社交内容的复杂性,并做出更准确的判断。与传统的单模态方法相比,MuSA能够更好地利用多模态信息,提高分析的准确性和效率。
关键设计:论文中没有详细说明关键参数设置、损失函数或网络结构的具体细节。这些细节可能因所使用的大型语言模型和具体任务而异。未来的研究可以进一步探索这些技术细节,以优化MuSA的性能。
🖼️ 关键图片

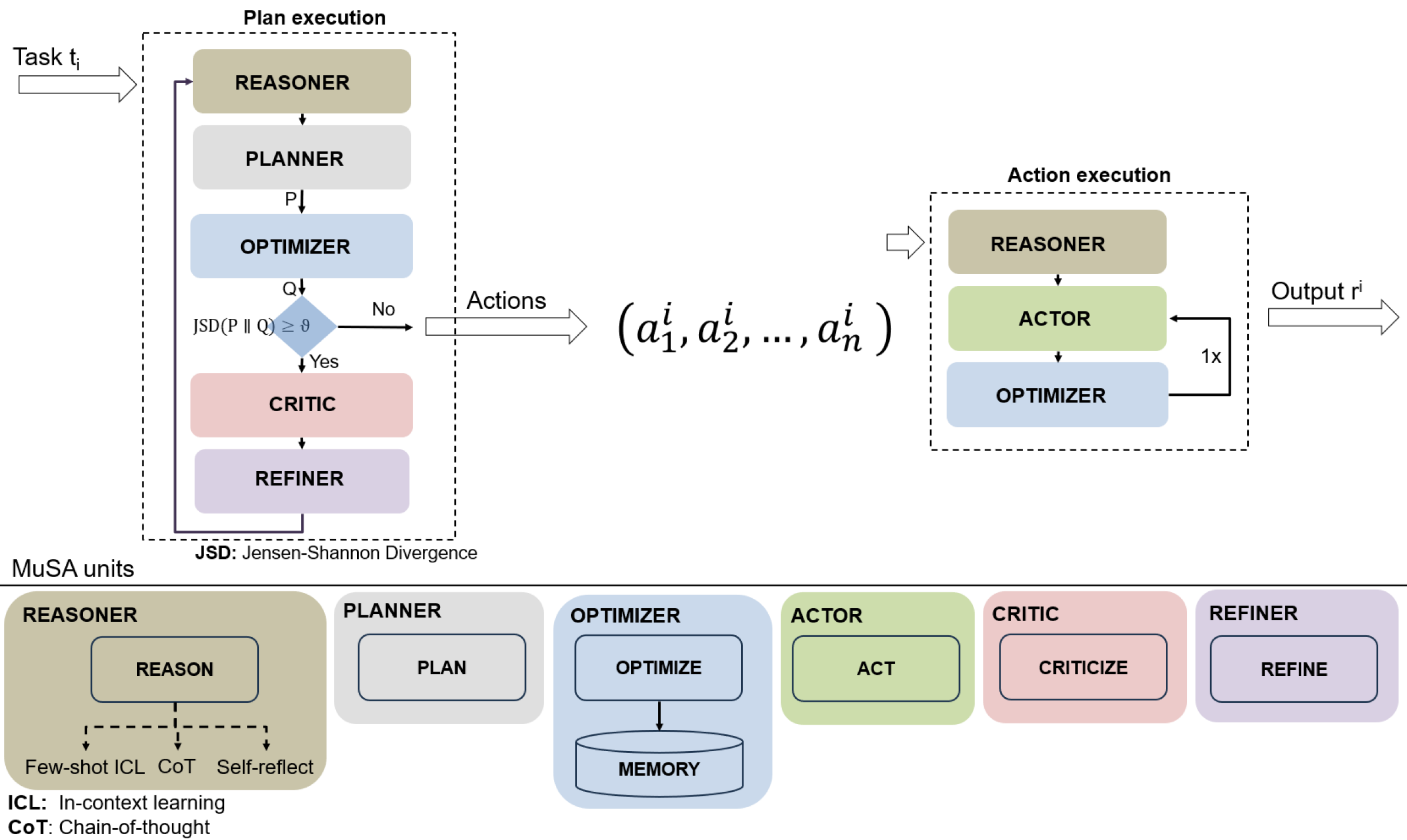

📊 实验亮点
MuSA在问答、标题生成和内容分类等任务中表现出色,显著优于基线模型。具体性能数据未在摘要中给出,但强调了MuSA在自动化和改进社交内容分析方面的潜力。实验结果表明,MuSA能够有效地理解和推理社交内容,并生成高质量的输出。
🎯 应用场景
MuSA具有广泛的应用前景,例如社交媒体内容审核、舆情分析、智能客服、个性化推荐等。它可以帮助企业和组织更好地理解用户需求,及时发现潜在风险,并提供更优质的服务。此外,MuSA还可以应用于教育、医疗等领域,例如辅助教学、心理咨询等。未来,随着技术的不断发展,MuSA有望成为一个强大的社交智能助手。
📄 摘要(原文)
In recent years, large language models (LLMs) have demonstrated remarkable progress in common-sense reasoning tasks. This ability is fundamental to understanding social dynamics, interactions, and communication. However, the potential of integrating computers with these social capabilities is still relatively unexplored. However, the potential of integrating computers with these social capabilities is still relatively unexplored. This paper introduces MuSA, a multimodal LLM-based agent that analyzes text-rich social content tailored to address selected human-centric content analysis tasks, such as question answering, visual question answering, title generation, and categorization. It uses planning, reasoning, acting, optimizing, criticizing, and refining strategies to complete a task. Our approach demonstrates that MuSA can automate and improve social content analysis, helping decision-making processes across various applications. We have evaluated our agent's capabilities in question answering, title generation, and content categorization tasks. MuSA performs substantially better than our baselines.