Comprehensive Evaluation of Multimodal AI Models in Medical Imaging Diagnosis: From Data Augmentation to Preference-Based Comparison
作者: Cailian Ruan, Chengyue Huang, Yahe Yang
分类: eess.IV, cs.AI, cs.CL, cs.CV
发布日期: 2024-12-07
💡 一句话要点
提出医学影像诊断多模态AI模型评估框架,Llama 3.2-90B表现超越人类诊断。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 医学影像诊断 模型评估 数据增强 大型语言模型 偏好学习 临床应用
📋 核心要点
- 现有医学影像诊断模型缺乏统一的评估标准,难以客观比较不同模型的性能优劣。
- 构建包含数据增强、模型推理和偏好评估的完整流程,实现对多模态医学影像诊断模型的综合评估。
- 实验结果表明,Llama 3.2-90B在诊断准确率上超越人类医生,验证了大型多模态模型在医学诊断领域的潜力。
📝 摘要(中文)
本研究提出了一种用于医学影像诊断中多模态模型评估的框架。该框架包含数据预处理、模型推理和基于偏好的评估流程,通过受控的数据增强将初始的500个临床病例扩展到3000个。该方法结合医学图像和临床观察生成评估结果,并使用Claude 3.5 Sonnet作为独立评估器,与医生撰写的诊断结果进行比较。结果表明,不同模型的性能存在差异,其中Llama 3.2-90B在85.27%的病例中优于人类诊断。相比之下,BLIP2和Llava等专业视觉模型分别在41.36%和46.77%的病例中表现出优势。该框架突出了大型多模态模型在某些任务中超越人类诊断的潜力。
🔬 方法详解
问题定义:论文旨在解决医学影像诊断领域中,如何有效评估多模态AI模型性能的问题。现有方法缺乏统一的评估框架,难以客观比较不同模型的优劣,尤其是在结合图像和临床观察等多模态信息时。此外,医学数据稀缺,直接影响模型的训练和评估效果。
核心思路:论文的核心思路是构建一个全面的评估流程,该流程不仅包含数据预处理和模型推理,还引入了基于偏好的评估方法。通过数据增强技术扩充数据集,并使用大型语言模型作为独立的评估器,从而更客观地评估多模态模型在医学影像诊断中的表现。
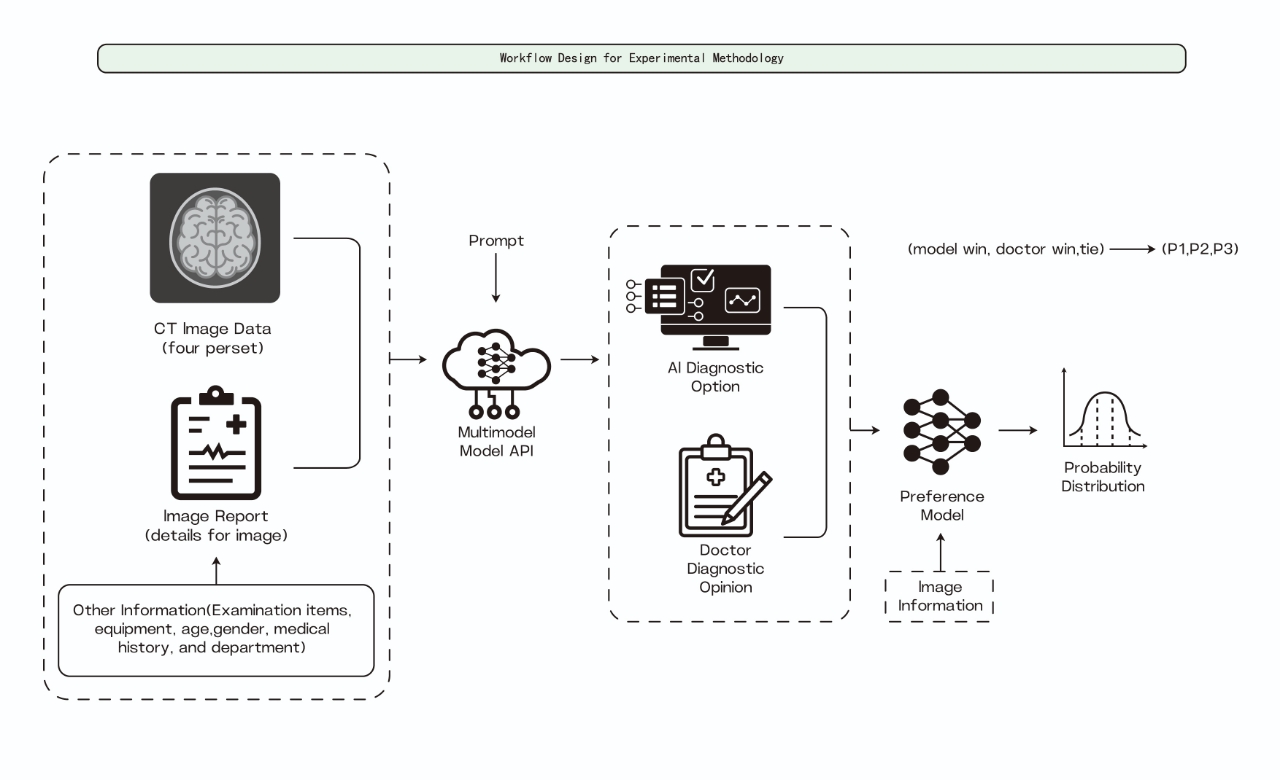
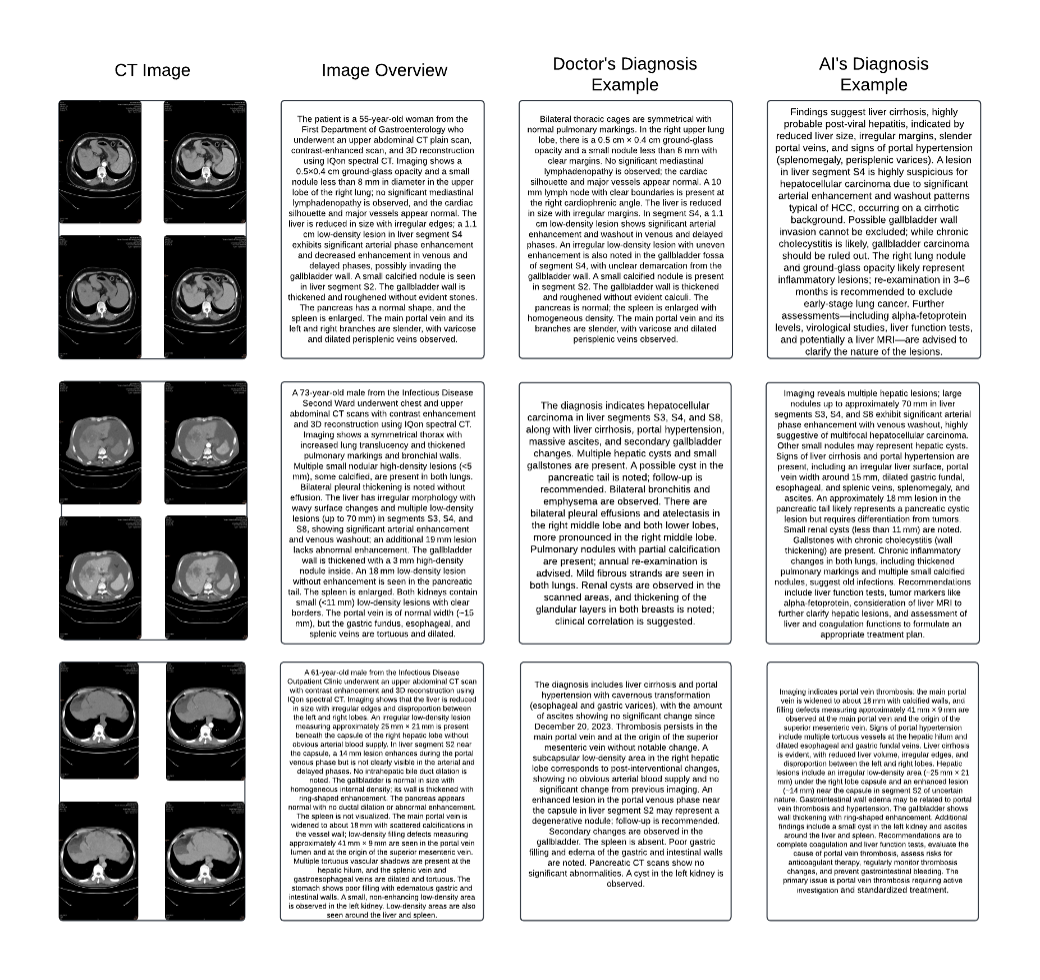
技术框架:该评估框架主要包含三个阶段:1) 数据预处理:对原始医学影像和临床观察数据进行清洗和标准化,并通过受控的数据增强技术,将数据集从500个病例扩展到3000个。2) 模型推理:将预处理后的数据输入到不同的多模态AI模型中,生成诊断评估结果。3) 偏好评估:使用Claude 3.5 Sonnet作为独立的评估器,比较不同模型生成的诊断结果与医生撰写的诊断结果,并根据偏好进行排序和评估。
关键创新:该研究的关键创新在于构建了一个完整的、可复用的多模态医学影像诊断模型评估框架。该框架不仅考虑了模型的准确性,还引入了基于偏好的评估方法,从而更全面地评估模型的性能。此外,使用大型语言模型作为独立的评估器,避免了人为的主观偏差。
关键设计:数据增强策略采用受控的方式,保证增强后的数据质量。评估指标采用基于偏好的比较,而非简单的准确率,从而更贴近实际应用场景。使用Claude 3.5 Sonnet进行独立评估,减少人为干预。具体模型选择包括Llama 3.2-90B,BLIP2和Llava等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Llama 3.2-90B在85.27%的病例中表现优于人类医生的诊断,突显了大型多模态模型在医学影像诊断领域的巨大潜力。相比之下,BLIP2和Llava等专业视觉模型分别在41.36%和46.77%的病例中表现出优势,表明不同模型在特定任务上各有侧重。该研究为选择合适的医学影像诊断模型提供了重要参考。
🎯 应用场景
该研究成果可应用于医学影像辅助诊断系统的开发与评估,帮助医生提高诊断效率和准确性。此外,该评估框架可推广到其他医疗领域,例如病理图像分析、基因组数据分析等,为AI在医疗领域的应用提供更可靠的评估标准。未来,该框架可用于指导多模态医学AI模型的训练和优化。
📄 摘要(原文)
This study introduces an evaluation framework for multimodal models in medical imaging diagnostics. We developed a pipeline incorporating data preprocessing, model inference, and preference-based evaluation, expanding an initial set of 500 clinical cases to 3,000 through controlled augmentation. Our method combined medical images with clinical observations to generate assessments, using Claude 3.5 Sonnet for independent evaluation against physician-authored diagnoses. The results indicated varying performance across models, with Llama 3.2-90B outperforming human diagnoses in 85.27% of cases. In contrast, specialized vision models like BLIP2 and Llava showed preferences in 41.36% and 46.77% of cases, respectively. This framework highlights the potential of large multimodal models to outperform human diagnostics in certain tasks.