TANGO: Training-free Embodied AI Agents for Open-world Tasks
作者: Filippo Ziliotto, Tommaso Campari, Luciano Serafini, Lamberto Ballan
分类: cs.AI, cs.RO
发布日期: 2024-12-05
💡 一句话要点
TANGO:无需训练的具身智能体,解决开放世界任务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 大型语言模型 零样本学习 开放世界 程序组合
📋 核心要点
- 现有具身智能体在开放世界任务中泛化能力不足,通常需要大量特定任务的训练数据。
- TANGO利用大型语言模型组合预定义的具身智能体原语,无需额外训练即可完成复杂任务。
- 实验表明,TANGO在开放集目标导航等任务上取得了SOTA结果,展示了强大的零样本泛化能力。
📝 摘要(中文)
本文提出了一种名为TANGO的方法,该方法扩展了大型语言模型(LLMs)在图像领域中组合各种模块以创建能够执行复杂推理任务的程序的能力,旨在将这些能力集成到能够在世界中观察和行动的具身智能体中。具体来说,通过采用一个简单的PointGoal导航模型,并结合一个基于记忆的探索策略作为引导智能体在世界中导航的基础原语,我们展示了单个模型如何在没有额外训练的情况下解决各种任务。我们利用LLM来组合提供的原语以解决特定任务,仅在提示中使用少量的上下文示例。我们在三个关键的具身智能任务上评估了我们的方法:开放集目标导航、多模态终身导航和开放具身问答,在具有挑战性的零样本场景中实现了最先进的结果,而无需任何特定的微调。
🔬 方法详解
问题定义:论文旨在解决具身智能体在开放世界任务中的泛化问题。现有方法通常需要针对特定任务进行大量训练,难以适应未知的环境和目标。这限制了具身智能体在实际应用中的灵活性和可用性。
核心思路:论文的核心思路是利用大型语言模型(LLMs)的强大推理和组合能力,将复杂的任务分解为一系列简单的、预定义的具身智能体原语。通过LLM的规划和调度,智能体可以灵活地组合这些原语来完成各种任务,而无需针对每个任务进行单独训练。
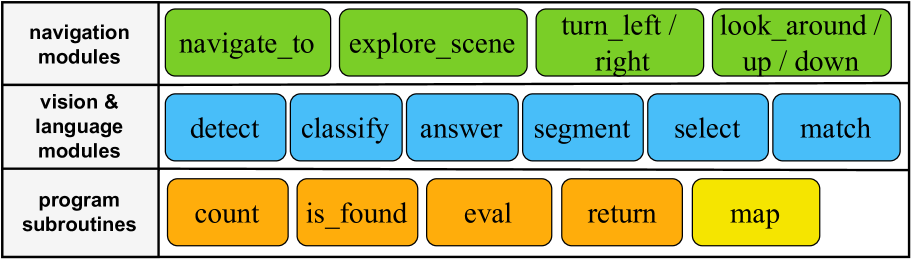
技术框架:TANGO框架主要包含以下几个模块:1) 具身智能体原语:包括PointGoal导航模型和基于记忆的探索策略,用于在环境中移动和探索。2) 大型语言模型(LLM):负责接收任务描述,并根据预定义的具身智能体原语生成执行计划。3) 执行器:负责将LLM生成的计划转化为具体的动作指令,并控制具身智能体执行。整个流程是:接收任务->LLM生成计划->执行器执行计划->智能体行动->重复直到任务完成。
关键创新:TANGO的关键创新在于将LLM的程序组合能力应用于具身智能体,实现了无需训练的开放世界任务解决。与传统的端到端训练方法相比,TANGO避免了对大量训练数据的依赖,并且具有更强的泛化能力和灵活性。它将具身智能体的控制问题转化为LLM的规划问题,从而可以利用LLM的知识和推理能力来解决复杂的任务。
关键设计:TANGO的关键设计包括:1) 具身智能体原语的选择:选择合适的原语对于LLM的规划至关重要。论文选择了PointGoal导航和基于记忆的探索策略,因为它们是具身智能体在环境中移动和探索的基本能力。2) LLM的提示设计:提示的设计对于LLM生成有效的执行计划至关重要。论文使用了少量的上下文示例来引导LLM生成正确的计划。3) 执行器的设计:执行器需要能够将LLM生成的计划转化为具体的动作指令。论文使用了一个简单的执行器,它可以将LLM生成的计划转化为PointGoal导航的目标点和探索策略的参数。
🖼️ 关键图片


📊 实验亮点
TANGO在开放集目标导航、多模态终身导航和开放具身问答三个任务上取得了SOTA结果,无需任何特定微调。例如,在开放集目标导航任务中,TANGO的成功率显著高于现有的零样本方法,展示了其强大的泛化能力。这些结果表明,TANGO是一种有效的、通用的具身智能体控制方法。
🎯 应用场景
TANGO具有广泛的应用前景,例如家庭服务机器人、仓库自动化、灾难救援等。它可以使机器人在未知环境中自主完成各种任务,例如寻找特定物品、清理房间、搬运货物等。此外,TANGO还可以应用于虚拟现实和增强现实领域,为用户提供更加沉浸式的体验。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated excellent capabilities in composing various modules together to create programs that can perform complex reasoning tasks on images. In this paper, we propose TANGO, an approach that extends the program composition via LLMs already observed for images, aiming to integrate those capabilities into embodied agents capable of observing and acting in the world. Specifically, by employing a simple PointGoal Navigation model combined with a memory-based exploration policy as a foundational primitive for guiding an agent through the world, we show how a single model can address diverse tasks without additional training. We task an LLM with composing the provided primitives to solve a specific task, using only a few in-context examples in the prompt. We evaluate our approach on three key Embodied AI tasks: Open-Set ObjectGoal Navigation, Multi-Modal Lifelong Navigation, and Open Embodied Question Answering, achieving state-of-the-art results without any specific fine-tuning in challenging zero-shot scenarios.