Can Large Language Models Serve as Effective Classifiers for Hierarchical Multi-Label Classification of Scientific Documents at Industrial Scale?
作者: Seyed Amin Tabatabaei, Sarah Fancher, Michael Parsons, Arian Askari
分类: cs.AI
发布日期: 2024-12-06
备注: This paper has been accepted at COLING 2025 (Industry Track)
💡 一句话要点
提出结合LLM与稠密检索的零样本分层多标签分类方法,用于工业级科学文档分类。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 分层多标签分类 科学文档分类 零样本学习 稠密检索 动态分类体系 工业规模
📋 核心要点
- 传统科学文档分类方法难以适应动态变化的分类体系,需要大量重新训练和标注数据。
- 论文提出结合LLM的语义理解能力和稠密检索的高效性,实现零样本分层多标签分类。
- 实验表明,该方法在SSRN数据集上显著提升了分类准确性和成本效率,无需重新训练。
📝 摘要(中文)
本文探讨了工业规模下科学文档的分层多标签分类(HMC)任务,其中数十万份文档需要在数千个动态标签中进行分类。科学出版物的快速增长需要可扩展且高效的分类方法,而分类体系的演变(引入新类别、合并现有类别和弃用过时类别)进一步增加了复杂性。传统的机器学习方法每次分类体系更新都需要昂贵的重新训练,由于标注数据收集和模型适配的高昂成本,这些方法变得不切实际。大型语言模型(LLM)在多标签分类等复杂任务中表现出巨大的潜力。然而,将它们应用于大型动态分类体系会带来独特的挑战,因为大量的标签可能会超过LLM的输入限制。在本文中,我们提出了将LLM的优势与稠密检索技术相结合的新方法,以克服这些挑战。我们的方法通过利用零样本HMC进行实时标签分配,避免了重新训练。我们在SSRN(一个跨多个学科的大型预印本存储库)上评估了我们方法的有效性,并证明了分类准确性和成本效率的显著提高。通过为动态分类体系开发定制的评估框架并公开发布我们的代码,这项研究为在工业规模上应用LLM进行文档分类(其中类的数量对应于大型分类体系中节点的数量)提供了重要的见解。
🔬 方法详解
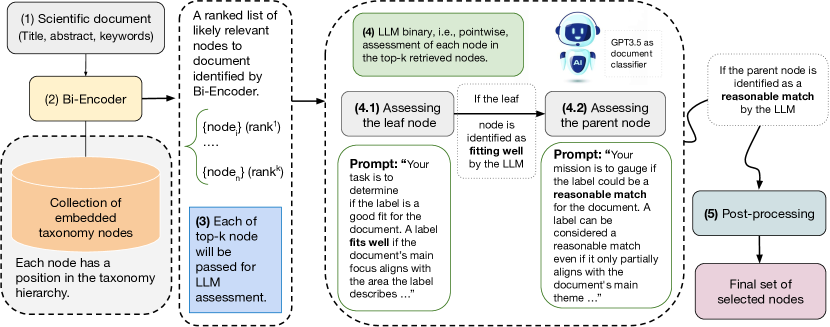
问题定义:论文旨在解决工业规模下科学文档的分层多标签分类问题,特别是在分类体系动态变化的情况下。传统机器学习方法需要针对每次分类体系的更新进行重新训练,这导致了高昂的标注数据收集和模型适配成本。现有方法难以有效处理大规模、动态的标签体系,并且缺乏实时标签分配的能力。
核心思路:论文的核心思路是将大型语言模型(LLM)的强大语义理解能力与稠密检索技术相结合,从而实现零样本的分层多标签分类。通过利用LLM的泛化能力,避免了对每个新标签进行重新训练的需求。稠密检索技术则用于从大量的标签描述中快速找到最相关的标签,从而克服了LLM输入长度的限制。
技术框架:整体框架包含以下几个主要阶段:1) 文档表示:使用预训练的LLM(例如,BERT或其变体)将科学文档编码为高维向量表示。2) 标签表示:将分类体系中的每个标签的描述(例如,标签名称和定义)也编码为向量表示,使用与文档编码相同的LLM。3) 稠密检索:对于给定的文档向量,使用近似最近邻搜索(ANN)在标签向量空间中找到最相关的K个标签。4) LLM分类:将文档向量和检索到的K个标签的描述输入到LLM中,LLM执行零样本多标签分类,预测文档所属的标签。5) 分层约束:利用分类体系的层次结构,对LLM的预测结果进行约束,确保预测的标签在层次结构上是有效的。
关键创新:最重要的技术创新点在于结合了LLM的零样本学习能力和稠密检索的高效性,从而实现了在动态分类体系下的工业级科学文档分类。与传统方法相比,该方法无需重新训练,能够实时适应新的标签,并且具有更好的泛化能力。
关键设计:关键设计包括:1) 使用预训练的LLM进行文档和标签的向量表示,以捕捉语义信息。2) 使用高效的稠密检索算法(例如,FAISS)来加速标签检索过程。3) 设计合适的提示(prompt)工程,将文档和标签描述输入到LLM中,以提高分类准确性。4) 利用分类体系的层次结构,设计分层约束策略,以提高预测结果的合理性。具体的参数设置和损失函数选择取决于所使用的LLM和稠密检索算法。
🖼️ 关键图片

📊 实验亮点
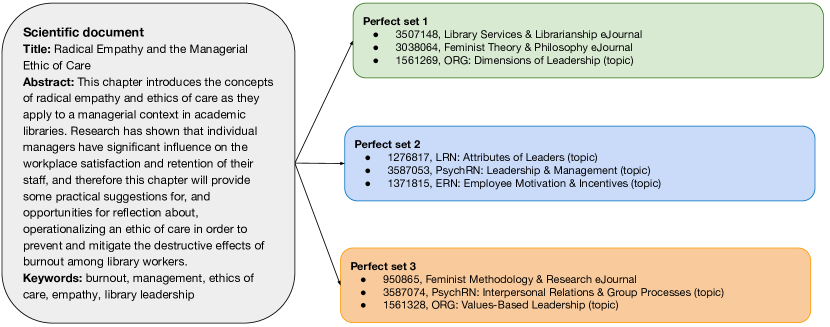
论文在SSRN数据集上进行了实验,结果表明,提出的方法在分类准确性和成本效率方面均优于传统方法。具体而言,该方法在零样本设置下实现了显著的性能提升,无需对每个新标签进行重新训练。实验结果还表明,稠密检索技术能够有效地减少LLM的输入长度,从而使其能够处理大规模的标签体系。
🎯 应用场景
该研究成果可广泛应用于科学文献管理、专利分类、新闻分类、医学文献检索等领域。通过自动化的分层多标签分类,可以显著提高信息检索的效率和准确性,帮助科研人员、决策者和普通用户快速找到所需的信息。未来,该方法有望应用于更广泛的文本分类任务,并与其他技术(如知识图谱)相结合,构建更智能的信息管理系统。
📄 摘要(原文)
We address the task of hierarchical multi-label classification (HMC) of scientific documents at an industrial scale, where hundreds of thousands of documents must be classified across thousands of dynamic labels. The rapid growth of scientific publications necessitates scalable and efficient methods for classification, further complicated by the evolving nature of taxonomies--where new categories are introduced, existing ones are merged, and outdated ones are deprecated. Traditional machine learning approaches, which require costly retraining with each taxonomy update, become impractical due to the high overhead of labelled data collection and model adaptation. Large Language Models (LLMs) have demonstrated great potential in complex tasks such as multi-label classification. However, applying them to large and dynamic taxonomies presents unique challenges as the vast number of labels can exceed LLMs' input limits. In this paper, we present novel methods that combine the strengths of LLMs with dense retrieval techniques to overcome these challenges. Our approach avoids retraining by leveraging zero-shot HMC for real-time label assignment. We evaluate the effectiveness of our methods on SSRN, a large repository of preprints spanning multiple disciplines, and demonstrate significant improvements in both classification accuracy and cost-efficiency. By developing a tailored evaluation framework for dynamic taxonomies and publicly releasing our code, this research provides critical insights into applying LLMs for document classification, where the number of classes corresponds to the number of nodes in a large taxonomy, at an industrial scale.