Training-Free Bayesianization for Low-Rank Adapters of Large Language Models
作者: Haizhou Shi, Yibin Wang, Ligong Han, Huan Zhang, Hao Wang
分类: stat.ML, cs.AI, cs.CL, cs.LG
发布日期: 2024-12-07 (更新: 2025-09-26)
备注: Accepted at NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出免训练贝叶斯化方法TFB,提升低秩适配大语言模型的不确定性估计。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 不确定性估计 贝叶斯方法 低秩适配器 免训练 变分推理 KL散度
📋 核心要点
- 大语言模型的不确定性估计至关重要,但现有贝叶斯方法通常需要复杂的微调或后训练。
- TFB框架通过搜索权重后验方差,将训练好的低秩适配器转化为贝叶斯适配器,无需额外训练。
- 实验表明,TFB在不确定性估计和泛化能力上优于现有方法,且无需复杂训练过程。
📝 摘要(中文)
本文提出了一种免训练贝叶斯化(TFB)框架,旨在解决大语言模型(LLM)响应的不确定性估计问题。现有贝叶斯方法虽然有效,但通常需要复杂的微调或后训练过程。TFB通过在低秩各向同性高斯分布族中搜索最大可接受的权重后验方差,将训练好的低秩适配器高效地转化为贝叶斯适配器,无需额外训练。理论分析表明,该搜索过程等价于KL正则化的变分优化,是变分推理的一种广义形式。实验结果表明,TFB在不确定性估计和泛化能力方面优于现有方法,同时避免了复杂的贝叶斯化训练过程。代码已开源。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)在实际应用中,其输出结果的不确定性难以准确估计的问题。现有的贝叶斯方法,虽然能够提供不确定性估计,但通常需要对模型进行复杂的微调或后训练,计算成本高昂,且可能影响模型的原有性能。因此,如何在不进行额外训练的情况下,有效地估计LLM的不确定性是一个重要的挑战。
核心思路:论文的核心思路是将预训练好的低秩适配器(Low-Rank Adapters)转化为贝叶斯适配器,从而实现对LLM输出不确定性的估计。关键在于找到一种无需额外训练的方法,来确定适配器权重的后验分布。论文通过搜索最大可接受的权重后验方差,在低秩各向同性高斯分布族中寻找最优的后验分布,从而实现贝叶斯化。
技术框架:TFB框架主要包含以下几个阶段:1) 训练一个标准的低秩适配器;2) 定义一个低秩各向同性高斯分布族,作为适配器权重的后验分布;3) 通过搜索算法,找到该分布族中最大可接受的方差,使得后验分布能够较好地反映模型的不确定性;4) 使用得到的贝叶斯适配器进行推理,并利用后验分布来估计输出的不确定性。
关键创新:TFB最关键的创新在于其免训练的贝叶斯化方法。与传统的贝叶斯方法需要复杂的微调或后训练不同,TFB直接利用预训练好的低秩适配器,通过搜索算法来确定适配器权重的后验分布,从而避免了额外的训练成本。此外,论文还从理论上证明了该搜索过程等价于KL正则化的变分优化,为该方法的有效性提供了理论支撑。
关键设计:TFB的关键设计在于如何有效地搜索最大可接受的权重后验方差。论文采用了一种基于梯度下降的搜索算法,通过迭代地调整方差,并根据一定的准则(例如,KL散度)来判断是否达到最大可接受的水平。此外,论文还对低秩适配器的秩(rank)进行了选择,以平衡模型的性能和计算成本。损失函数主要体现在KL散度的计算上,用于衡量后验分布与先验分布之间的差异。
🖼️ 关键图片

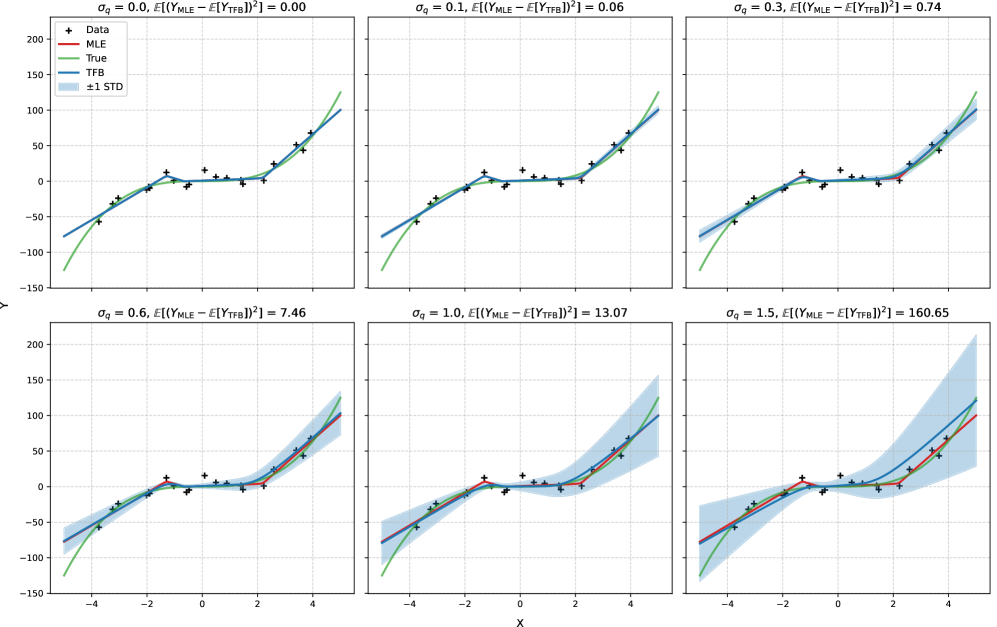
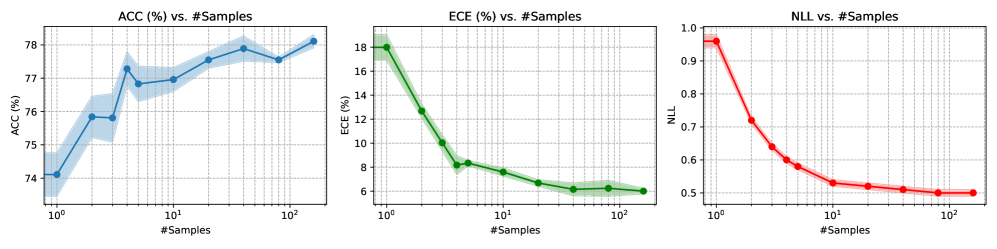
📊 实验亮点
实验结果表明,TFB在多个数据集上取得了优于现有方法的不确定性估计性能。例如,在文本分类任务中,TFB在保持或略微提升模型准确率的同时,显著降低了模型的校准误差(Calibration Error),表明其能够更准确地估计模型的不确定性。此外,TFB还展现出了良好的泛化能力,在未见过的领域或任务上也能提供可靠的不确定性估计。
🎯 应用场景
该研究成果可广泛应用于对LLM输出结果可靠性要求较高的领域,例如医疗诊断、金融风控、自动驾驶等。通过提供不确定性估计,可以帮助用户更好地理解LLM的决策过程,并降低因模型错误带来的风险。未来,该方法有望进一步推广到其他类型的模型和任务中,提升人工智能系统的整体可靠性。
📄 摘要(原文)
Estimating the uncertainty of responses from Large Language Models (LLMs) remains a critical challenge. While recent Bayesian methods have demonstrated effectiveness in quantifying uncertainty through low-rank weight updates, they typically require complex fine-tuning or post-training procedures. In this paper, we propose Training-Free Bayesianization (TFB), a simple yet theoretically grounded framework that efficiently transforms trained low-rank adapters into Bayesian ones without additional training. TFB systematically searches for the maximally acceptable level of variance in the weight posterior, constrained within a family of low-rank isotropic Gaussian distributions. Our theoretical analysis shows that under mild conditions, this search process is equivalent to KL-regularized variational optimization, a generalized form of variational inference. Through comprehensive experiments, we show that TFB achieves superior uncertainty estimation and generalization compared to existing methods while eliminating the need for complex Bayesianization training procedures. Code will be available at https://github.com/Wang-ML-Lab/bayesian-peft.