ScImage: How Good Are Multimodal Large Language Models at Scientific Text-to-Image Generation?
作者: Leixin Zhang, Steffen Eger, Yinjie Cheng, Weihe Zhai, Jonas Belouadi, Christoph Leiter, Simone Paolo Ponzetto, Fahimeh Moafian, Zhixue Zhao
分类: cs.AI, cs.CL, cs.CV
发布日期: 2024-12-03
💡 一句话要点
ScImage:评估多模态大语言模型在科学文本到图像生成任务中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 科学图像生成 文本到图像 评估基准 空间理解 数值理解 属性理解 ScImage
📋 核心要点
- 现有方法在科学图像生成领域缺乏针对性的评估基准,难以衡量多模态大语言模型在此任务中的真实能力。
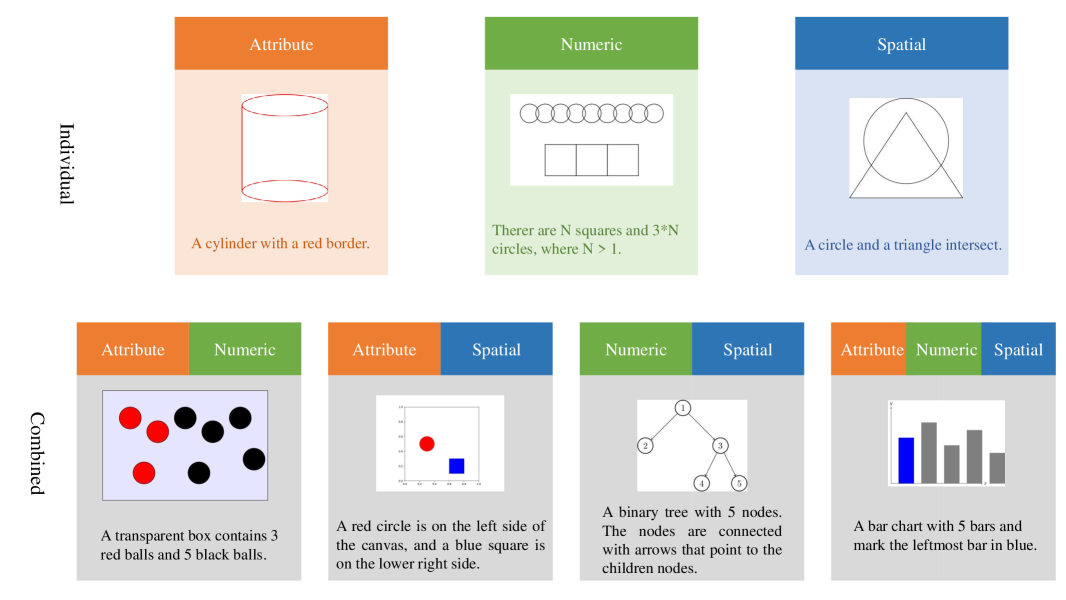
- 论文提出ScImage基准,专注于空间、数值和属性理解三个关键维度,并考察它们在科学对象关系理解中的组合。
- 实验结果表明,尽管GPT-4o在简单提示下表现尚可,但所有模型在处理复杂科学图像生成任务时均面临挑战。
📝 摘要(中文)
多模态大语言模型(LLM)在从文本指令生成高质量图像方面表现出令人印象深刻的能力。然而,它们在生成科学图像方面的性能——这是加速科学进步的关键应用——仍未得到充分探索。本文通过引入ScImage来弥补这一差距,ScImage是一个旨在评估LLM在从文本描述生成科学图像方面的多模态能力的基准。ScImage评估了理解的三个关键维度:空间、数值和属性理解,以及它们的组合,重点关注科学对象(例如,正方形、圆形)之间的关系。我们使用两种输出生成模式:基于代码的输出(Python、TikZ)和直接栅格图像生成,评估了五个模型,GPT-4o、Llama、AutomaTikZ、Dall-E和StableDiffusion。此外,我们还研究了四种不同的输入语言:英语、德语、波斯语和中文。我们由11位科学家根据三个标准(正确性、相关性和科学准确性)进行的评估表明,虽然GPT-4o对于涉及空间、数值或属性理解等单个维度的更简单提示产生了质量不错的输出,但所有模型在这项任务中都面临挑战,特别是对于更复杂的提示。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(LLM)在科学文本到图像生成任务中的性能评估问题。现有方法缺乏专门针对科学图像生成的评估基准,无法有效衡量LLM在此领域的真实能力。现有方法难以评估模型对空间关系、数值信息和属性特征的综合理解能力,以及它们在科学图像中的组合应用能力。
核心思路:论文的核心思路是构建一个专门用于评估LLM生成科学图像能力的基准数据集ScImage。该基准侧重于评估模型对科学图像中关键要素的理解,包括空间关系(例如,对象的位置和排列)、数值信息(例如,对象的数量和大小)以及属性特征(例如,对象的颜色和形状)。通过设计包含不同难度级别的提示,可以全面评估模型在不同场景下的性能。
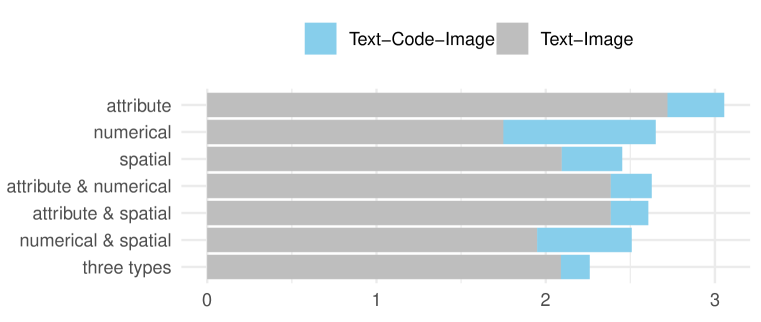
技术框架:ScImage基准包含一系列文本提示,这些提示描述了需要生成的科学图像。这些提示涵盖了空间、数值和属性理解的各个方面,以及它们的组合。评估过程包括使用LLM生成图像,然后由领域专家根据正确性、相关性和科学准确性三个标准对生成的图像进行评估。论文使用了两种输出生成模式:基于代码的输出(Python, TikZ)和直接栅格图像生成。
关键创新:ScImage基准的主要创新在于其专注于评估LLM在科学图像生成方面的能力。与通用图像生成基准不同,ScImage专门设计用于评估模型对科学图像中关键要素的理解,例如空间关系、数值信息和属性特征。此外,ScImage还考虑了不同输入语言的影响,并提供了多种评估指标,从而可以更全面地评估模型的性能。
关键设计:ScImage基准的关键设计包括:1) 提示的多样性,涵盖了空间、数值和属性理解的各个方面;2) 评估指标的科学性,包括正确性、相关性和科学准确性;3) 输出生成模式的多样性,包括基于代码的输出和直接栅格图像生成;4) 输入语言的多样性,包括英语、德语、波斯语和中文。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GPT-4o在处理简单的科学图像生成任务时表现出一定的能力,但在处理涉及空间、数值和属性组合的复杂任务时,所有模型都面临挑战。例如,在生成包含多个对象且对象之间存在复杂空间关系的图像时,模型的准确性和相关性显著下降。此外,不同输入语言也会影响模型的性能,表明模型在跨语言理解方面仍有提升空间。
🎯 应用场景
该研究成果可应用于科学研究、教育和出版等领域。通过提高LLM生成科学图像的质量和准确性,可以加速科学发现、改善科学教育,并促进科学知识的传播。例如,研究人员可以使用LLM自动生成实验结果的可视化图表,教师可以使用LLM生成教学用的科学插图,出版商可以使用LLM生成科学书籍的配图。
📄 摘要(原文)
Multimodal large language models (LLMs) have demonstrated impressive capabilities in generating high-quality images from textual instructions. However, their performance in generating scientific images--a critical application for accelerating scientific progress--remains underexplored. In this work, we address this gap by introducing ScImage, a benchmark designed to evaluate the multimodal capabilities of LLMs in generating scientific images from textual descriptions. ScImage assesses three key dimensions of understanding: spatial, numeric, and attribute comprehension, as well as their combinations, focusing on the relationships between scientific objects (e.g., squares, circles). We evaluate five models, GPT-4o, Llama, AutomaTikZ, Dall-E, and StableDiffusion, using two modes of output generation: code-based outputs (Python, TikZ) and direct raster image generation. Additionally, we examine four different input languages: English, German, Farsi, and Chinese. Our evaluation, conducted with 11 scientists across three criteria (correctness, relevance, and scientific accuracy), reveals that while GPT-4o produces outputs of decent quality for simpler prompts involving individual dimensions such as spatial, numeric, or attribute understanding in isolation, all models face challenges in this task, especially for more complex prompts.