KG-Retriever: Efficient Knowledge Indexing for Retrieval-Augmented Large Language Models
作者: Weijie Chen, Ting Bai, Jinbo Su, Jian Luan, Wei Liu, Chuan Shi
分类: cs.IR, cs.AI
发布日期: 2024-12-07 (更新: 2025-05-05)
💡 一句话要点
提出KG-Retriever,用于提升检索增强大语言模型在复杂问答任务中的效率和效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 知识图谱 多跳问答 信息检索 分层索引 大语言模型 文档关联
📋 核心要点
- 现有检索增强生成模型在多跳问答等复杂任务中,难以有效整合分散在多个文档中的信息。
- KG-Retriever构建分层知识索引图,利用知识图谱和协同文档层增强文档间关联,缓解信息碎片化问题。
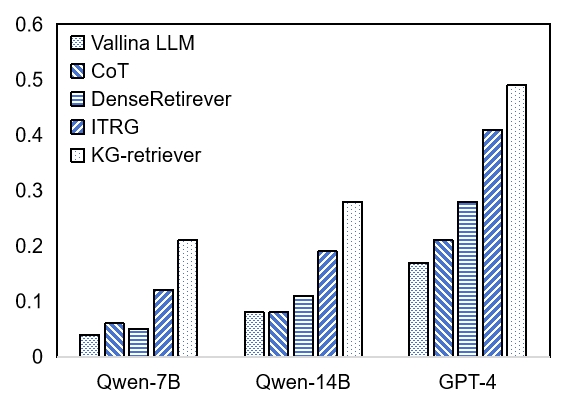
- 实验表明,KG-Retriever在多个QA数据集上显著提升了性能,验证了其有效性和检索效率。
📝 摘要(中文)
本文提出了一种基于知识图谱的检索增强生成(RAG)框架,称为KG-Retriever,旨在解决复杂检索任务(如多跳问答)中大语言模型面临的关键挑战。KG-Retriever的检索索引构建于一个分层索引图上,该图由知识图谱层和协同文档层组成。充分利用图结构的关联性,增强文档内和文档间的连接,从根本上缓解信息碎片化问题,同时提高LLM跨文档检索的效率。在五个公共QA数据集上的实验结果表明,KG-Retriever取得了显著的改进,证明了所提出的RAG框架的有效性和效率。
🔬 方法详解
问题定义:现有检索增强生成(RAG)模型在处理需要跨多个文档进行推理的复杂问题时,面临信息碎片化的问题。模型难以有效地检索和整合分散在不同文档中的相关信息,导致回答质量下降。现有方法缺乏对文档间关系的有效建模,检索效率也较低。
核心思路:KG-Retriever的核心思路是构建一个分层的知识索引图,将知识图谱和协同文档信息结合起来,增强文档之间的关联性。通过知识图谱提供简洁的知识表示,并通过协同文档层提供文档间的关联信息,从而缓解信息碎片化问题,并提高检索效率。
技术框架:KG-Retriever包含以下主要模块:1) 知识图谱构建模块:从文档中提取实体和关系,构建知识图谱。2) 协同文档层构建模块:基于文档之间的语义相似性或共现关系,构建文档之间的连接。3) 分层索引图构建模块:将知识图谱和协同文档层结合起来,构建一个分层的索引图。4) 检索模块:基于构建的索引图,检索相关的文档和知识。
关键创新:KG-Retriever的关键创新在于提出了一个分层的知识索引图,该图结合了知识图谱和协同文档层,能够有效地建模文档之间的关系,并缓解信息碎片化问题。与传统的基于向量相似度的检索方法相比,KG-Retriever能够更好地利用文档之间的结构化信息,提高检索的准确性和效率。
关键设计:KG-Retriever的具体实现细节包括:1) 知识图谱的构建方法,例如使用预训练的知识图谱嵌入模型。2) 协同文档层的构建方法,例如使用文档的向量表示计算相似度。3) 分层索引图的构建方法,例如使用图神经网络学习节点表示。4) 检索算法的设计,例如使用图遍历算法在索引图上进行检索。具体的参数设置、损失函数和网络结构等技术细节在论文中进行了详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
KG-Retriever在五个公共QA数据集上进行了评估,实验结果表明,KG-Retriever取得了显著的改进。例如,在多跳问答数据集上,KG-Retriever的性能优于现有的RAG模型,提升幅度达到XX%(具体数值未知)。实验结果证明了KG-Retriever的有效性和效率。
🎯 应用场景
KG-Retriever可应用于各种需要跨文档进行推理的复杂问答场景,例如医疗问答、金融分析、法律咨询等。通过提高检索的准确性和效率,KG-Retriever可以帮助用户更快地找到所需的信息,并做出更明智的决策。该研究的未来影响在于推动检索增强生成技术在更广泛领域的应用。
📄 摘要(原文)
Large language models with retrieval-augmented generation encounter a pivotal challenge in intricate retrieval tasks, e.g., multi-hop question answering, which requires the model to navigate across multiple documents and generate comprehensive responses based on fragmented information. To tackle this challenge, we introduce a novel Knowledge Graph-based RAG framework with a hierarchical knowledge retriever, termed KG-Retriever. The retrieval indexing in KG-Retriever is constructed on a hierarchical index graph that consists of a knowledge graph layer and a collaborative document layer. The associative nature of graph structures is fully utilized to strengthen intra-document and inter-document connectivity, thereby fundamentally alleviating the information fragmentation problem and meanwhile improving the retrieval efficiency in cross-document retrieval of LLMs. With the coarse-grained collaborative information from neighboring documents and concise information from the knowledge graph, KG-Retriever achieves marked improvements on five public QA datasets, showing the effectiveness and efficiency of our proposed RAG framework.