WiS Platform: Enhancing Evaluation of LLM-Based Multi-Agent Systems Through Game-Based Analysis
作者: Chengwei Hu, Jianhui Zheng, Yancheng He, Hangyu Guo, Junguang Jiang, Han Zhu, Kai Sun, Yuning Jiang, Wenbo Su, Bo Zheng
分类: cs.AI
发布日期: 2024-12-04 (更新: 2025-06-26)
💡 一句话要点
WiS平台:通过游戏分析增强LLM多智能体系统评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 大型语言模型 评估平台 游戏分析 谁是卧底
📋 核心要点
- 现有LLM多智能体系统评估缺乏统一接口、实时反馈和全面分析,阻碍了研究进展。
- WiS平台通过“谁是卧底?”游戏,提供开放、可扩展和实时更新的评估环境。
- 实验表明,该平台能有效评估不同LLM智能体的游戏胜率、攻防策略和推理能力。
📝 摘要(中文)
基于大型语言模型(LLM)的自主多智能体系统(MAS)的最新进展,增强了应用场景,并提高了LLM处理复杂任务的能力。尽管展现出有效性,但现有研究在LLM-MAS的评估、分析和可重复性方面仍然存在明显不足。为了促进LLM-MAS的研究,本文介绍了一个开放、可扩展且实时更新的平台,用于访问和分析基于“谁是卧底?”(WiS)游戏的LLM-MAS。我们的平台具有三个主要价值:(1)统一的模型评估接口,支持Hugging Face上的可用模型;(2)实时更新的模型评估排行榜;(3)涵盖游戏胜率、攻击、防御策略和LLM推理的全面评估。为了严格测试WiS,我们对各种开源和闭源LLM进行了广泛的实验,发现不同的智能体在游戏中表现出独特而有趣的特性。实验结果证明了我们的平台在评估LLM-MAS方面的有效性和效率。我们的平台及其文档可在https://whoisspy.ai/公开获取。
🔬 方法详解
问题定义:现有基于LLM的多智能体系统(MAS)的评估缺乏统一的接口,难以支持各种模型。评估结果更新不及时,缺乏实时反馈。评估指标不够全面,难以深入分析智能体的行为和推理能力。这些问题阻碍了LLM-MAS的研究和发展。
核心思路:论文的核心思路是利用“谁是卧底?”(WiS)游戏作为评估LLM-MAS的平台。WiS游戏具有明确的规则和目标,能够有效地测试智能体的推理、沟通和协作能力。通过构建一个开放、可扩展和实时更新的平台,可以方便研究人员访问和评估各种LLM-MAS。
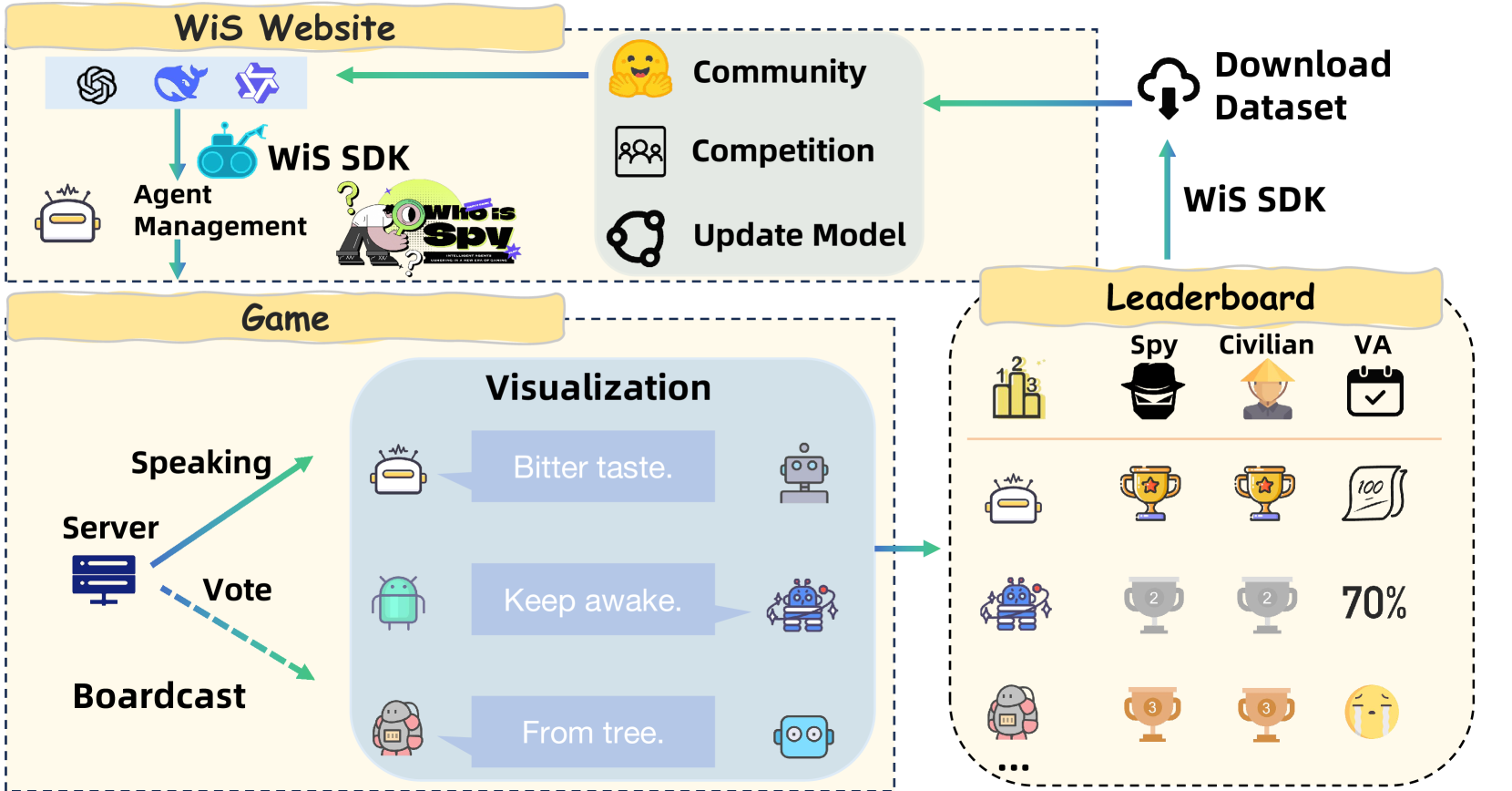
技术框架:WiS平台主要包含以下几个模块:1) 统一的模型评估接口:支持Hugging Face上的各种LLM模型,方便用户集成和测试。2) 实时更新的排行榜:根据模型在WiS游戏中的表现,实时更新排行榜,提供性能参考。3) 综合评估指标:涵盖游戏胜率、攻击策略、防御策略和LLM推理能力等多个方面,全面评估智能体的性能。4) 游戏环境:提供WiS游戏环境,支持多智能体交互和实时反馈。
关键创新:该平台的主要创新在于将WiS游戏引入LLM-MAS的评估中,提供了一个更具挑战性和趣味性的评估环境。同时,该平台提供统一的接口、实时的反馈和全面的评估指标,方便研究人员进行深入分析。
关键设计:平台采用模块化设计,方便扩展和维护。游戏环境采用实时更新机制,保证评估的公平性和准确性。评估指标的设计充分考虑了WiS游戏的特点,能够有效地反映智能体的推理、沟通和协作能力。具体参数设置和损失函数等细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
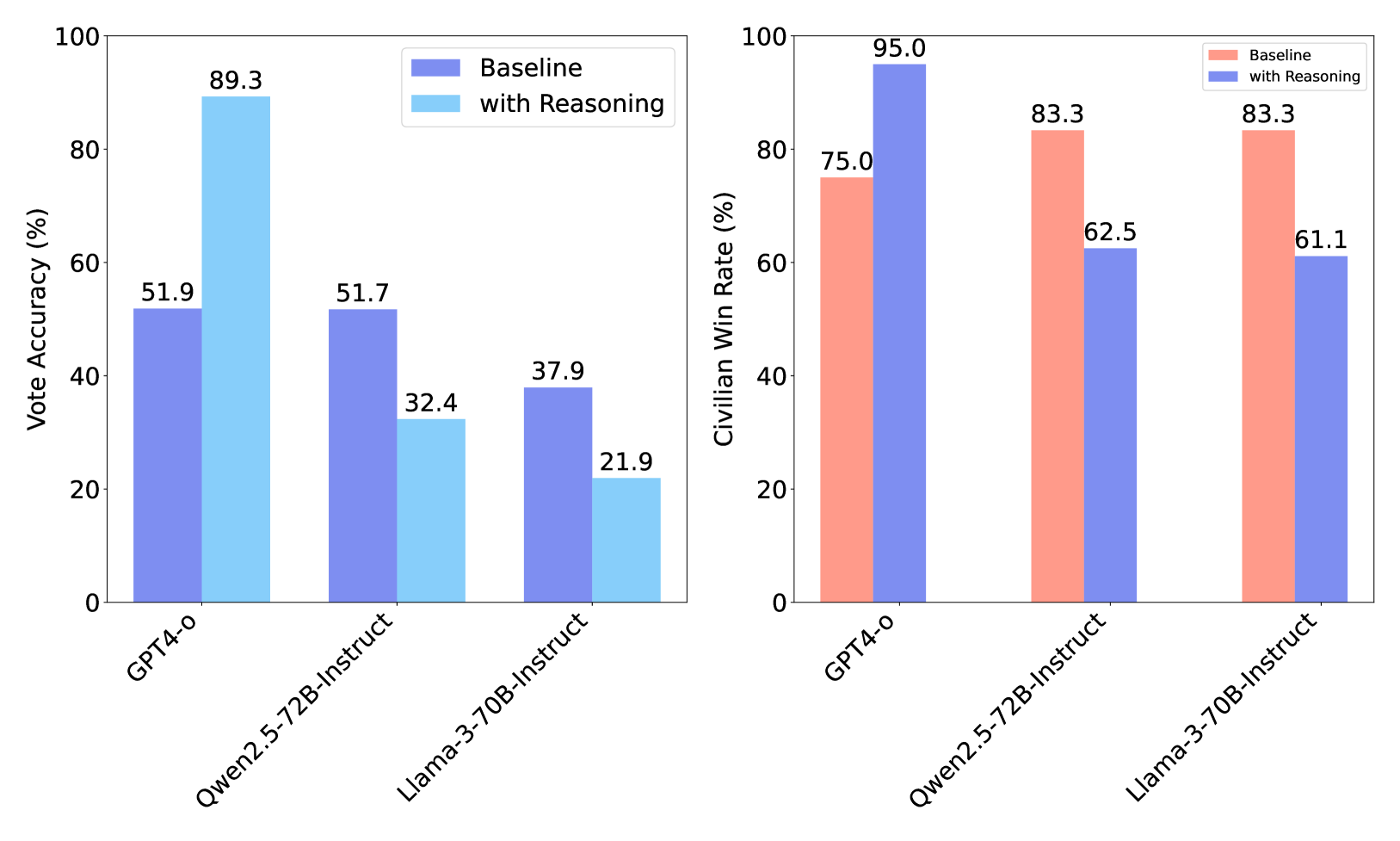
实验结果表明,WiS平台能够有效区分不同LLM智能体的性能差异,并揭示其在游戏中的独特行为模式。通过对各种开源和闭源LLM进行测试,发现不同智能体在攻击、防御和推理方面表现出显著差异,验证了该平台在评估LLM-MAS方面的有效性和效率。
🎯 应用场景
该研究成果可应用于开发更智能、更可靠的多智能体系统,例如智能客服、自动驾驶、协同机器人等。通过WiS平台,可以更好地评估和优化LLM-MAS的性能,推动人工智能技术在各个领域的应用。
📄 摘要(原文)
Recent advancements in autonomous multi-agent systems (MAS) based on large language models (LLMs) have enhanced the application scenarios and improved the capability of LLMs to handle complex tasks. Despite demonstrating effectiveness, existing studies still evidently struggle to evaluate, analysis, and reproducibility of LLM-based MAS. In this paper, to facilitate the research on LLM-based MAS, we introduce an open, scalable, and real-time updated platform for accessing and analyzing the LLM-based MAS based on the games Who is Spy?" (WiS). Our platform is featured with three main worths: (1) a unified model evaluate interface that supports models available on Hugging Face; (2) real-time updated leaderboard for model evaluation; (3) a comprehensive evaluation covering game-winning rates, attacking, defense strategies, and reasoning of LLMs. To rigorously test WiS, we conduct extensive experiments coverage of various open- and closed-source LLMs, we find that different agents exhibit distinct and intriguing behaviors in the game. The experimental results demonstrate the effectiveness and efficiency of our platform in evaluating LLM-based MAS. Our platform and its documentation are publicly available at https://whoisspy.ai/.