Neuro-Symbolic Data Generation for Math Reasoning
作者: Zenan Li, Zhi Zhou, Yuan Yao, Yu-Feng Li, Chun Cao, Fan Yang, Xian Zhang, Xiaoxing Ma
分类: cs.AI
发布日期: 2024-12-06
备注: Published as a conference paper at NeurIPS 2024
💡 一句话要点
提出神经符号数据生成框架,提升LLM在数学推理中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经符号学习 数据生成 数学推理 大型语言模型 马尔可夫链蒙特卡罗 问题变异 符号求解
📋 核心要点
- 现有LLM在数学推理上表现不足,可能源于训练数据质量不高或数量不足。
- 提出神经符号数据生成框架,结合LLM的直觉和符号求解器的精确性,自动生成高质量数学数据集。
- 实验表明,使用生成的数据集微调LLaMA-2和Mistral后,其数学推理能力显著提升。
📝 摘要(中文)
大型语言模型(LLM)在数学推理方面的不足,是源于模型本身的缺陷,还是缺乏高质量的数学数据?为了探究这个问题,本文开发了一种自动生成高质量、有监督数学数据集的方法。该方法通过精心变异现有的数学问题,保证了新生成问题的多样性和有效性。这通过一个神经符号数据生成框架实现,该框架结合了LLM的直观非形式化优势,以及数学求解器的精确符号推理能力,并结合了高度不规则符号空间中的投影马尔可夫链蒙特卡罗采样。实验结果表明,该方法生成的数据质量很高,并且经过生成数据重新对齐后,LLM(特别是LLaMA-2和Mistral)超越了它们最先进的同类模型。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在数学推理能力上的不足。现有的LLM虽然在自然语言处理任务中表现出色,但在需要精确计算和逻辑推理的数学问题上表现不佳。这可能是由于训练数据中高质量数学问题的数量不足,或者现有数据生成方法无法保证生成问题的有效性和多样性。
核心思路:论文的核心思路是利用神经符号方法自动生成高质量的数学问题。具体来说,结合大型语言模型的直觉和非形式化能力,以及符号求解器的精确推理能力,构建一个能够生成多样化且有效的数学问题的框架。通过对现有问题进行变异,并使用符号求解器验证其有效性,从而保证生成数据的质量。
技术框架:该神经符号数据生成框架包含以下几个主要模块:1) 问题变异模块:使用LLM对现有数学问题进行变异,生成新的问题。2) 符号求解模块:使用数学求解器对生成的问题进行求解和验证,确保问题的有效性。3) 采样模块:使用投影马尔可夫链蒙特卡罗(MCMC)采样方法,在高度不规则的符号空间中进行采样,保证生成问题的多样性。整个流程通过迭代进行,不断生成新的高质量数学问题。
关键创新:该方法最重要的创新点在于结合了神经方法和符号方法,利用LLM的生成能力和符号求解器的验证能力,实现高质量数学数据的自动生成。与传统的数据增强方法相比,该方法能够生成更加多样化和有效的数学问题,从而更好地提升LLM的数学推理能力。此外,使用投影MCMC采样方法,能够有效地探索符号空间,保证生成问题的多样性。
关键设计:在问题变异模块中,使用了预训练的LLM(如LLaMA-2或Mistral)作为生成器,并使用特定的prompt工程来引导LLM生成符合要求的数学问题。在符号求解模块中,使用了现有的数学求解器(如Mathematica或Maple)来验证生成问题的有效性。在采样模块中,投影MCMC采样的具体实现细节(如步长、接受率等)需要根据具体的数学问题类型进行调整。
🖼️ 关键图片

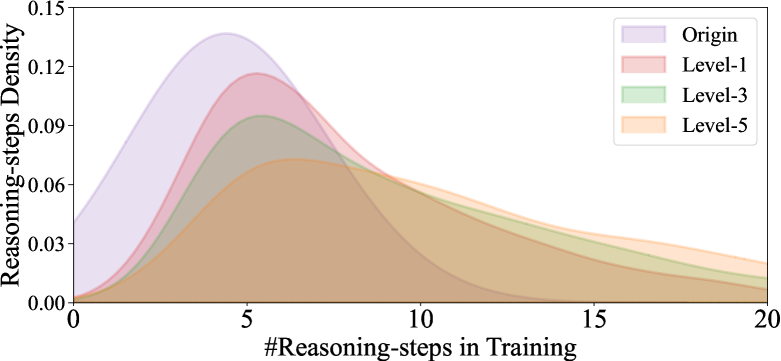

📊 实验亮点
实验结果表明,使用该方法生成的数据集微调LLaMA-2和Mistral后,其在数学推理任务上的性能显著提升,超越了现有的state-of-the-art模型。具体而言,在某些数学数据集上,模型的准确率提升了超过10个百分点。这证明了该方法生成的数据质量很高,并且能够有效地提升LLM的数学推理能力。
🎯 应用场景
该研究成果可应用于提升各种LLM在数学、科学、工程等领域的推理能力。通过生成高质量的训练数据,可以显著提高LLM在解决复杂问题时的准确性和可靠性。此外,该方法还可以用于教育领域,自动生成个性化的数学练习题,帮助学生更好地学习和掌握数学知识。
📄 摘要(原文)
A critical question about Large Language Models (LLMs) is whether their apparent deficiency in mathematical reasoning is inherent, or merely a result of insufficient exposure to high-quality mathematical data. To explore this, we developed an automated method for generating high-quality, supervised mathematical datasets. The method carefully mutates existing math problems, ensuring both diversity and validity of the newly generated problems. This is achieved by a neuro-symbolic data generation framework combining the intuitive informalization strengths of LLMs, and the precise symbolic reasoning of math solvers along with projected Markov chain Monte Carlo sampling in the highly-irregular symbolic space. Empirical experiments demonstrate the high quality of data generated by the proposed method, and that the LLMs, specifically LLaMA-2 and Mistral, when realigned with the generated data, surpass their state-of-the-art counterparts.