Monet: Mixture of Monosemantic Experts for Transformers
作者: Jungwoo Park, Young Jin Ahn, Kee-Eung Kim, Jaewoo Kang
分类: cs.AI
发布日期: 2024-12-05 (更新: 2025-06-11)
🔗 代码/项目: GITHUB
💡 一句话要点
提出Monet架构以解决大语言模型的多义性问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 稀疏字典学习 专家混合 机制可解释性 知识操作
📋 核心要点
- 现有方法在理解大型语言模型的内部计算时面临多义性问题,导致可解释性不足。
- 论文提出的Monet架构通过将稀疏字典学习融入专家混合预训练,解决了多义性带来的挑战。
- 实验结果表明,Monet架构在知识排斥性和知识操作方面表现优异,且整体性能未受影响。
📝 摘要(中文)
理解大型语言模型(LLMs)的内部计算对于使其与人类价值观对齐以及防止不良行为(如生成有毒内容)至关重要。然而,机制可解释性受到多义性的阻碍,即单个神经元对多个无关概念的响应。虽然稀疏自编码器(SAEs)试图通过稀疏字典学习来解开这些特征,但由于依赖于后验重构损失,导致LLM性能下降。为了解决这个问题,我们提出了Transformer的单义专家混合(Monet)架构,将稀疏字典学习直接融入端到端的专家混合预训练中。我们的新颖专家分解方法使每层的专家数量可扩展至262,144,同时总参数量按专家数量的平方根成比例增长。我们的分析展示了专家之间知识的相互排斥性,并展示了单个专家所封装的参数知识。此外,Monet允许在领域、语言和有毒性缓解方面进行知识操作,而不会降低整体性能。我们的透明LLM追求突显了扩大专家数量以增强机制可解释性的潜力,并直接重塑内部知识以根本调整模型行为。
🔬 方法详解
问题定义:本论文旨在解决大型语言模型中的多义性问题,现有方法如稀疏自编码器由于依赖后验重构损失,导致模型性能下降。
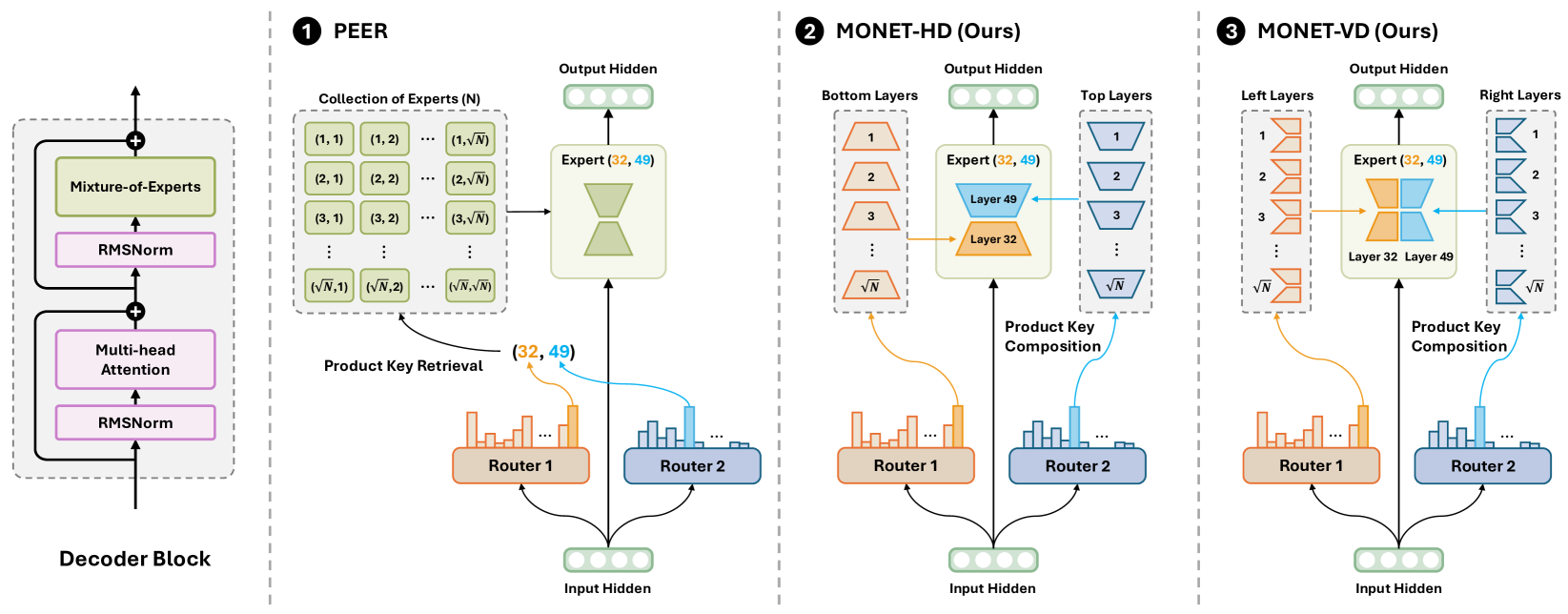
核心思路:论文提出的Monet架构通过将稀疏字典学习直接整合到Mixture-of-Experts的预训练过程中,旨在提高模型的可解释性和性能。
技术框架:Monet架构包括多个专家,每个专家专注于单一概念,允许模型在不同领域和语言间进行知识操作。整体架构支持每层高达262,144个专家,且参数量按平方根比例增长。
关键创新:最重要的技术创新在于专家的单义性分解方法,使得知识在专家之间相互排斥,显著提升了模型的可解释性和灵活性。
关键设计:在设计中,专家数量的设置和稀疏字典学习的直接整合是关键,确保了模型在处理复杂任务时的高效性与准确性。
🖼️ 关键图片


📊 实验亮点
实验结果显示,Monet架构在知识排斥性方面表现出色,能够有效地在不同领域和语言间进行知识操作,且整体性能未受影响。具体性能数据和对比基线尚未提供,未来研究可进一步验证其在实际应用中的效果。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、对话系统和内容生成等。通过提升模型的可解释性,Monet架构能够更好地对齐人类价值观,减少有害内容生成的风险,具有重要的社会价值和实际意义。
📄 摘要(原文)
Understanding the internal computations of large language models (LLMs) is crucial for aligning them with human values and preventing undesirable behaviors like toxic content generation. However, mechanistic interpretability is hindered by polysemanticity -- where individual neurons respond to multiple, unrelated concepts. While Sparse Autoencoders (SAEs) have attempted to disentangle these features through sparse dictionary learning, they have compromised LLM performance due to reliance on post-hoc reconstruction loss. To address this issue, we introduce Mixture of Monosemantic Experts for Transformers (Monet) architecture, which incorporates sparse dictionary learning directly into end-to-end Mixture-of-Experts pretraining. Our novel expert decomposition method enables scaling the expert count to 262,144 per layer while total parameters scale proportionally to the square root of the number of experts. Our analyses demonstrate mutual exclusivity of knowledge across experts and showcase the parametric knowledge encapsulated within individual experts. Moreover, Monet allows knowledge manipulation over domains, languages, and toxicity mitigation without degrading general performance. Our pursuit of transparent LLMs highlights the potential of scaling expert counts to enhance mechanistic interpretability and directly resect the internal knowledge to fundamentally adjust model behavior. The source code and pretrained checkpoints are available at https://github.com/dmis-lab/Monet.