The Asymptotic Behavior of Attention in Transformers
作者: Álvaro Rodríguez Abella, João Pedro Silvestre, Paulo Tabuada
分类: cs.AI, cs.LG, eess.SY, math.DS, math.OC
发布日期: 2024-12-03 (更新: 2025-09-25)
💡 一句话要点
揭示Transformer深度增加时的注意力机制渐近行为,证明Token将收敛到单一簇
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 注意力机制 深度学习 控制理论 共识动力学
📋 核心要点
- 现有Transformer模型依赖增加深度来提升性能,但收益递减且可能导致模型崩溃,即Token收敛到单一簇。
- 该论文利用控制理论工具,包括流形上的共识动力学和输入-状态稳定性,分析Transformer深度增加时的Token收敛行为。
- 证明了Transformer中的所有Token随着深度的增加会渐近地收敛到一个簇,并推广到自回归模型。
📝 摘要(中文)
Transformer架构已成为现代大型语言模型(LLM)的基础,但其理论性质仍未被充分理解。与经典神经网络一样,改进这些模型的常见方法是增加其大小和深度。然而,这种策略可能并非最优,因为一些研究表明,增加更多层会产生越来越少的收益。更重要的是,先前的研究表明,增加深度可能导致模型崩溃,即所有token收敛到单个簇,从而削弱了LLM生成多样化输出的能力。基于Transformer动态的微分方程模型,我们证明了Transformer中的所有token随着深度的增加会渐近地收敛到一个簇。在技术层面上,我们利用了控制理论的工具,包括流形上的共识动力学和输入-状态稳定性(ISS)。然后,我们利用自回归模型的结构,将其分析扩展到自回归模型,以进一步推广理论保证。
🔬 方法详解
问题定义:论文旨在解决Transformer模型深度增加时,注意力机制的渐近行为问题。现有方法通过简单地增加模型深度来提升性能,但存在收益递减和模型崩溃的风险,即所有token收敛到单一簇,导致生成多样性降低。因此,需要从理论上分析深度对Transformer行为的影响,为模型设计提供指导。
核心思路:论文的核心思路是利用控制理论中的工具,特别是流形上的共识动力学和输入-状态稳定性(ISS),来分析Transformer的动态行为。通过将Transformer的注意力机制建模为动态系统,可以研究其在深度增加时的渐近行为,从而揭示Token收敛的根本原因。
技术框架:论文首先将Transformer的注意力机制建模为微分方程。然后,利用控制理论中的共识动力学和ISS理论,分析该微分方程的解的渐近行为。具体来说,论文证明了在一定条件下,所有token的状态会随着深度的增加而收敛到一个共同的状态,即形成一个簇。最后,论文将该分析扩展到自回归模型,进一步推广了理论结果。
关键创新:论文的关键创新在于将控制理论的工具应用于分析Transformer的注意力机制。这种方法提供了一种新的视角来理解Transformer的动态行为,并为解决模型崩溃问题提供了理论基础。与以往的研究主要关注经验观察不同,该论文提供了严格的数学证明,为Transformer的理论研究做出了重要贡献。
关键设计:论文的关键设计包括:1) 将Transformer的注意力机制建模为微分方程;2) 利用共识动力学和ISS理论分析该微分方程的解;3) 针对自回归模型,利用其结构特点进一步推广理论结果。具体的参数设置和网络结构依赖于Transformer的具体实现,但论文的分析框架具有通用性,可以应用于不同的Transformer变体。
🖼️ 关键图片
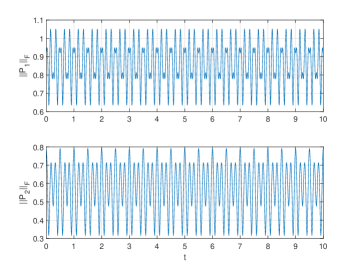
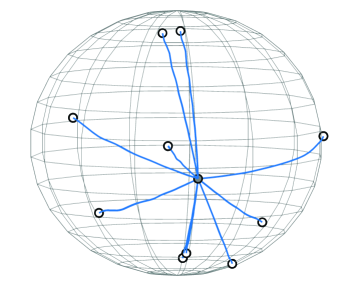
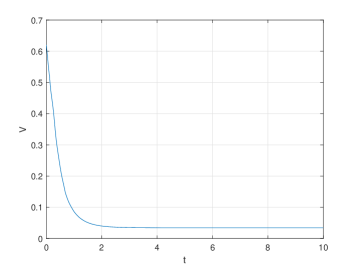
📊 实验亮点
论文通过理论分析证明了Transformer模型中,随着深度增加,所有token会渐近收敛到单一簇,解释了模型崩溃现象。该结论基于严格的数学推导,并推广到自回归模型,为Transformer的理论研究提供了重要依据。
🎯 应用场景
该研究成果可应用于大型语言模型的优化设计,通过控制模型深度和注意力机制,避免模型崩溃,提高生成文本的多样性和质量。此外,该研究也为理解其他基于注意力机制的深度学习模型的行为提供了理论基础,具有广泛的应用前景。
📄 摘要(原文)
The transformer architecture has become the foundation of modern Large Language Models (LLMs), yet its theoretical properties are still not well understood. As with classic neural networks, a common approach to improve these models is to increase their size and depth. However, such strategies may be suboptimal, as several works have shown that adding more layers yields increasingly diminishing returns. More importantly, prior studies have shown that increasing depth may lead to model collapse, i.e., all the tokens converge to a single cluster, undermining the ability of LLMs to generate diverse outputs. Building on differential equation models for the transformer dynamics, we prove that all the tokens in a transformer asymptotically converge to a cluster as depth increases. At the technical level we leverage tools from control theory, including consensus dynamics on manifolds and input-to-state stability (ISS). We then extend our analysis to autoregressive models, exploiting their structure to further generalize the theoretical guarantees.