Does Few-Shot Learning Help LLM Performance in Code Synthesis?
作者: Derek Xu, Tong Xie, Botao Xia, Haoyu Li, Yunsheng Bai, Yizhou Sun, Wei Wang
分类: cs.SE, cs.AI, cs.CL, cs.LG
发布日期: 2024-12-03
💡 一句话要点
提出两种少样本选择方法,提升LLM在代码生成任务中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 少样本学习 提示工程 模型优化
📋 核心要点
- 现有代码生成LLM主要关注模型结构和训练,忽略了prompt中少样本示例选择的重要性。
- 论文提出CODEEXEMPLAR-FREE和CODEEXEMPLAR-BASED两种方法,用于选择更有效的少样本示例。
- 实验表明,所提方法能显著提升CodeLlama在HumanEval+基准上的代码生成能力。
📝 摘要(中文)
大型语言模型(LLM)通过改进模型设计、训练和思维链等方式,在代码生成方面取得了显著进展。然而,提示级别的优化仍然是LLM用于编码的一个重要但未被充分探索的方面。本文重点研究了大多数代码生成提示中存在的少样本示例,系统地研究了少样本示例是否能提高LLM的编码能力,哪些少样本示例影响最大,以及如何选择有影响力的示例。我们的工作提供了两种选择少样本示例的方法:一种是无模型方法CODEEXEMPLAR-FREE,另一种是基于模型的方法CODEEXEMPLAR-BASED。这两种方法在提高性能和依赖训练数据及可解释性之间提供了权衡。两种方法都显著提高了CodeLlama在流行的HumanEval+编码基准上的编码能力。总而言之,我们的工作为如何在代码生成提示中选择少样本示例以提高LLM代码生成能力提供了宝贵的见解。
🔬 方法详解
问题定义:论文旨在解决如何为代码生成任务选择最佳的少样本示例,以提升大型语言模型(LLM)的性能。现有方法通常随机选择或使用启发式方法,缺乏系统性和有效性,导致LLM无法充分利用少样本信息,影响代码生成的准确性和效率。
核心思路:论文的核心思路是设计两种不同的少样本示例选择策略:一种是无模型方法,依赖于代码本身的特征;另一种是基于模型的方法,利用LLM的预测能力来评估示例的质量。通过这两种互补的方法,可以更有效地选择出对LLM代码生成最有帮助的示例。
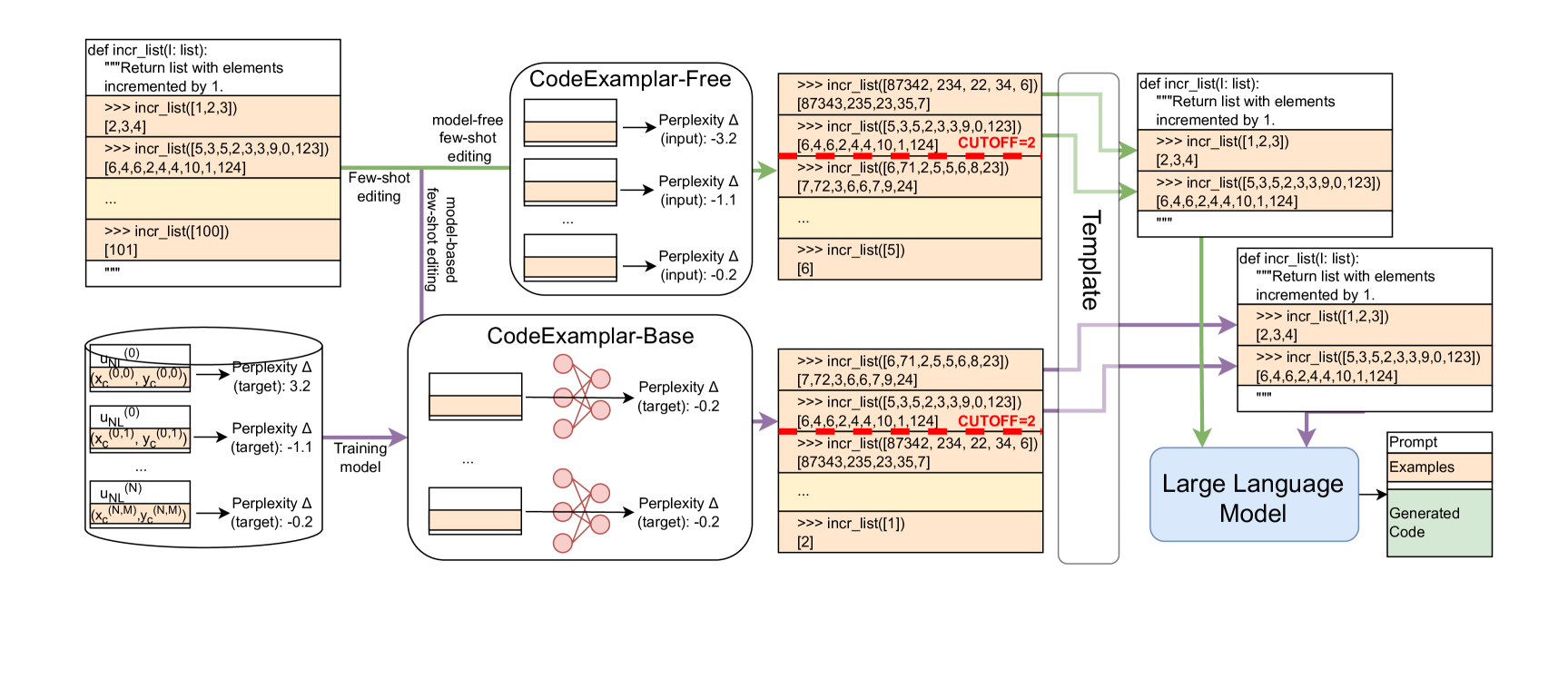
技术框架:整体框架包括两个主要模块:CODEEXEMPLAR-FREE和CODEEXEMPLAR-BASED。CODEEXEMPLAR-FREE模块首先提取代码的特征(例如代码长度、关键词等),然后基于这些特征计算示例之间的相似度,选择与目标代码最相似的示例。CODEEXEMPLAR-BASED模块则利用LLM对每个候选示例进行评估,选择那些能够最大程度提高LLM预测准确性的示例。
关键创新:论文的关键创新在于提出了两种互补的少样本示例选择方法,分别从代码特征和模型预测两个角度来评估示例的质量。CODEEXEMPLAR-FREE方法无需训练数据,具有更高的通用性;CODEEXEMPLAR-BASED方法则能够更好地利用LLM的知识,选择更具针对性的示例。与现有方法相比,这两种方法能够更有效地提升LLM的代码生成能力。
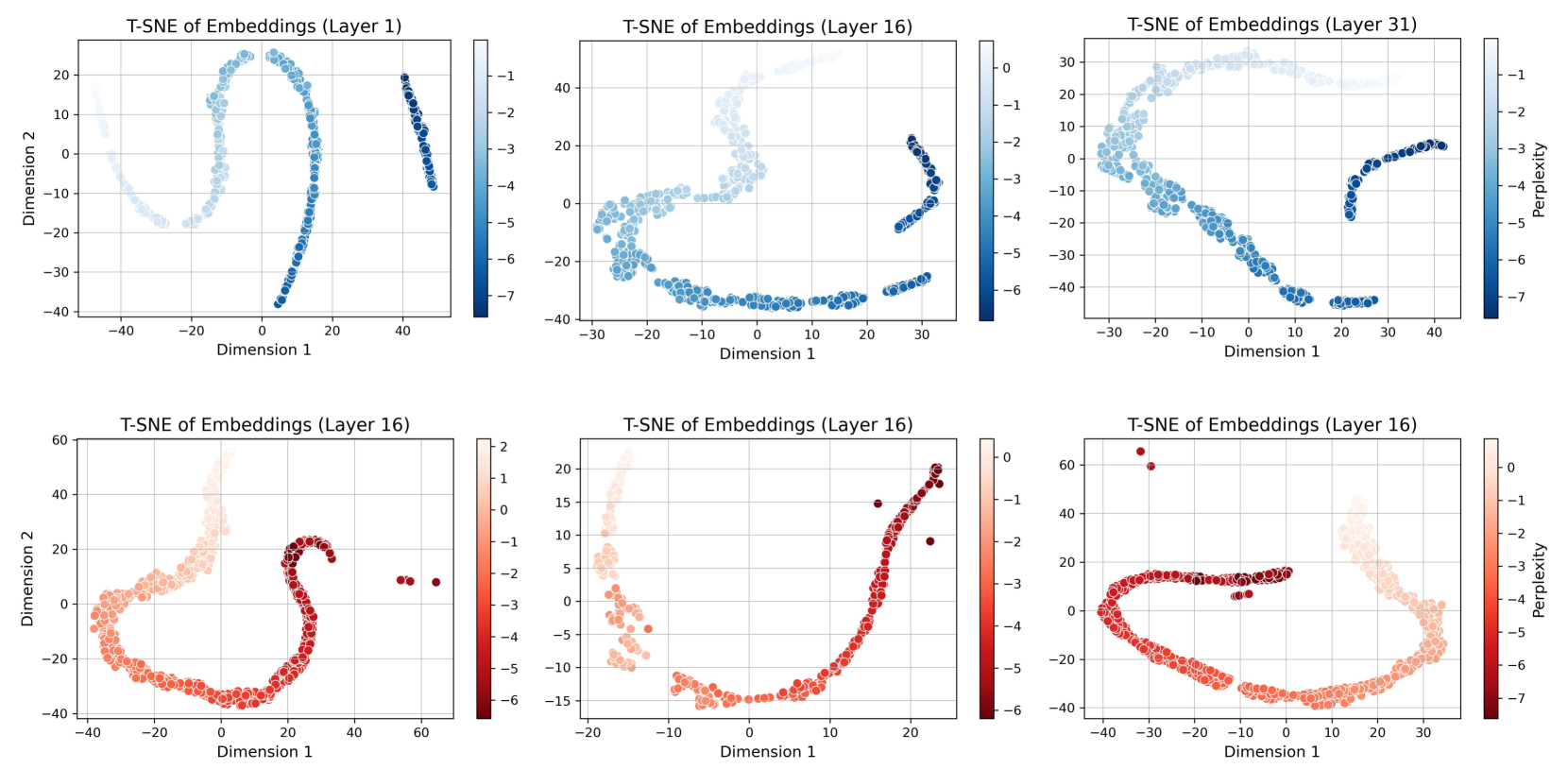
关键设计:CODEEXEMPLAR-FREE的关键设计在于代码特征的提取和相似度计算方法。CODEEXEMPLAR-BASED的关键设计在于如何利用LLM进行示例评估,例如可以使用LLM对每个示例进行代码生成,然后评估生成代码的质量。具体的参数设置和损失函数取决于所使用的LLM和代码生成任务。
🖼️ 关键图片
📊 实验亮点
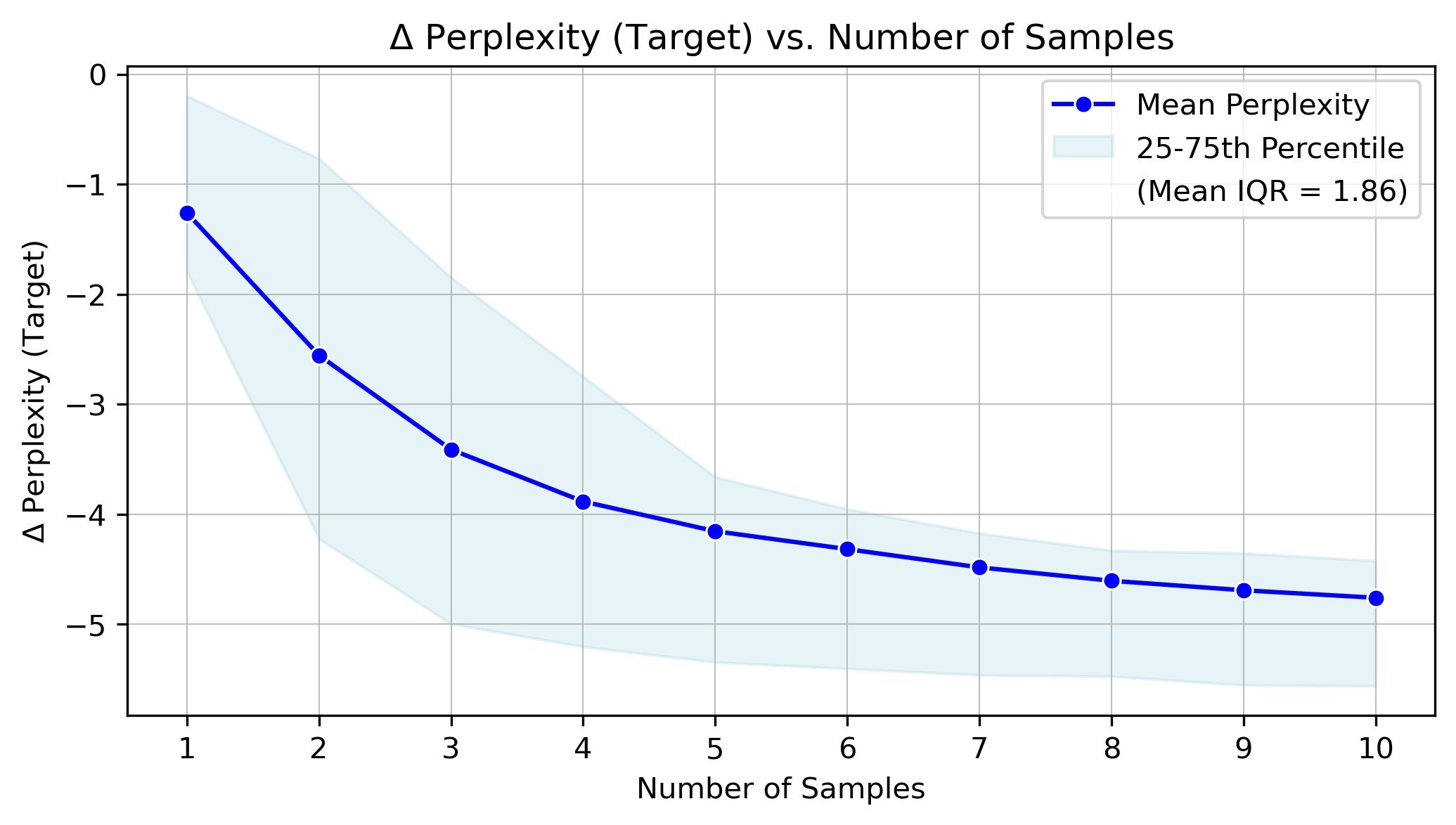
实验结果表明,CODEEXEMPLAR-FREE和CODEEXEMPLAR-BASED两种方法均能显著提升CodeLlama在HumanEval+基准上的代码生成能力。具体而言,两种方法在不同设置下均取得了优于基线方法的性能,证明了所提方法的有效性。性能提升幅度取决于具体的任务和模型,但总体趋势是显著的。
🎯 应用场景
该研究成果可广泛应用于软件开发、自动化测试、代码教育等领域。通过优化少样本示例的选择,可以显著提升LLM在代码生成任务中的性能,降低开发成本,提高开发效率。未来,该方法可以进一步扩展到其他自然语言处理任务中,例如文本摘要、机器翻译等。
📄 摘要(原文)
Large language models (LLMs) have made significant strides at code generation through improved model design, training, and chain-of-thought. However, prompt-level optimizations remain an important yet under-explored aspect of LLMs for coding. This work focuses on the few-shot examples present in most code generation prompts, offering a systematic study on whether few-shot examples improve LLM's coding capabilities, which few-shot examples have the largest impact, and how to select impactful examples. Our work offers 2 approaches for selecting few-shot examples, a model-free method, CODEEXEMPLAR-FREE, and a model-based method, CODEEXEMPLAR-BASED. The 2 methods offer a trade-off between improved performance and reliance on training data and interpretability. Both methods significantly improve CodeLlama's coding ability across the popular HumanEval+ coding benchmark. In summary, our work provides valuable insights into how to pick few-shot examples in code generation prompts to improve LLM code generation capabilities.