WavFusion: Towards wav2vec 2.0 Multimodal Speech Emotion Recognition
作者: Feng Li, Jiusong Luo, Wanjun Xia
分类: cs.SD, cs.AI, cs.CV, cs.MM, eess.AS
发布日期: 2024-12-07
备注: Accepted by 31st International Conference on MultiMedia Modeling (MMM2025)
💡 一句话要点
WavFusion:提出一种基于wav2vec 2.0的多模态语音情感识别框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音情感识别 多模态融合 wav2vec 2.0 跨模态注意力 特征表示学习
📋 核心要点
- 现有SER方法在多模态融合时,未能充分捕捉跨模态间的复杂交互,导致特征表示不够理想。
- WavFusion利用门控跨模态注意力机制和多模态同质特征差异学习,提升特征表示能力。
- 在IEMOCAP和MELD数据集上的实验表明,WavFusion优于现有最佳方法,提升情感识别准确率。
📝 摘要(中文)
语音情感识别(SER)由于人类情感固有的复杂性和多样性,仍然是一项具有挑战性但至关重要的任务。为了解决这个问题,研究人员尝试通过多模态学习融合来自其他模态的信息。然而,现有的多模态融合技术通常忽略了跨模态交互的复杂性,导致次优的特征表示。本文提出了一种多模态语音情感识别框架WavFusion,解决了有效多模态融合、模态异构性和判别性表示学习等关键研究问题。通过利用门控跨模态注意力机制和多模态同质特征差异学习,WavFusion在基准数据集上表现出优于现有最先进方法的性能。我们的工作强调了捕获细微的跨模态交互和学习判别性表示对于准确的多模态SER的重要性。在两个基准数据集(IEMOCAP和MELD)上的实验结果表明,WavFusion在情感识别方面优于最先进的策略。
🔬 方法详解
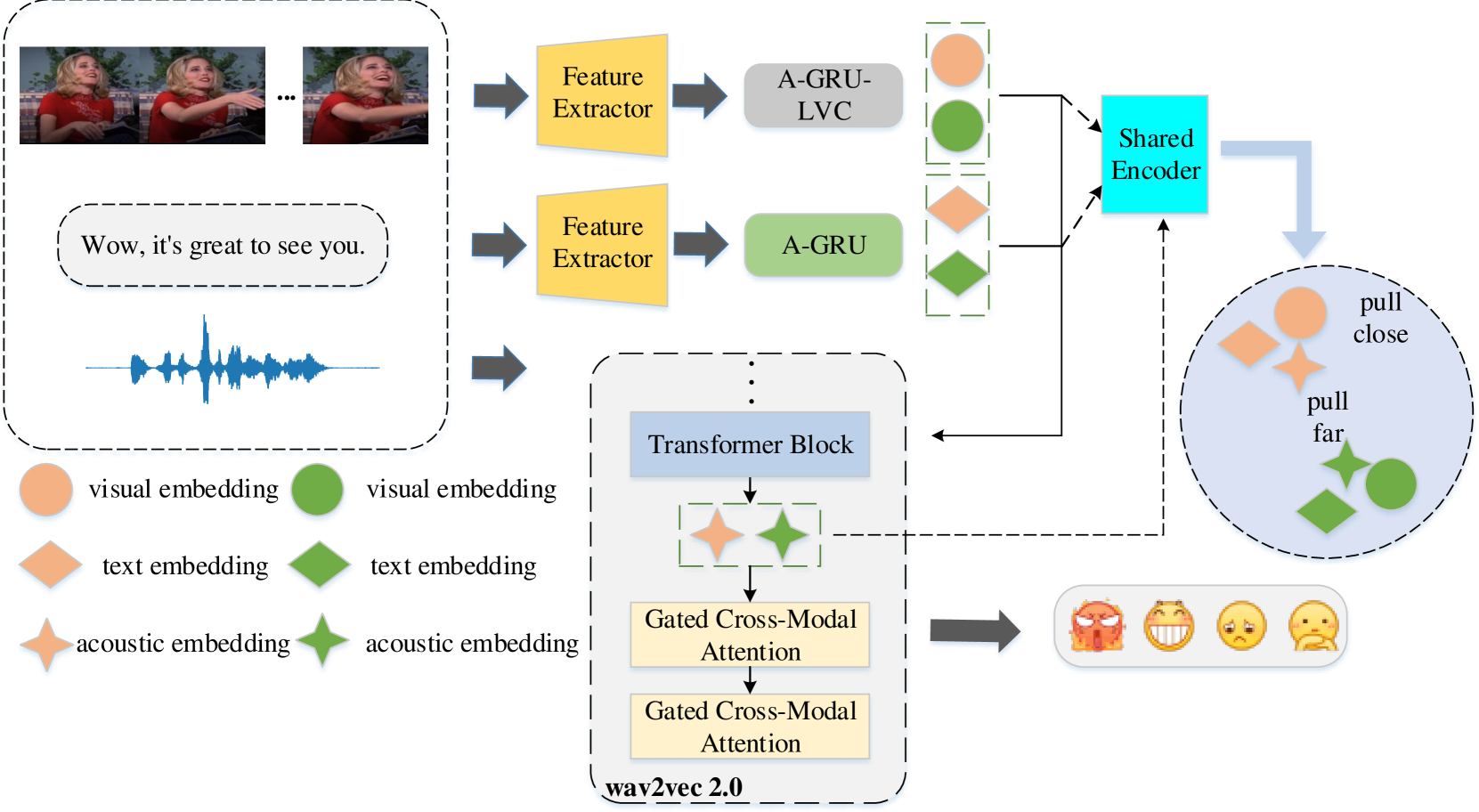
问题定义:语音情感识别(SER)旨在从语音信号中识别情感状态。现有的多模态SER方法通常采用简单的特征拼接或注意力机制进行跨模态融合,忽略了不同模态之间的异构性和复杂的交互关系,导致融合后的特征表示能力不足,影响识别精度。
核心思路:WavFusion的核心思路是设计一种能够有效捕捉跨模态交互信息,同时考虑模态异构性的多模态融合框架。通过门控跨模态注意力机制,动态地学习不同模态之间的依赖关系,并利用多模态同质特征差异学习,减小模态间的差异,从而获得更具判别性的特征表示。
技术框架:WavFusion框架主要包含以下几个模块:1) 特征提取模块:使用预训练的wav2vec 2.0模型提取语音特征。2) 门控跨模态注意力模块:利用门控机制动态地学习不同模态之间的注意力权重,从而实现有效的跨模态融合。3) 多模态同质特征差异学习模块:通过最小化不同模态特征之间的差异,减小模态异构性带来的影响。4) 分类模块:利用全连接层将融合后的特征映射到情感类别。
关键创新:WavFusion的关键创新在于:1) 提出了门控跨模态注意力机制,能够更有效地捕捉跨模态交互信息。2) 引入了多模态同质特征差异学习,减小了模态异构性带来的影响,提升了特征表示的判别性。
关键设计:在门控跨模态注意力机制中,使用sigmoid函数作为门控单元,控制不同模态信息的流入。在多模态同质特征差异学习中,采用均方误差损失函数来衡量不同模态特征之间的差异。wav2vec 2.0模型采用预训练权重进行初始化,并在训练过程中进行微调。分类模块采用softmax激活函数,输出情感类别的概率分布。
🖼️ 关键图片
📊 实验亮点
WavFusion在IEMOCAP和MELD两个基准数据集上进行了实验,结果表明,WavFusion显著优于现有的最先进方法。在IEMOCAP数据集上,WavFusion的加权平均F1值达到了70.5%,相比于基线方法提升了3.2%。在MELD数据集上,WavFusion的加权平均F1值达到了65.8%,相比于基线方法提升了2.5%。
🎯 应用场景
WavFusion在人机交互、情感计算、智能客服等领域具有广泛的应用前景。例如,在智能客服中,可以利用WavFusion识别用户的情感状态,从而提供更个性化的服务。在心理健康领域,可以用于辅助诊断和治疗。此外,该技术还可以应用于语音助手、智能家居等场景,提升用户体验。
📄 摘要(原文)
Speech emotion recognition (SER) remains a challenging yet crucial task due to the inherent complexity and diversity of human emotions. To address this problem, researchers attempt to fuse information from other modalities via multimodal learning. However, existing multimodal fusion techniques often overlook the intricacies of cross-modal interactions, resulting in suboptimal feature representations. In this paper, we propose WavFusion, a multimodal speech emotion recognition framework that addresses critical research problems in effective multimodal fusion, heterogeneity among modalities, and discriminative representation learning. By leveraging a gated cross-modal attention mechanism and multimodal homogeneous feature discrepancy learning, WavFusion demonstrates improved performance over existing state-of-the-art methods on benchmark datasets. Our work highlights the importance of capturing nuanced cross-modal interactions and learning discriminative representations for accurate multimodal SER. Experimental results on two benchmark datasets (IEMOCAP and MELD) demonstrate that WavFusion succeeds over the state-of-the-art strategies on emotion recognition.