Pre-train, Align, and Disentangle: Empowering Sequential Recommendation with Large Language Models
作者: Yuhao Wang, Junwei Pan, Pengyue Jia, Wanyu Wang, Maolin Wang, Zhixiang Feng, Xiaotian Li, Jie Jiang, Xiangyu Zhao
分类: cs.IR, cs.AI
发布日期: 2024-12-05 (更新: 2025-04-25)
备注: accepted to SIGIR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出PAD框架,利用预训练语言模型增强序列推荐,解决冷启动和性能瓶颈。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 序列推荐 大型语言模型 预训练 对齐 解耦 冷启动 推荐系统
📋 核心要点
- 现有序列推荐方法依赖协同数据,面临冷启动和性能瓶颈等挑战。
- PAD框架通过预训练、对齐和解耦,利用LLM增强序列推荐模型,提升性能。
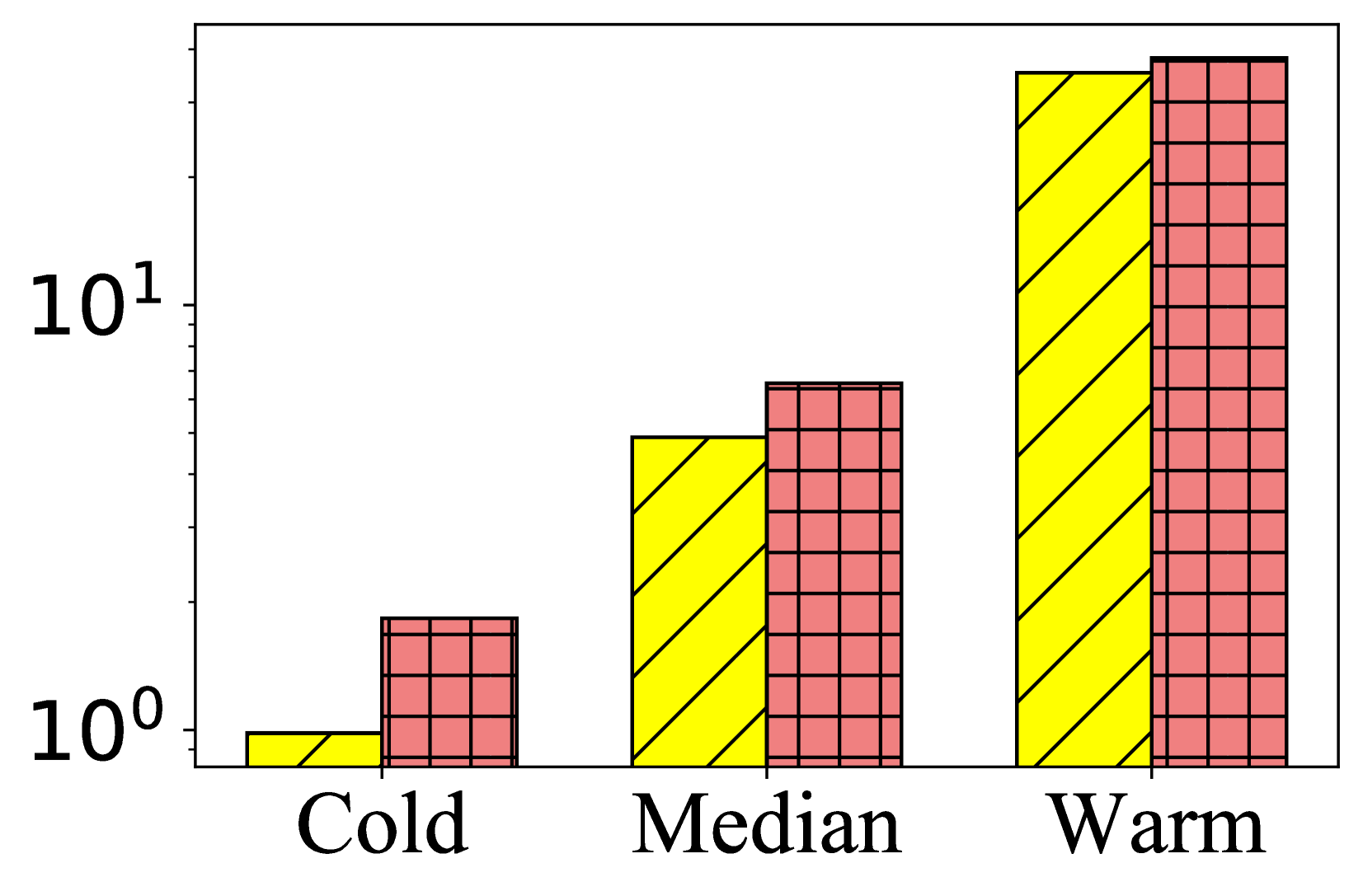
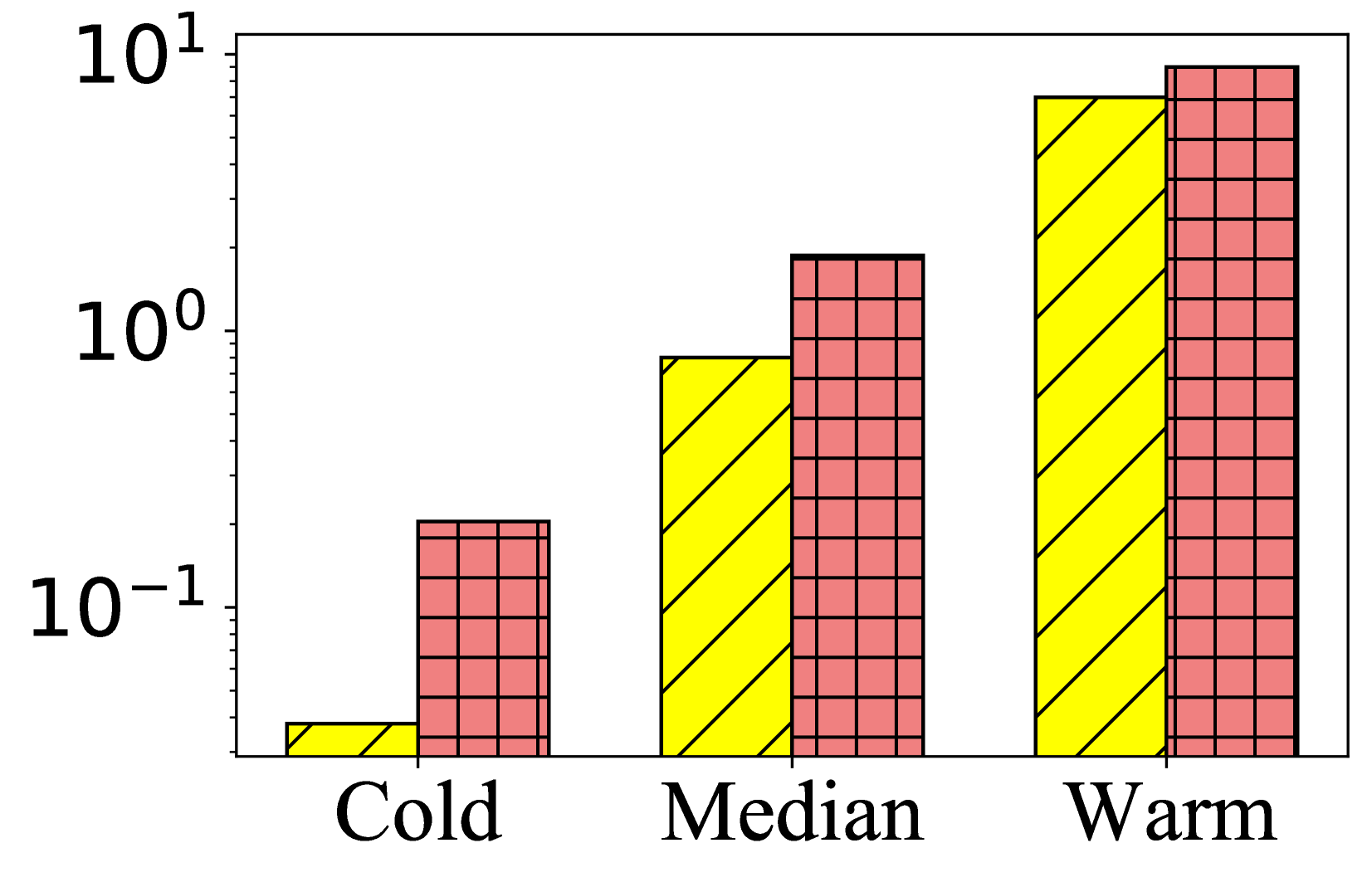
- 实验表明PAD能显著提升序列推荐效果,尤其在冷启动物品上表现突出,且兼容多种骨干模型。
📝 摘要(中文)
序列推荐旨在利用用户历史交互中的序列模式来准确追踪用户偏好。然而,现有序列推荐方法主要依赖协同数据,导致冷启动问题和次优性能。同时,尽管大型语言模型(LLM)已被证明有效,但由于推理延迟高、无法完全捕获所有分布统计信息以及灾难性遗忘等问题,它们在商业推荐系统中的集成受到阻碍。为了解决这些问题,我们提出了一种新颖的预训练、对齐和解耦(PAD)框架,以利用LLM增强序列推荐模型。具体而言,我们首先预训练序列推荐模型和LLM模型,以获得协同和文本嵌入。随后,我们提出了一种特征推荐锚定的对齐损失,该损失使用具有高斯核的多核最大均值差异。最后,一个由对齐的和模态特定的专家以及解耦嵌入组成的三重专家架构以频率感知的方式进行微调。在三个公共数据集上的实验结果验证了PAD的有效性,表明其对各种序列推荐骨干模型都有显著增强和兼容性,尤其是在冷启动物品方面。代码和数据集可在https://github.com/Applied-Machine-Learning-Lab/PAD上获取。
🔬 方法详解
问题定义:序列推荐旨在根据用户的历史交互序列预测用户未来的行为。现有方法主要依赖于协同过滤,当用户或物品交互数据稀疏时,会遇到严重的冷启动问题,导致推荐效果不佳。此外,现有方法难以有效利用文本等辅助信息,限制了模型对用户偏好的全面理解。
核心思路:PAD框架的核心思路是利用大型语言模型(LLM)强大的语义理解能力来增强序列推荐模型。通过将协同信息和文本信息融合,PAD能够更准确地捕捉用户偏好,从而缓解冷启动问题并提升推荐性能。该框架通过预训练、对齐和解耦三个阶段,逐步将LLM的知识迁移到序列推荐模型中。
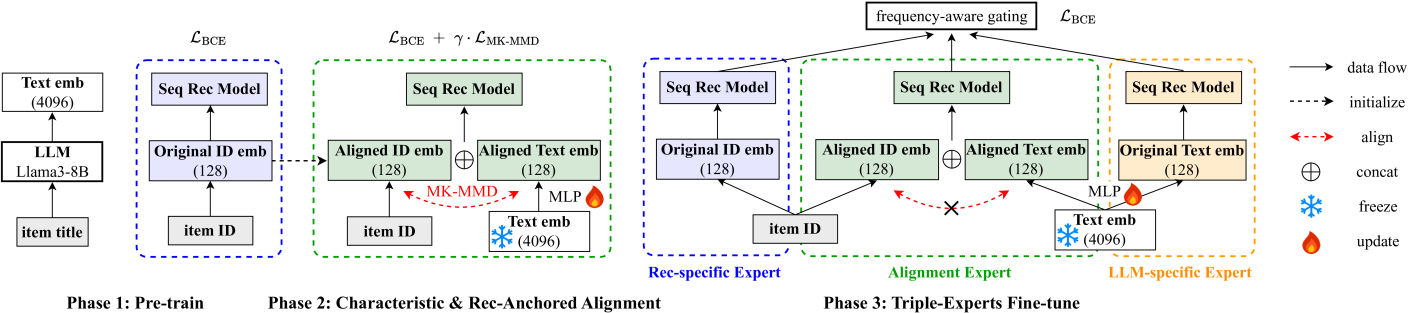
技术框架:PAD框架包含三个主要阶段:预训练、对齐和解耦。首先,分别预训练序列推荐模型和LLM,获得各自的嵌入表示。然后,通过特征推荐锚定的对齐损失,将两种嵌入空间对齐,使它们具有相似的语义表示。最后,构建一个三重专家架构,包含对齐的专家、模态特定的专家以及解耦的嵌入,并通过频率感知的方式进行微调。
关键创新:PAD框架的关键创新在于其三阶段的设计:预训练阶段利用各自的优势学习初始表示;对齐阶段通过特征推荐锚定的对齐损失,有效融合协同信息和文本信息;解耦阶段通过三重专家架构,进一步提升模型的表达能力。与现有方法相比,PAD能够更有效地利用LLM的知识,从而显著提升序列推荐的性能。
关键设计:在对齐阶段,使用了多核最大均值差异(MK-MMD)与高斯核,以更好地衡量两个嵌入空间之间的差异。特征推荐锚定的对齐损失旨在将序列推荐模型的嵌入与LLM的嵌入对齐,从而使序列推荐模型能够利用LLM的语义信息。在解耦阶段,频率感知的微调策略旨在根据物品的交互频率调整模型的学习速率,从而更好地处理长尾物品。
🖼️ 关键图片
📊 实验亮点
在三个公共数据集上的实验结果表明,PAD框架能够显著提升序列推荐的性能。尤其是在冷启动物品上,PAD的提升幅度更为明显。例如,在某个数据集上,PAD相对于基线模型提升了超过10%。此外,实验还表明PAD框架具有良好的兼容性,可以与多种序列推荐骨干模型结合使用。
🎯 应用场景
PAD框架可应用于各种电商、视频、音乐等平台的推荐系统,尤其适用于解决冷启动问题,提升用户体验。通过融合文本信息,PAD能够更准确地理解用户偏好,从而提供更个性化的推荐服务。该研究的成果有助于推动LLM在推荐系统中的应用,并为未来的研究提供新的思路。
📄 摘要(原文)
Sequential Recommendation (SR) aims to leverage the sequential patterns in users' historical interactions to accurately track their preferences. However, the primary reliance of existing SR methods on collaborative data results in challenges such as the cold-start problem and sub-optimal performance. Concurrently, despite the proven effectiveness of large language models (LLMs), their integration into commercial recommender systems is impeded by issues such as high inference latency, incomplete capture of all distribution statistics, and catastrophic forgetting. To address these issues, we introduce a novel Pre-train, Align, and Disentangle (PAD) framework to enhance SR models with LLMs. In particular, we initially pre-train both the SR and LLM models to obtain collaborative and textual embeddings. Subsequently, we propose a characteristic recommendation-anchored alignment loss using multi-kernel maximum mean discrepancy with Gaussian kernels. Lastly, a triple-experts architecture, comprising aligned and modality-specific experts with disentangled embeddings, is fine-tuned in a frequency-aware manner. Experimental results on three public datasets validate the efficacy of PAD, indicating substantial enhancements and compatibility with various SR backbone models, particularly for cold items. The code and datasets are accessible for reproduction at https://github.com/Applied-Machine-Learning-Lab/PAD.