Enhancing Mathematical Reasoning in LLMs with Background Operators
作者: Jiajun Chen, Yik-Cheung Tam
分类: cs.AI
发布日期: 2024-12-05
💡 一句话要点
利用背景算子增强大型语言模型在数学推理中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学推理 大型语言模型 Prolog 背景算子 自训练 数据增强 知识表示
📋 核心要点
- 现有LLM在复杂数学推理中表现不足,缺乏对基本数学概念和算子的有效利用。
- 提出利用Prolog和背景算子,将数学问题分解为可推理的步骤,增强LLM的推理能力。
- 通过K折交叉验证自训练,迭代生成并验证新的Prolog解决方案,显著提升模型准确率。
📝 摘要(中文)
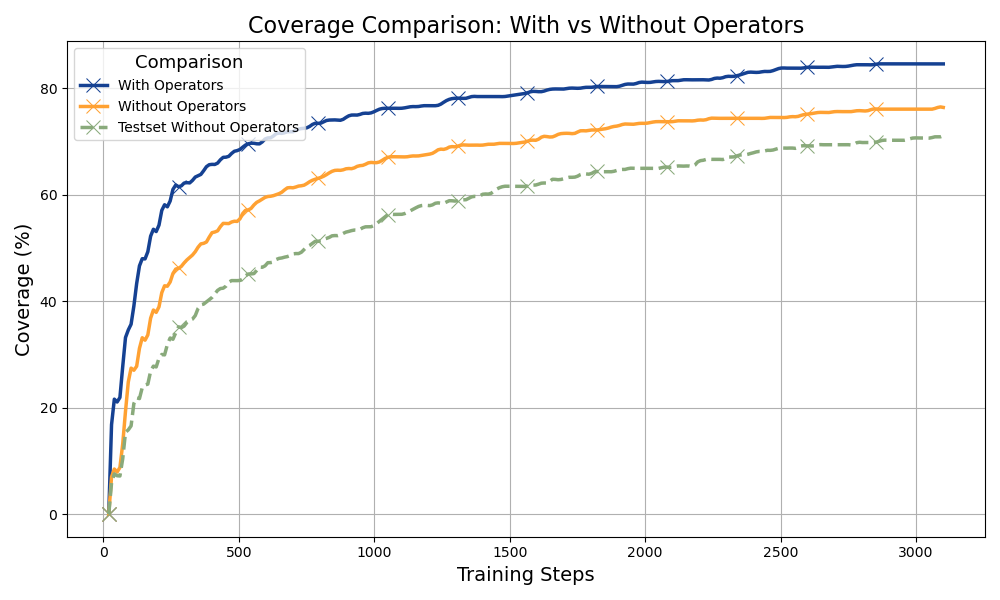
本文提出利用背景算子来增强大型语言模型(LLM)在数学推理方面的能力。为此,我们定义了一组基本的数学谓词作为构建块。对于每个数学问题,我们开发了一个Prolog解决方案,其中包括特定于问题的谓词和从这些背景算子派生的中间谓词,确保每个解决方案都符合定义的算子集。我们引入了MATH-Prolog语料库,该语料库源自MATH语料库的计数和概率类别。为了高效的数据增强,我们应用K折交叉验证自训练。这种方法为每个fold增量生成新的Prolog解决方案,并在模型训练过程中将那些验证为正确的解决方案合并到训练集中。我们的实验结果表明,5折交叉验证自训练能够有效地识别新的、准确的Prolog解决方案,在Meta-Llama-3.1-8B-Instruct模型微调期间,在交叉验证集上实现了84.6%的准确率,在测试集上实现了84.8%的准确率。这种方法成功地发现了先前未见过的问题的完全可计算推理步骤的新解决方案。此外,将背景数学谓词合并到提示中可以提高解决方案的覆盖率。
🔬 方法详解
问题定义:现有大型语言模型在解决复杂的数学问题时,往往缺乏对基本数学概念和算子的有效利用,导致推理过程不够严谨,容易出错。现有的方法难以保证推理步骤的正确性和完整性,尤其是在处理未见过的问题时,泛化能力较弱。
核心思路:本文的核心思路是将数学问题转化为Prolog程序,利用预定义的背景算子(例如加法、乘法等基本数学运算)作为构建块,将复杂的数学推理过程分解为一系列可计算的逻辑步骤。通过这种方式,可以显式地控制推理过程,并确保每一步都符合数学规则。
技术框架:整体框架包括以下几个主要阶段:1) 定义一组基本的数学谓词作为背景算子;2) 对于每个数学问题,构建一个Prolog解决方案,该方案包含问题特定的谓词和从背景算子派生的中间谓词;3) 构建MATH-Prolog语料库,该语料库源自MATH语料库;4) 应用K折交叉验证自训练,迭代生成新的Prolog解决方案,并将验证为正确的解决方案添加到训练集中;5) 使用增强后的数据集微调大型语言模型。
关键创新:最重要的技术创新点在于利用背景算子显式地表示数学知识,并将数学推理过程转化为逻辑推理过程。与传统的端到端方法相比,这种方法具有更好的可解释性和可控性。此外,K折交叉验证自训练能够有效地发现新的、准确的Prolog解决方案,从而提高模型的泛化能力。
关键设计:K折交叉验证自训练是关键设计之一。具体来说,将数据集分成K个fold,每次使用K-1个fold进行训练,剩余的1个fold进行验证。对于每个fold,模型会生成新的Prolog解决方案,并将验证为正确的解决方案添加到训练集中。这个过程迭代进行,直到模型收敛。此外,将背景数学谓词合并到提示中,可以引导模型更好地利用这些知识,从而提高解决方案的覆盖率。
🖼️ 关键图片


📊 实验亮点
实验结果表明,5折交叉验证自训练能够有效地识别新的、准确的Prolog解决方案,在Meta-Llama-3.1-8B-Instruct模型微调期间,在交叉验证集上实现了84.6%的准确率,在测试集上实现了84.8%的准确率。相比于直接使用LLM,该方法显著提升了数学推理的准确性和可靠性。
🎯 应用场景
该研究成果可应用于智能教育、自动化数学问题求解、科学计算等领域。通过将数学推理过程形式化,可以帮助学生更好地理解数学概念,并提高解决问题的能力。此外,该方法还可以用于开发更强大的数学软件和工具,从而加速科学研究和工程应用。
📄 摘要(原文)
We propose utilizing background operators for mathematical reasoning in large language models (LLMs). To achieve this, we define a set of fundamental mathematical predicates as the basic building blocks. For each mathematical problem, we develop a Prolog solution that includes problem-specific predicates and intermediate predicates derived from these background operators, ensuring that each solution adheres to the defined operator set. We introduce the MATH-Prolog corpus, which is derived from the counting and probability categories of the MATH corpus. For efficient data augmentation, we apply K-fold cross-validated self-training. This method incrementally generates new Prolog solutions for each fold, incorporating those verified as correct into the training set throughout the model training process. Our experimental results demonstrate that 5-fold crossvalidated self-training effectively identifies new, accurate Prolog solutions, achieving an accuracy of 84.6% on the cross-validated set, and 84.8% on the test set during fine-tuning the Meta-Llama-3.1-8B-Instruct model. This approach successfully uncovers new solutions with fully computable inference steps for previously unseen problems. Additionally, incorporating the background mathematical predicates into the prompt enhances solution coverage.