Towards Learning to Reason: Comparing LLMs with Neuro-Symbolic on Arithmetic Relations in Abstract Reasoning
作者: Michael Hersche, Giacomo Camposampiero, Roger Wattenhofer, Abu Sebastian, Abbas Rahimi
分类: cs.AI, cs.LG, cs.SC
发布日期: 2024-12-07
🔗 代码/项目: GITHUB
💡 一句话要点
对比LLM与神经符号方法在抽象推理中算术关系的学习能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 抽象推理 神经符号方法 大型语言模型 算术推理 向量符号架构 Raven渐进矩阵 分布式表示
📋 核心要点
- 大型语言模型在抽象推理中理解和执行算术规则方面存在不足,尤其是在处理复杂或动态范围大的问题时。
- 论文提出使用神经符号方法ARLC,它利用向量符号架构进行推理,通过分布式向量表示和元素操作来模拟算术运算。
- 实验表明,ARLC在I-RAVEN数据集上表现优于LLM,尤其是在处理更大矩阵和更大动态范围的算术推理问题时。
📝 摘要(中文)
本研究对比了大型语言模型(LLMs)和神经符号方法在解决Raven渐进矩阵(RPM)问题上的表现,RPM是一种视觉抽象推理测试,涉及对诸如递进或算术加法等数学规则的理解。通过直接将视觉属性作为文本提示提供(假设存在一个完美的视觉感知模块),我们可以单独衡量模型的抽象推理能力。尽管提供了来自完美视觉感知的组合结构化表示和先进的提示技术,GPT-4和Llama-3 70B都无法在I-RAVEN数据集的中心星座上实现完美的准确率。我们的分析表明,根本原因在于LLM在理解和执行算术规则方面的弱点。作为一种潜在的补救措施,我们分析了具有上下文感知能力的Abductive Rule Learner(ARLC),这是一种学习使用向量符号架构(VSA)进行推理的神经符号方法。在这里,概念用分布式向量表示,使得编码向量之间的点积定义了一个相似性核,并且向量上的简单元素操作对编码值执行加法/减法。我们发现ARLC在I-RAVEN的中心星座上实现了几乎完美的准确率,证明了其在算术规则方面的高保真度。为了强调模型的长度泛化能力,我们将RPM测试扩展到更大的矩阵(3x10而不是典型的3x3)和更大的属性值动态范围(从10到1000)。我们发现,LLM解决算术规则的准确率降至10%以下,尤其是在动态范围扩大时,而ARLC由于在适当的分布式表示之上模拟符号计算,因此可以保持较高的准确率。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在抽象推理任务中,特别是涉及算术关系的推理能力不足的问题。现有LLMs在处理Raven渐进矩阵(RPM)等需要理解和执行算术规则的任务时,准确率较低,尤其是在问题规模增大或数值范围扩展时,性能显著下降。
核心思路:论文的核心思路是利用神经符号方法,具体而言是Abductive Rule Learner with Context-awareness (ARLC),结合向量符号架构(VSA)来提升模型在算术推理方面的能力。VSA通过分布式向量表示概念,并使用向量间的操作来模拟符号运算,从而实现更可靠的算术推理。
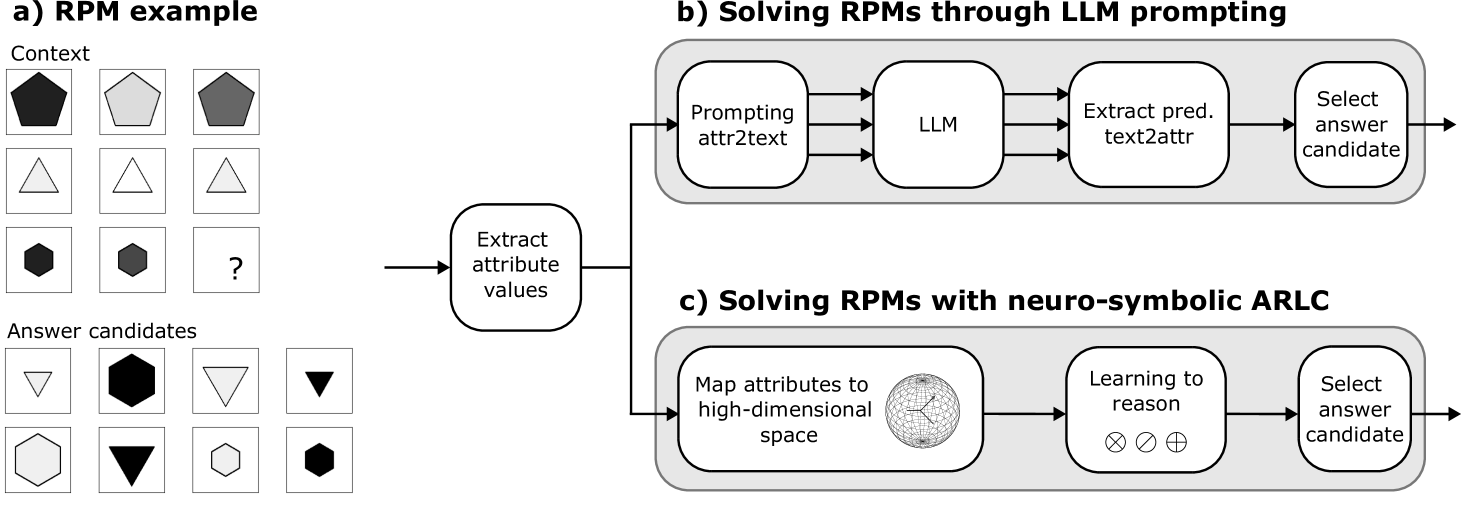
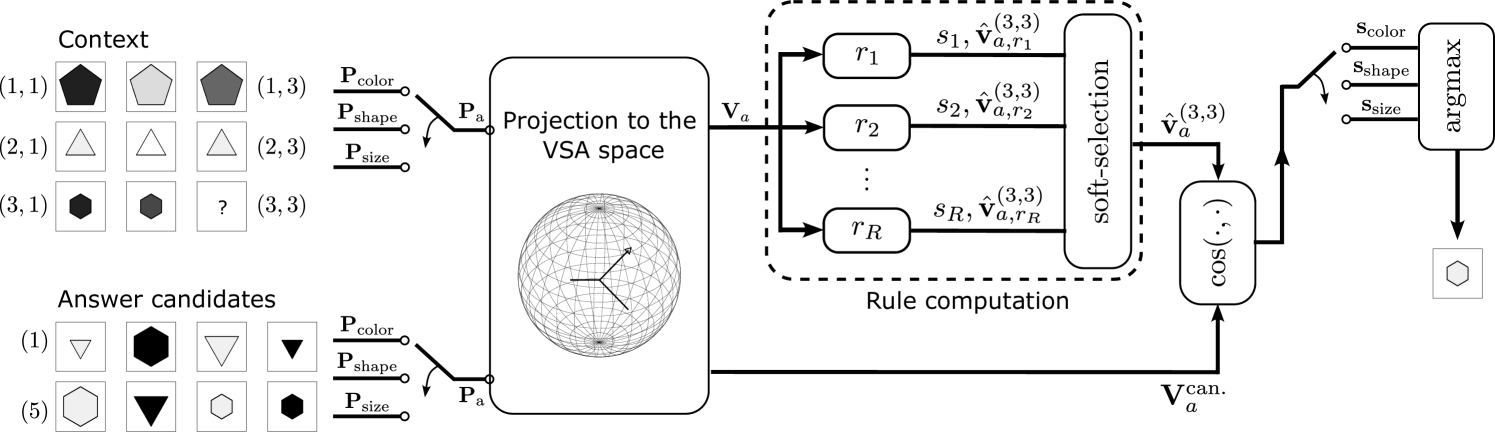
技术框架:ARLC模型使用向量符号架构(VSA)来表示概念和规则。其整体流程包括:1)将视觉属性编码为向量表示;2)使用向量间的点积计算相似度;3)通过向量的元素级操作(如加法、减法)模拟算术运算;4)利用学习到的规则进行推理,选择最合适的答案。该框架的关键在于使用分布式向量表示和符号运算的结合,以实现更强的推理能力。
关键创新:论文的关键创新在于将神经符号方法ARLC应用于解决LLM在算术推理方面的不足。ARLC通过向量符号架构,将概念表示为分布式向量,并使用向量操作模拟符号运算,从而在算术推理方面表现出更高的准确性和泛化能力。与LLM相比,ARLC能够更好地处理动态范围较大和问题规模较大的算术推理任务。
关键设计:ARLC的关键设计包括:1)使用分布式向量表示概念,使得向量间的点积可以衡量相似度;2)使用向量的元素级操作(如加法、减法)来模拟算术运算;3)设计合适的损失函数来训练模型,使其能够学习到正确的算术规则;4)通过上下文感知机制,使模型能够根据不同的上下文选择合适的规则。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ARLC在I-RAVEN数据集的中心星座上实现了几乎完美的准确率,显著优于GPT-4和Llama-3 70B。在扩展的RPM测试中,当矩阵增大到3x10,动态范围扩大到1000时,LLM的准确率降至10%以下,而ARLC仍能保持较高的准确率,验证了其在算术推理方面的优越性和泛化能力。
🎯 应用场景
该研究成果可应用于需要复杂推理和算术运算的智能系统中,例如智能教育、自动化推理、机器人导航等领域。通过提升模型在抽象推理和算术运算方面的能力,可以构建更智能、更可靠的AI系统,解决现实世界中的复杂问题。
📄 摘要(原文)
This work compares large language models (LLMs) and neuro-symbolic approaches in solving Raven's progressive matrices (RPM), a visual abstract reasoning test that involves the understanding of mathematical rules such as progression or arithmetic addition. Providing the visual attributes directly as textual prompts, which assumes an oracle visual perception module, allows us to measure the model's abstract reasoning capability in isolation. Despite providing such compositionally structured representations from the oracle visual perception and advanced prompting techniques, both GPT-4 and Llama-3 70B cannot achieve perfect accuracy on the center constellation of the I-RAVEN dataset. Our analysis reveals that the root cause lies in the LLM's weakness in understanding and executing arithmetic rules. As a potential remedy, we analyze the Abductive Rule Learner with Context-awareness (ARLC), a neuro-symbolic approach that learns to reason with vector-symbolic architectures (VSAs). Here, concepts are represented with distributed vectors s.t. dot products between encoded vectors define a similarity kernel, and simple element-wise operations on the vectors perform addition/subtraction on the encoded values. We find that ARLC achieves almost perfect accuracy on the center constellation of I-RAVEN, demonstrating a high fidelity in arithmetic rules. To stress the length generalization capabilities of the models, we extend the RPM tests to larger matrices (3x10 instead of typical 3x3) and larger dynamic ranges of the attribute values (from 10 up to 1000). We find that the LLM's accuracy of solving arithmetic rules drops to sub-10%, especially as the dynamic range expands, while ARLC can maintain a high accuracy due to emulating symbolic computations on top of properly distributed representations. Our code is available at https://github.com/IBM/raven-large-language-models.