Flash Communication: Reducing Tensor Parallelization Bottleneck for Fast Large Language Model Inference
作者: Qingyuan Li, Bo Zhang, Liang Ye, Yifan Zhang, Wei Wu, Yerui Sun, Lin Ma, Yuchen Xie
分类: cs.AI
发布日期: 2024-12-06 (更新: 2024-12-11)
💡 一句话要点
Flash Communication:通过低比特压缩加速大语言模型张量并行推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 张量并行 低比特压缩 模型推理 分布式计算
📋 核心要点
- 现有大语言模型推理依赖多维并行,但设备间通信开销大,尤其是在带宽受限的场景。
- Flash Communication通过低比特压缩减少张量并行通信量,从而加速推理过程。
- 实验表明,该方法在几乎不损失模型精度的情况下,显著提升了节点内通信速度和首个token生成速度。
📝 摘要(中文)
大型语言模型不断增长的规模需要分布式解决方案来实现快速推理,这利用了多维并行性,其中计算负载分布在各种加速器(如GPU集群)上。然而,这种方法通常会引入显著的通信开销,尤其是在带宽有限的设备上。本文介绍Flash Communication,一种新颖的低比特压缩技术,旨在缓解推理期间的张量并行通信瓶颈。我们的方法将节点内通信速度提高了3倍以上,并将首个token生成时间缩短了2倍,而几乎没有牺牲模型精度。在各种最新的LLM上进行的大量实验证明了我们方法的有效性。
🔬 方法详解
问题定义:大语言模型(LLM)的推理速度受限于GPU集群间的通信瓶颈,尤其是在张量并行策略下,需要频繁地在不同GPU间传输张量数据。现有方法在带宽受限的设备上通信开销巨大,严重影响推理效率。
核心思路:Flash Communication的核心在于通过低比特压缩技术,减少张量并行过程中需要传输的数据量。通过降低数据精度,在通信带宽不变的情况下,可以传输更多的数据,从而加速整体推理过程。该方法旨在在精度和速度之间找到平衡,尽可能减少精度损失。
技术框架:Flash Communication的具体流程包括:1)在发送端,将高精度张量量化为低比特表示;2)通过通信网络传输压缩后的数据;3)在接收端,将低比特数据反量化为高精度张量。整个过程无缝集成到现有的张量并行框架中,无需修改模型结构。
关键创新:Flash Communication的关键创新在于其低比特压缩策略,该策略针对LLM推理过程中的张量数据特性进行了优化。与传统的通用压缩算法不同,Flash Communication能够更好地权衡压缩率和精度损失,从而在保证模型性能的前提下,显著降低通信开销。
关键设计:Flash Communication采用了动态量化策略,根据张量数据的分布特征自适应地选择量化比特数。此外,还引入了残差量化技术,进一步减少量化误差。具体的量化参数(如缩放因子和零点)通过少量额外通信进行同步,以保证反量化的准确性。损失函数方面,论文可能采用了KL散度或MSE等指标来衡量量化前后张量的差异,并以此指导量化策略的优化(具体损失函数未知)。
🖼️ 关键图片
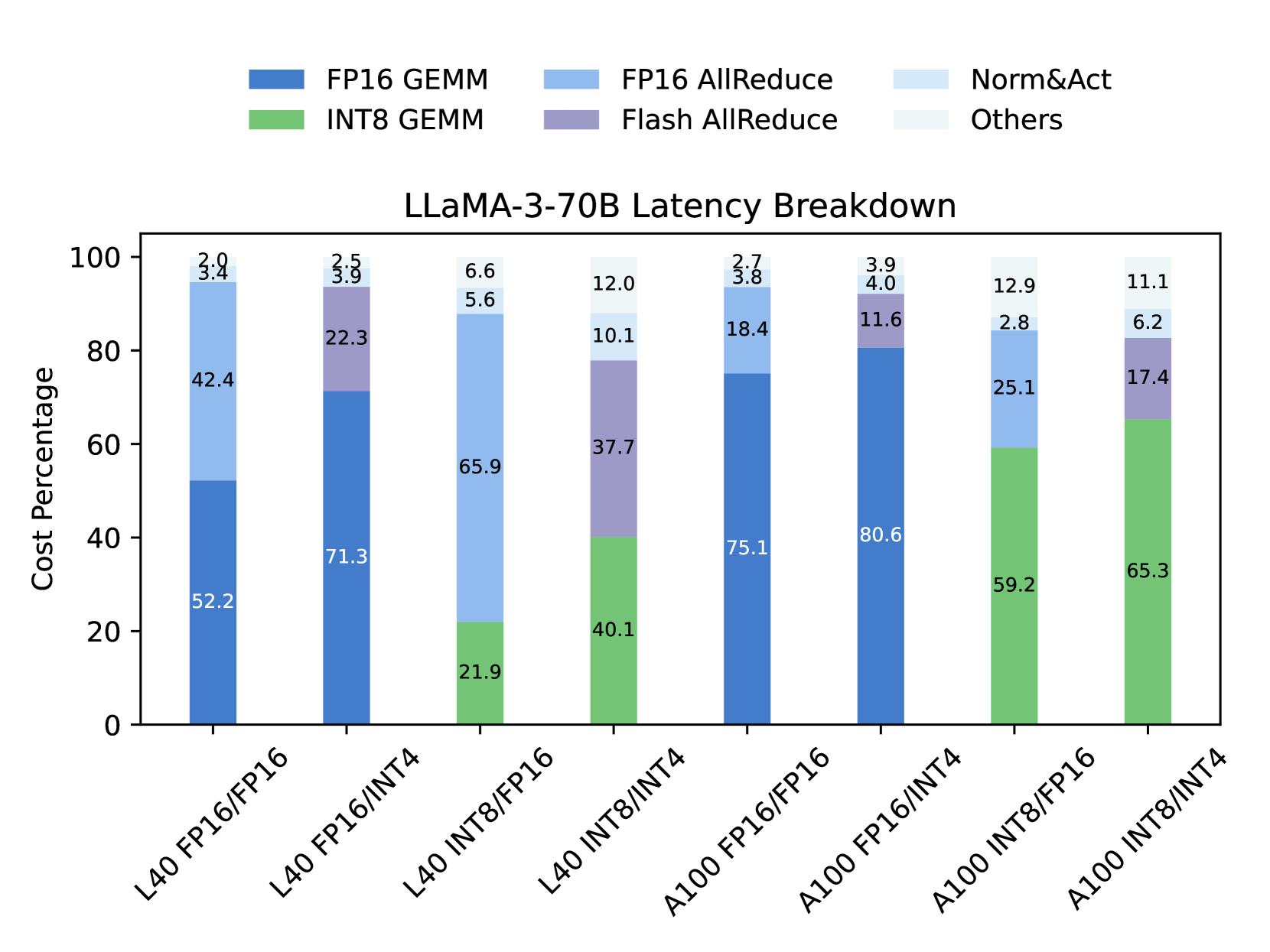
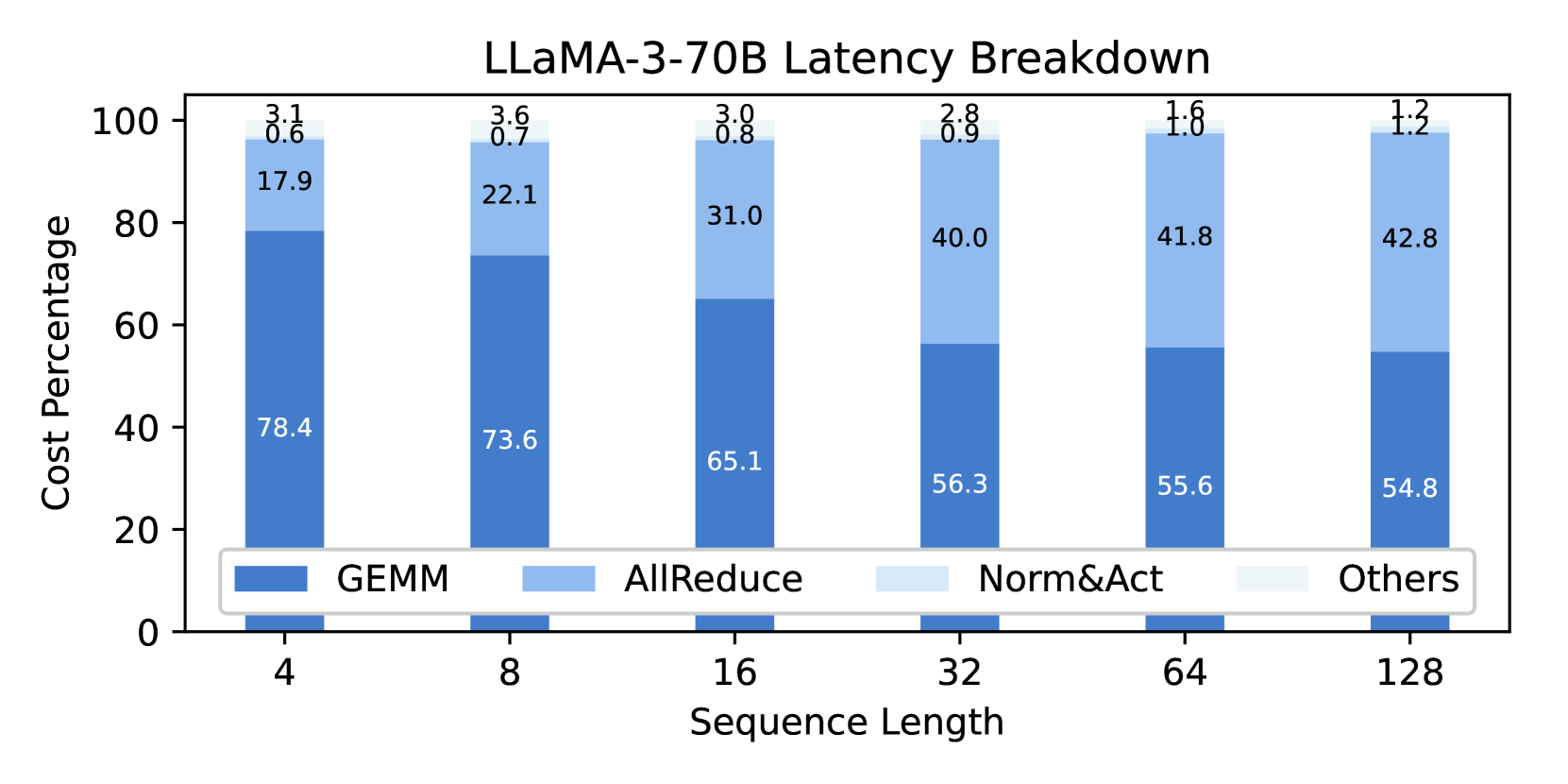
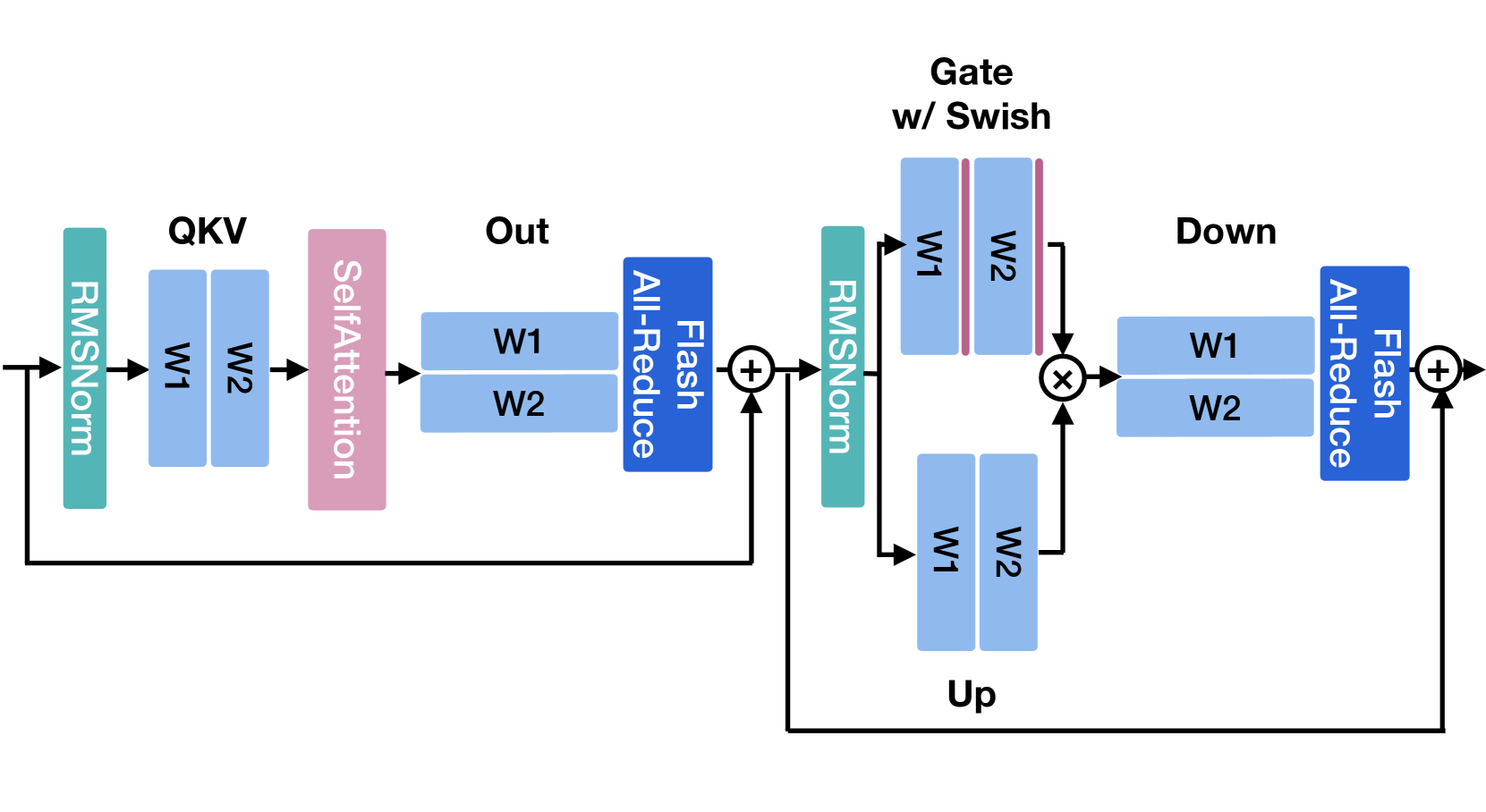
📊 实验亮点
实验结果表明,Flash Communication能够将节点内通信速度提升3倍以上,并将首个token生成时间缩短2倍,同时几乎不损失模型精度。该方法在多种最新的LLM上进行了验证,证明了其有效性和通用性。相较于未采用压缩的基线方法,Flash Communication在推理速度上取得了显著提升。
🎯 应用场景
Flash Communication可广泛应用于需要快速推理的大型语言模型部署场景,例如在线对话机器人、文本生成服务等。该技术能够有效降低推理延迟,提升用户体验,并降低部署成本。未来,该技术有望扩展到其他类型的分布式机器学习任务中,进一步提升计算效率。
📄 摘要(原文)
The ever-increasing sizes of large language models necessitate distributed solutions for fast inference that exploit multi-dimensional parallelism, where computational loads are split across various accelerators such as GPU clusters. However, this approach often introduces significant communication overhead, especially on devices with limited bandwidth. In this paper, we introduce Flash Communication, a novel low-bit compression technique designed to alleviate the tensor-parallelism communication bottleneck during inference. Our method substantially boosts intra-node communication speed by more than 3x and reduces the time-to-first-token by 2x, with nearly no sacrifice in model accuracy. Extensive experiments on various up-to-date LLMs demonstrate the effectiveness of our approach.