Privacy-Preserving Retrieval-Augmented Generation with Differential Privacy
作者: Tatsuki Koga, Ruihan Wu, Zhiyuan Zhang, Kamalika Chaudhuri
分类: cs.CR, cs.AI, cs.CL
发布日期: 2024-12-06 (更新: 2025-11-11)
💡 一句话要点
提出差分隐私检索增强生成算法,在保护隐私的同时生成高质量答案。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 差分隐私 检索增强生成 大型语言模型 隐私保护 敏感数据
📋 核心要点
- 现有RAG方法在处理敏感数据时存在隐私泄露风险,缺乏正式的隐私保证。
- 该论文提出一种差分隐私RAG算法,仅对需要敏感信息的token分配隐私预算,从而在隐私保护和生成质量之间取得平衡。
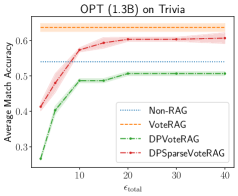
- 实验结果表明,在合理的隐私预算下,该算法在多个数据集和模型上优于非RAG基线。
📝 摘要(中文)
随着大型语言模型(LLMs)的快速发展,人们越来越关注如何将其应用于包含高度敏感数据的领域,而这些数据通常不在LLM的训练数据集中。检索增强生成(RAG)通过直接提供来自外部知识源的相关信息来辅助LLM,因此特别有效。然而,在没有额外隐私保护措施的情况下,RAG的输出可能会泄露外部数据源中的敏感信息。本文探讨了差分隐私(DP)下的RAG,这是一种正式的数据隐私保证。差分隐私RAG的主要挑战是如何在适度的隐私预算内生成长且准确的答案。为此,我们提出了一种算法,该算法仅对需要敏感信息的token花费隐私预算,而对其他token使用非私有的LLM。大量的实验评估表明,在合理的隐私预算ε≈10下,我们的算法在不同的模型和数据集上优于非RAG基线。
🔬 方法详解
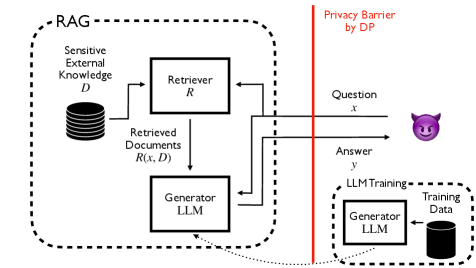
问题定义:论文旨在解决检索增强生成(RAG)在处理包含敏感信息的外部知识源时存在的隐私泄露问题。现有的RAG方法没有提供正式的隐私保证,可能无意中泄露敏感数据,限制了其在医疗、金融等领域的应用。
核心思路:论文的核心思路是选择性地应用差分隐私(DP),只在生成需要访问敏感信息的token时才消耗隐私预算。对于不需要访问敏感信息的token,则可以直接使用非私有的LLM。这种方法旨在最大限度地利用有限的隐私预算,从而在保证隐私的同时,尽可能地提高生成答案的质量和准确性。
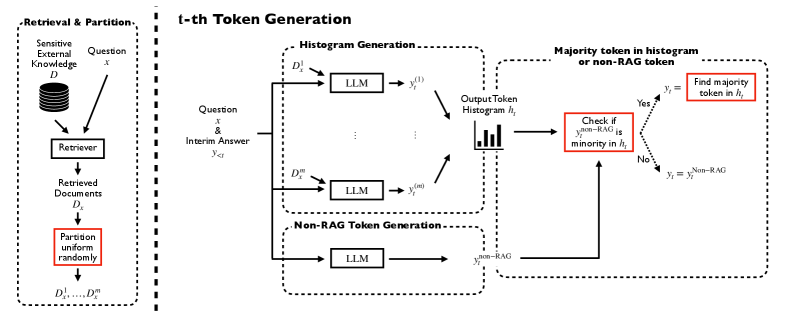
技术框架:该算法主要包含以下几个阶段:1. 检索阶段:从外部知识源检索相关文档。2. 敏感度检测:判断当前token的生成是否需要访问敏感信息。3. 隐私预算分配:如果需要访问敏感信息,则分配相应的隐私预算。4. token生成:根据是否需要访问敏感信息,选择使用差分隐私保护的LLM或非私有的LLM生成token。5. 答案组合:将生成的token组合成最终答案。
关键创新:该论文的关键创新在于提出了选择性差分隐私RAG框架,能够根据token生成的需求动态地分配隐私预算。与传统的全局差分隐私方法相比,该方法能够更有效地利用隐私预算,从而在保证隐私的同时,提高生成答案的质量。
关键设计:论文中一个关键的设计是敏感度检测机制,用于判断当前token的生成是否需要访问敏感信息。具体的实现方式未知,但可以推测可能使用了某种分类器或启发式规则。此外,差分隐私LLM的具体实现方式也未知,可能使用了噪声添加或其他差分隐私技术。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在合理的隐私预算ε≈10下,该算法在不同的模型和数据集上优于非RAG基线。这意味着在保证一定程度的隐私保护的前提下,该算法能够有效地利用外部知识源来提高LLM的生成质量。具体的性能提升幅度未知,但论文强调了其优于非RAG基线。
🎯 应用场景
该研究成果可应用于医疗、金融、法律等涉及敏感数据的领域。例如,在医疗领域,可以利用该算法构建一个能够回答患者健康问题的RAG系统,同时保护患者的隐私。在金融领域,可以用于生成投资建议,同时防止泄露客户的财务信息。该研究有助于推动LLM在隐私敏感领域的应用,具有重要的实际价值和未来影响。
📄 摘要(原文)
With the recent remarkable advancement of large language models (LLMs), there has been a growing interest in utilizing them in the domains with highly sensitive data that lies outside their training data. For this purpose, retrieval-augmented generation (RAG) is particularly effective -- it assists LLMs by directly providing relevant information from the external knowledge sources. However, without extra privacy safeguards, RAG outputs risk leaking sensitive information from the external data source. In this work, we explore RAG under differential privacy (DP), a formal guarantee of data privacy. The main challenge with differentially private RAG is how to generate long accurate answers within a moderate privacy budget. We address this by proposing an algorithm that smartly spends privacy budget only for the tokens that require the sensitive information and uses the non-private LLM for other tokens. Our extensive empirical evaluations reveal that our algorithm outperforms the non-RAG baseline under a reasonable privacy budget of $ε\approx 10$ across different models and datasets.