Leveraging Large Language Models to Generate Course-specific Semantically Annotated Learning Objects
作者: Dominic Lohr, Marc Berges, Abhishek Chugh, Michael Kohlhase, Dennis Müller
分类: cs.AI
发布日期: 2024-12-05
备注: Accepted at Journal of Computer Assisted Learning (2024)
💡 一句话要点
利用大型语言模型生成课程相关的语义标注学习对象
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自动问题生成 检索增强生成 语义标注 计算机科学教育
📋 核心要点
- 现有的自动问题生成方法在生成上下文相关和教学意义丰富的学习对象方面存在不足。
- 该论文提出利用检索增强生成(RAG)策略,使大型语言模型能够生成更具针对性和上下文关联性的问题。
- 实验结果表明,该方法在生成结构化语义标注方面表现良好,但在关系标注和问题质量方面仍有提升空间。
📝 摘要(中文)
背景:过去几十年,自动问题生成(AQG)的过程和方法经历了显著的转变。生成式自然语言模型领域的最新进展为教育内容的生成开辟了新的潜力。目标:本文探讨了大型语言模型(LLM)在生成计算机科学问题方面的潜力,这些问题经过充分标注,可以自动更新学习者模型,完全位于特定课程的上下文中,并解决认知维度“理解”。方法:与可能使用ChatGPT等基本方法的前期尝试不同,我们的方法涉及更有针对性的策略,例如检索增强生成(RAG),以生成上下文相关且具有教学意义的学习对象。结果与结论:我们的结果表明,生成结构化语义标注效果良好。然而,这种成功并未反映在关系标注中。生成问题的质量通常不符合教育标准,这突出表明,尽管LLM可以为学习材料库做出贡献,但它们目前的性能水平需要大量的人工干预来完善和验证生成的内容。
🔬 方法详解
问题定义:论文旨在解决自动生成计算机科学领域,特定课程相关的、带有语义标注的学习对象的问题。现有方法,例如直接使用ChatGPT,无法保证生成的问题与课程内容紧密相关,并且缺乏足够的语义标注,难以用于自动更新学习者模型。这些问题阻碍了个性化学习和智能教学系统的发展。
核心思路:论文的核心思路是利用检索增强生成(RAG)技术,将大型语言模型与课程相关的知识库相结合。通过检索与问题相关的课程内容,并将其作为上下文输入到大型语言模型中,从而引导模型生成更符合课程要求、更具语义信息的问题。这种方法旨在提高生成问题的相关性、准确性和教学价值。
技术框架:整体框架包含以下几个主要模块:1) 课程知识库构建:收集和整理特定计算机科学课程的教材、讲义、习题等资源,构建课程知识库。2) 问题检索:根据用户需求或课程进度,从知识库中检索与当前问题相关的文档或知识片段。3) 上下文增强:将检索到的知识片段作为上下文信息,与问题描述一起输入到大型语言模型中。4) 问题生成:利用大型语言模型生成问题,并进行结构化和关系语义标注。5) 人工审核与修正:对生成的问题进行人工审核,修正错误或不符合教学标准的问题。
关键创新:该论文的关键创新在于将检索增强生成(RAG)技术应用于课程相关的学习对象生成。与直接使用大型语言模型生成问题相比,RAG方法能够显著提高生成问题的相关性和准确性,并能够生成带有结构化和关系语义标注的问题。这使得生成的问题更易于理解和利用,为自动学习者模型更新和个性化学习提供了基础。
关键设计:论文中没有详细描述关键参数设置、损失函数或网络结构等技术细节。但是,RAG 框架中,检索模块的性能至关重要,可能涉及到向量数据库的选择、相似度计算方法(如余弦相似度)以及检索阈值的设定。此外,大型语言模型的选择和微调策略也会影响生成问题的质量。对于语义标注,需要设计合适的标注体系和标注规则,并训练模型进行自动标注。
🖼️ 关键图片
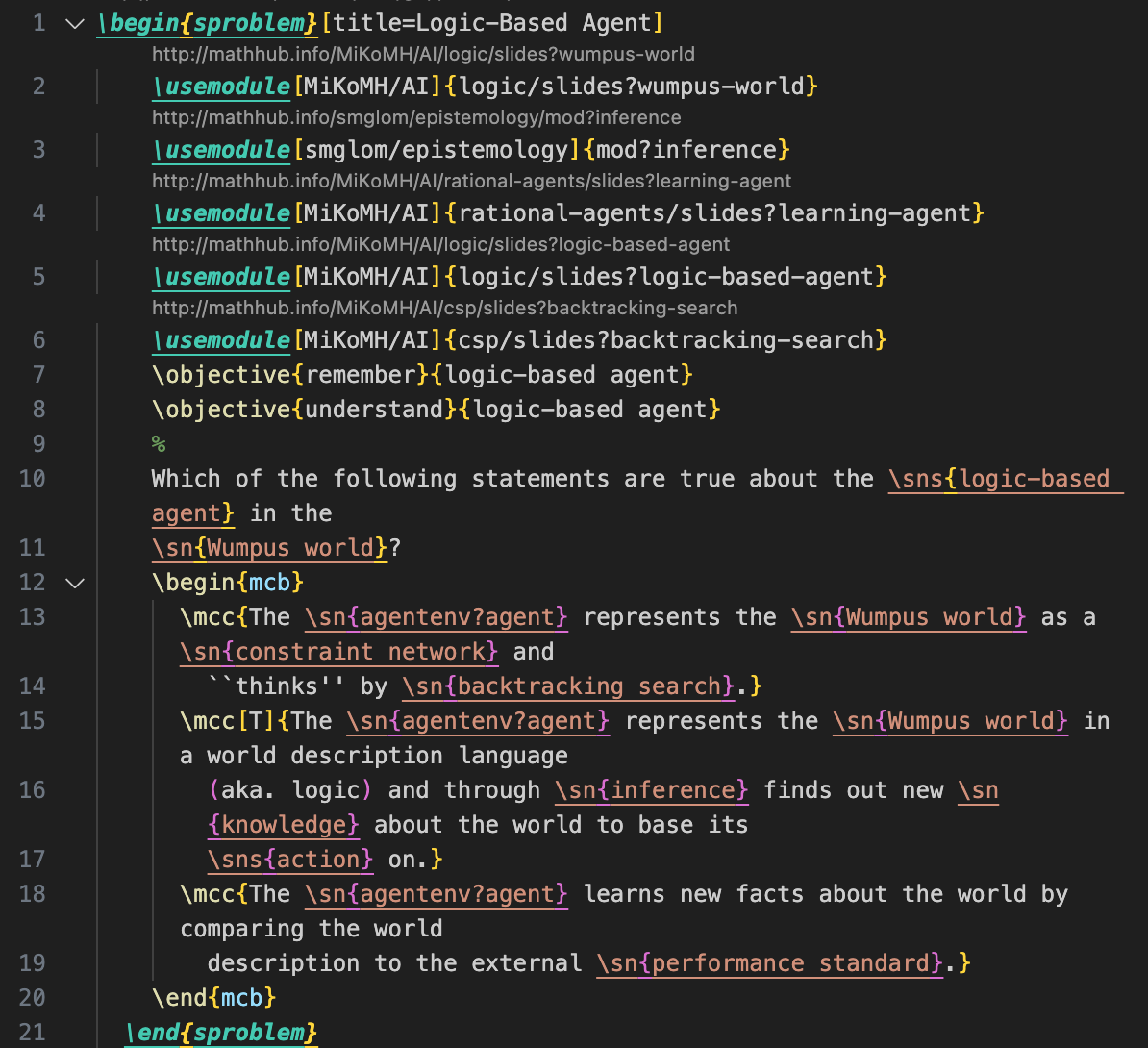
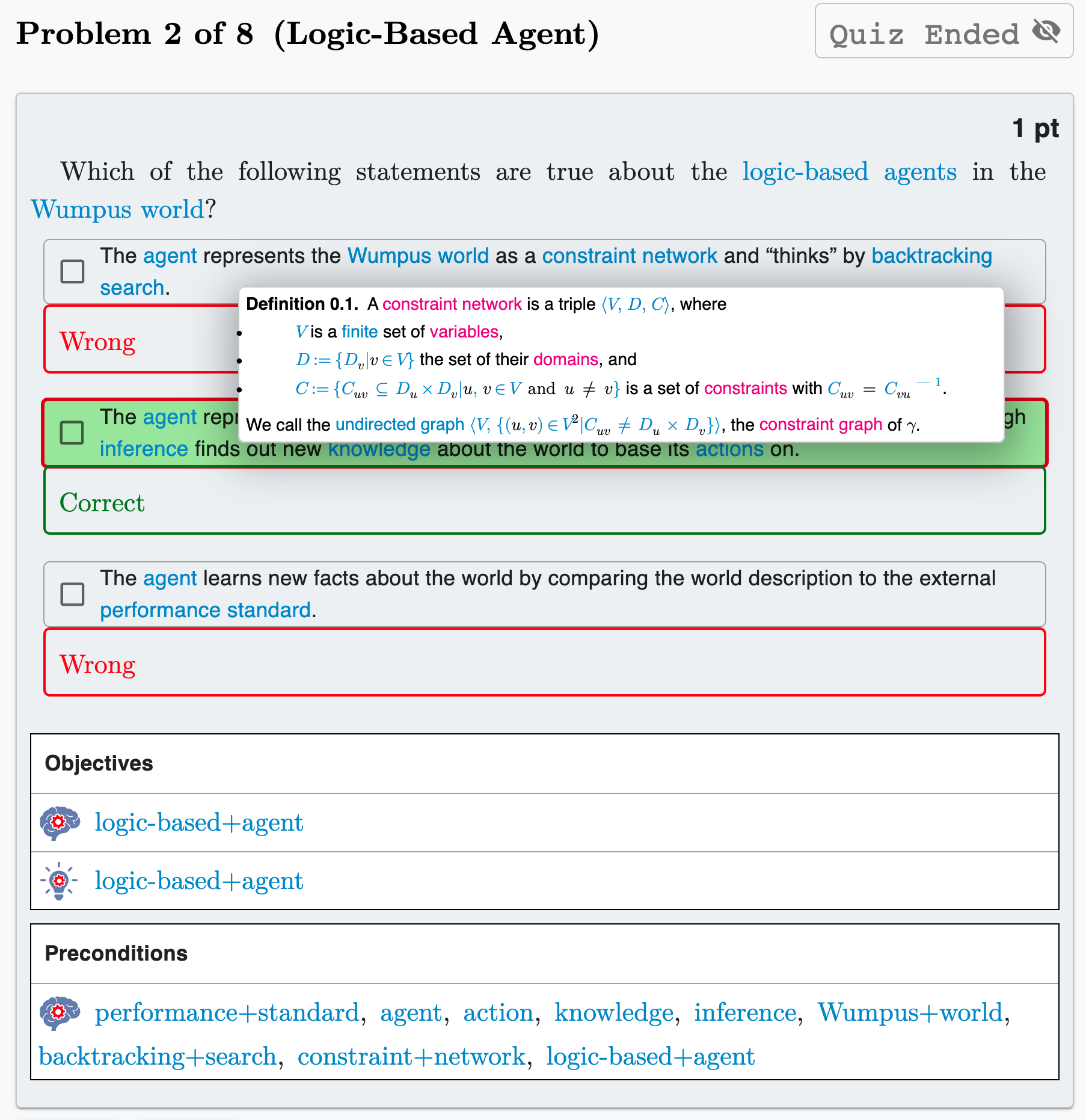
📊 实验亮点
实验结果表明,该方法在生成结构化语义标注方面表现良好,但生成的关系标注质量有待提高。生成问题的整体质量虽然有提升,但仍需人工干预以确保符合教育标准。这表明大型语言模型在教育内容生成方面具有潜力,但仍需进一步研究和改进。
🎯 应用场景
该研究成果可应用于智能教学系统、在线教育平台和个性化学习资源生成等领域。通过自动生成高质量、语义标注的学习对象,可以降低教育资源的开发成本,提高教学效率,并为学习者提供更加个性化的学习体验。未来,该技术有望应用于更广泛的学科领域,并与其他人工智能技术相结合,构建更加智能化的教育生态系统。
📄 摘要(原文)
Background: Over the past few decades, the process and methodology of automated question generation (AQG) have undergone significant transformations. Recent progress in generative natural language models has opened up new potential in the generation of educational content. Objectives: This paper explores the potential of large language models (LLMs) for generating computer science questions that are sufficiently annotated for automatic learner model updates, are fully situated in the context of a particular course, and address the cognitive dimension understand. Methods: Unlike previous attempts that might use basic methods like ChatGPT, our approach involves more targeted strategies such as retrieval-augmented generation (RAG) to produce contextually relevant and pedagogically meaningful learning objects. Results and Conclusions: Our results show that generating structural, semantic annotations works well. However, this success was not reflected in the case of relational annotations. The quality of the generated questions often did not meet educational standards, highlighting that although LLMs can contribute to the pool of learning materials, their current level of performance requires significant human intervention to refine and validate the generated content.